21 World Values Survey
Uno de los temas clásicos de los estudios internacionales ha sido estudiar la diferencia de valores entre varias sociedades. ¿En qué lugar del mundo tienen los valores más seculares? ¿Y dónde tienen valores más tradicionales? ¿En qué países se encuentran las sociedades más religiosas? ¿Dónde se valoran mejor las instituciones internacionales como las Naciones Unidas? Con el objetivo de responder estas y otras preguntas surgió el World Values Survey (WVS) (Inglehart et al., 2020), un programa internacional de investigación dedicado al estudio científico de los valores sociales, políticos, culturales, económicos y religiosos de todo el mundo.
Su instrumento principal de investigación es una encuesta representativa comparada que se lleva a cabo cada cinco años e incluye preguntas relacionadas con múltiples disciplinas de investigación, como pueden ser la sociología, la ciencia política, las relaciones internacionales, la economía, la salud pública, la demografía, la psicología social y un largo etcétera. Además, la WVS ha sido durante años el único estudio académico que cubría de manera amplia el planeta, puesto que ha hecho encuestas tanto en los países más desarrollados y ricos como en aquellos más pobres, capturando así las variaciones culturales del mundo.
21.1 Descargar y explorar los datos
La WVS tiene un motor propio de análisis en línea, que puede ser muy útil para navegar de forma exploratoria por sus oleadas, los países donde han hecho las encuestas y las preguntas que han realizado. Para entrar, hay que ir al apartado Online Analysis, dentro de la sección “Data and Documentation” de su página web. Para utilizar los datos tendremos que seleccionar:
- La oleada de la encuesta (2017-2022, por ejemplo).
- Los países de los cuales queremos datos.
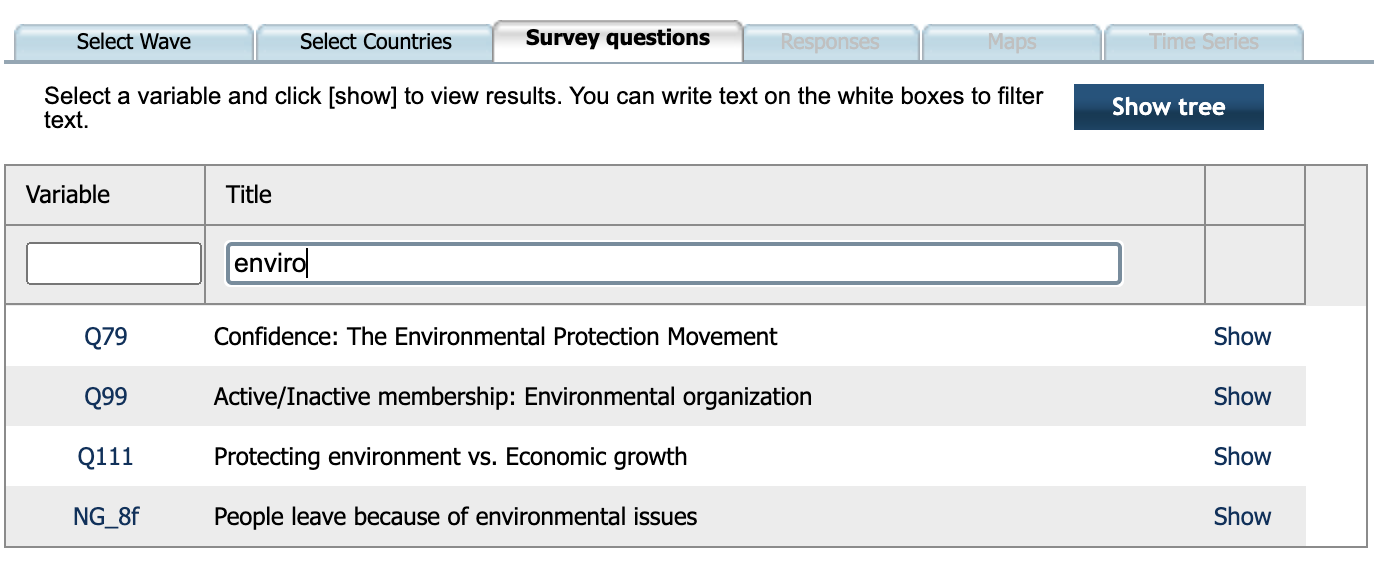
- Las variables. En este campo, podemos empezar a teclear algún nombre en inglés (por ejemplo, “Enviro…”) y un desplegable nos mostrará todas las variables que coinciden con el nombre.
La otra opción, que se explica en detalle en este módulo, es descargarse los datos a través del apartado Data Download. En el mismo desplegable de la izquierda, seleccionaremos a continuación Time Series (1981-2022) y nos llevará a una página que contiene toda la documentación. Una vez dentro, podemos descargarnos los ficheros que necesitamos:
- En la sección Codebook & Results, descargaremos toda la documentación. En particular, WVS Time Series List of Variables and equivalences 1981 2022 v3.1 (Excel), donde se encuentra la descripción de todas las variables.
- En la sección Longitudinal Data Files (véase la imagen de la derecha), haremos clic en el enlace de
WVS TimeSeries 1981 2022 Rds v4.0 zip, que queda hacia la parte final de la página web1.
1 hemos optado por la descarga del fichero en rds porque es uno de los formatos que permite reducir de forma más considerable el peso de la información que utilizaremos.
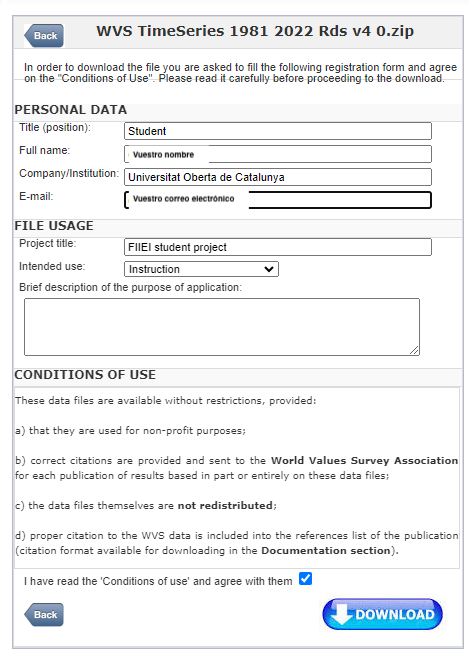
Esto nos llevará a una nueva página que nos pide los motivos de la descarga. Simplemente hace falta que pongamos nuestros datos y las razones por las cuales queremos utilizar los datos. Podéis rellenarlo de la forma siguiente y en Brief descripcion, indicar “Undergraduate course assignment at UOC”:
Una vez superado este trámite, descargaremos un fichero .zip que contiene un fichero .rds llamado wvs_TimeSeries_4_0.rds, que es donde hay todos los datos que utilizaremos. Ubicaremos este fichero en el directorio de trabajo y lo cargaremos con la función read_rds() del paquete readr junto con los otros paquetes que necesitaremos (Wickham, François, et al., 2023; Wickham, Hester, et al., 2023; Wickham et al., 2024):
Recuerda que para utilizar un paquete, este tiene que estar previamente instalado en RStudio. Si no has instalado alguno de estos paquetes, ahora es el momento de hacerlo:
install.packages(c("dplyr", "readr", "ggplot2"))wvs <- read_rds("WVS_TimeSeries_4_0.rds")El archivo ocupa más de 70 Mb, por lo cual es posible que este proceso tarde algo más de lo que estamos acostumbrados.
21.2 Exploración de los datos
La base de datos longitudinal de la WVS contiene datos de encuesta desde 1981 hasta la actualidad en varios países del mundo. En la versión descargada para realizar este módulo tutorial, vemos que el marco de datos tiene 450.869 observaciones y 1.045 variables. Lo obtenemos tecleando wvs. Esto significa que, en total, a lo largo de los años la WVS ha entrevistado a casi medio millón de personas de todo el mundo, puesto que cada observación es una entrevista.
En estos conjuntos de datos tan descomunales, una buena opción es limitar el número de columnas de los datos con los corchetes y, acto seguido, utilizar la función glimpse() para ver el listado de las primeras columnas del marco de datos. En este ejemplo, hemos reducido los datos a 20 columnas.
glimpse(wvs[, 1:20])
## Rows: 450,869
## Columns: 20
## $ version <chr> "4-0-0", "4-0-0", "4-0-0", "4-0-0", "4-0-0", "4-0-0", "4…
## $ doi <chr> "doi:10.14281/18241.22", "doi:10.14281/18241.22", "doi:1…
## $ S002VS <dbl+lbl> 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4…
## $ S003 <dbl+lbl> 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8…
## $ COUNTRY_ALPHA <chr> "ALB", "ALB", "ALB", "ALB", "ALB", "ALB", "ALB", "ALB", …
## $ COW_NUM <dbl+lbl> 339, 339, 339, 339, 339, 339, 339, 339, 339, 339, 33…
## $ COW_ALPHA <chr> "ALB", "ALB", "ALB", "ALB", "ALB", "ALB", "ALB", "ALB", …
## $ S004 <dbl+lbl> -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, …
## $ S006 <dbl+lbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, …
## $ S007 <dbl+lbl> 80420001, 80420002, 80420003, 80420004, 80420005, 80…
## $ S008 <dbl+lbl> -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, …
## $ mode <dbl+lbl> 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6…
## $ S010 <dbl+lbl> 60, 64, 75, 75, 90, 140, 130, 60, 130, 60, 6…
## $ S011A <dbl+lbl> -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, …
## $ S011B <dbl+lbl> 10.30, 10.50, 14.35, 15.20, 17.00, 12.20, 10.00, 19.…
## $ S012 <dbl+lbl> -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, …
## $ S013 <dbl+lbl> 2, 3, 3, 1, 2, 3, 1, 1, 2, 2, 1, 3, 3, 1, 3, 2, 3, 1…
## $ S013B <dbl+lbl> -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, …
## $ S016 <dbl+lbl> 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, …
## $ S016B <dbl+lbl> 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 10…Fijémonos en algunos elementos de los datos:
- En la variable
S002VSaparece la oleada de la encuesta. Observamos que hay siete valores y cada uno de ellos corresponde a una de las oleadas. Por lo tanto, si queremos obtener los datos de la primera oleada (1981-1984), tendremos que filtrar el marco de datos por el valor 1.
unique(wvs$S002VS)
## <labelled<double>[7]>: Chronology of EVS-WVS waves
## [1] 4 3 6 5 7 2 1
##
## Labels:
## value label
## 1 1981-1984
## 2 1989-1993
## 3 1994-1998
## 4 1999-2004
## 5 2005-2009
## 6 2010-2014
## 7 2017-2022- En la variable
COUNTRY_ALPHAaparece el país. Concount()podemos pedir un recuento de cuántas observaciones tenemos de cada país y oleada. Y si las ordenamos (con el argumentosort = T), encontramos que la encuesta más grande se dio en Colombia, correspondiendo a la tercera oleada de la WVS, con 6.025 entrevistados.
count(wvs, COUNTRY_ALPHA, S002VS, sort = T)
## # A tibble: 310 × 3
## COUNTRY_ALPHA S002VS n
## <chr> <dbl+lbl> <int>
## 1 COL 3 [1994-1998] 6025
## 2 IND 6 [2010-2014] 4078
## 3 CAN 7 [2017-2022] 4018
## 4 ZAF 6 [2010-2014] 3531
## 5 TUR 4 [1999-2004] 3401
## 6 IDN 7 [2017-2022] 3200
## 7 EGY 5 [2005-2009] 3051
## 8 CHN 7 [2017-2022] 3036
## 9 COL 5 [2005-2009] 3025
## 10 EGY 4 [1999-2004] 3000
## # ℹ 300 more rows- Encontramos otras variables, como
S010, que indica el total de minutos que duró la encuesta, oS016, que indica el código de idioma en el que se hizo la encuesta. Para conocer el significado de estas variables, tendremos que consultar el libro de códigos, que se encuentra en uno de los archivos de Excel que nos hemos descargado previamente.
21.3 Orientación en la WVS
Todas las variables que nos pueden resultar interesantes de la WVS están situadas más allá de la vigésima variable del marco de datos que acabamos de observar. Como hay una cantidad de información tan grande, será mucho más eficiente para nosotros si nos acostumbramos a no visualizar directamente el marco de datos en la pantalla y utilizamos uno de los archivos de Excel que nos hemos descargado previamente:
- WVS Time Series List of Variables and equivalences 1981 2022 v3.1 (Excel)
En esta hoja de Excel encontramos todas las preguntas que se han hecho en la WVS, sea cual sea la oleada. Por ejemplo, podemos querer examinar qué diferencias hay en la confianza hacia los otros que tienen las sociedades. Si buscamos ‘Trust’ en el Excel, vemos cómo un ítem de la encuesta corresponde a: Most people can be trusted y tiene el código de variable A165. Además, aparece en todas las oleadas de la encuesta, como podemos observar en el hecho de que está referenciada en las otras columnas (WVS7, WVS6, WVS5, etc.). En cambio, la siguiente pregunta Do you think most people try to take advantage of you? solo aparece a la WVS6 y a la WVS4.

Para conocer más detalles sobre cualquier variable, podemos consultar sus categorías con unique().
unique(wvs$A165)
## <labelled<double>[5]>: Most people can be trusted
## [1] 2 -1 1 -2 -4
##
## Labels:
## value label
## -5 Missing: other
## -4 Not asked
## -2 No answer
## -1 Don't know
## 1 Most people can be trusted
## 2 Need to be very carefulEn este resultado, observamos cómo se dan dos opciones de respuesta: los encuestados pueden responder que “se puede confiar en la mayoría de las personas” (most people can be trusted), asignado al valor 1. O bien que “hay que tener mucho cuidado” (need to be very careful), asignado al valor 2.
También podemos inspeccionar los detalles de la variable, así como la pregunta concreta de la encuesta, en la herramienta de análisis online. Tendremos que hacer lo siguiente:
- Accedemos a la herramienta online.
- Seleccionamos una oleada y un país cualquiera.
- En el buscador, buscamos por ejemplo ‘trust’ y nos aparecerá la variable.
- Clicamos en ‘Show’.
En la página que nos aparecerá, veremos en la parte inferior la pregunta concreta.

Una vez recogida toda la información de corte operacional de la variable, procederemos a eliminar los valores negativos de la variable. Para ello:
- Pediremos que conserve los valores que sean superiores a 0 (por lo tanto, que elimine todos los valores negativos y conserve solo los positivos).
- Crearemos un nuevo objeto,
wvs_A165.
wvs_A165 <- wvs |>
filter(A165 > 0) |>
select(COUNTRY_ALPHA, S002VS, A165)
wvs_A165
## # A tibble: 432,975 × 3
## COUNTRY_ALPHA S002VS A165
## <chr> <dbl+lbl> <dbl+lbl>
## 1 ALB 4 [1999-2004] 2 [Need to be very careful]
## 2 ALB 4 [1999-2004] 2 [Need to be very careful]
## 3 ALB 4 [1999-2004] 2 [Need to be very careful]
## 4 ALB 4 [1999-2004] 1 [Most people can be trusted]
## 5 ALB 4 [1999-2004] 2 [Need to be very careful]
## 6 ALB 4 [1999-2004] 2 [Need to be very careful]
## 7 ALB 4 [1999-2004] 2 [Need to be very careful]
## 8 ALB 4 [1999-2004] 2 [Need to be very careful]
## 9 ALB 4 [1999-2004] 2 [Need to be very careful]
## 10 ALB 4 [1999-2004] 2 [Need to be very careful]
## # ℹ 432,965 more rowsEl marco de datos wvs_A165 contiene todas las respuestas que, a lo largo del tiempo, han dado los ciudadanos de todos los países a la pregunta sobre el nivel de confianza hacia las otras personas (A165). Hemos conservado, también, la variable de la oleada (S002VS).
21.4 Comparación entre países (Y)
Una manera de hacer comparaciones de respuesta entre países es con un diagrama de barras. Cada barra será un país diferente, mientras que la altura de las barras marcará el número de personas que han dado una determinada respuesta. Para diferenciar entre respuestas, pintaremos las barras de diferente color.
Si cogemos el marco de datos anterior, wvs_A165, aplicaremos el código siguiente:
- Indicamos en qué oleada queremos hacer la comparación. Hemos marcado la 4 (1999-2004).
- Indicamos qué países queremos comparar (hemos elegido Argentina, Japón y España).
- Ubicamos la variable
COUNTRY_ALPHAen el eje de las \(x\) y también indicamos que rellene (fill) las barras según los diferentes valores que toma la variableA165. - La geometría será un diagrama de barras (
geom_bar()).
wvs_A165 |>
filter(S002VS == 4) |>
filter(COUNTRY_ALPHA %in% c("ARG", "JPN", "ESP")) |>
ggplot(aes(x = COUNTRY_ALPHA, fill = as.character(A165))) +
geom_bar()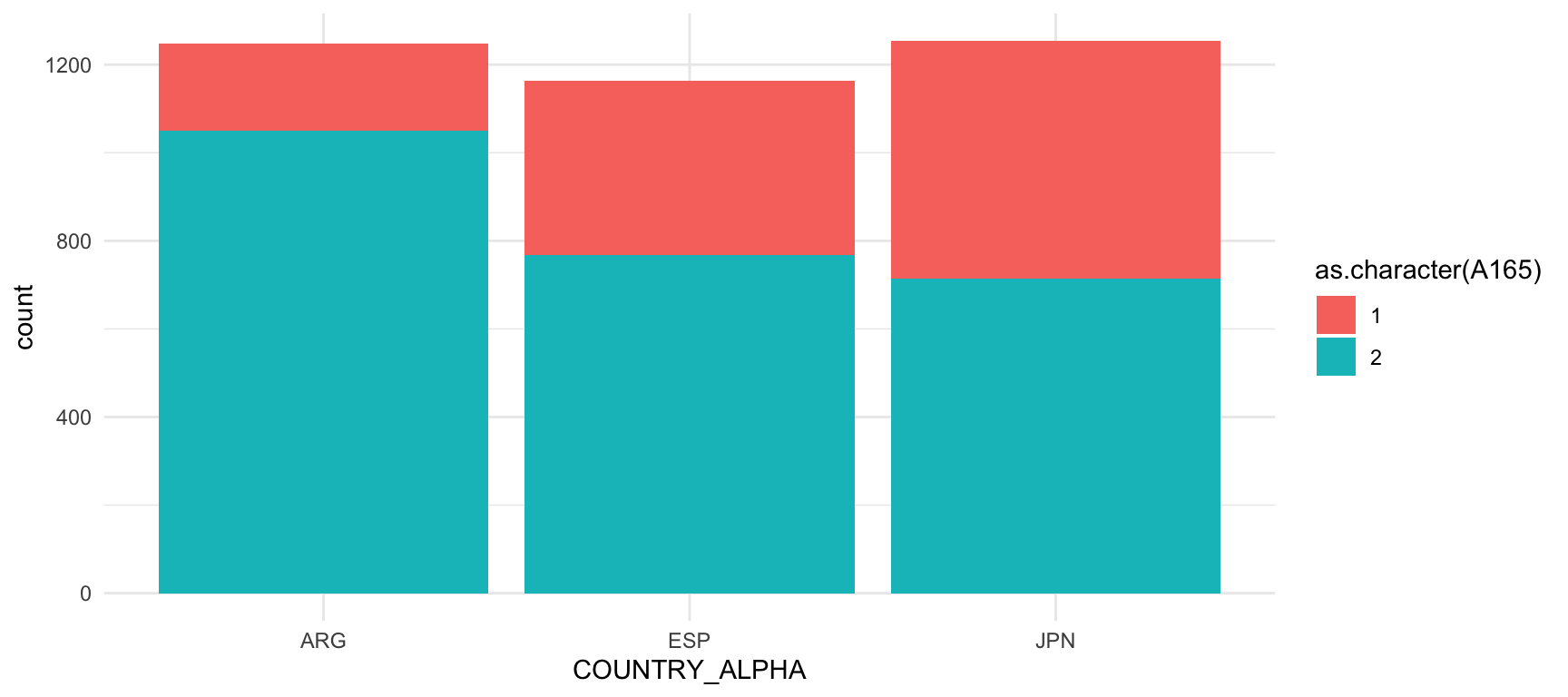
En la cuarta oleada de la WVS, se entrevistaron aproximadamente a unas 1.200 personas, tanto en Argentina, como en España y Japón. Más de 1.000 argentinos respondieron que hay que tener cuidado con las personas, mientras que en España respondieron en el mismo sentido unas 800 personas y en Japón, menos de 800. En general, parece que las personas son más desconfiadas en Argentina que en España o Japón.
Habitualmente, no nos interesará tanto el número de personas que hayan respondido, sino el porcentaje de personas que hayan tomado una opción u otra. Por eso haremos una pequeña modificación en el código anterior, indicando position = "fill" dentro de la función geom_bar().
wvs_A165 |>
filter(S002VS == 4) |>
filter(COUNTRY_ALPHA %in% c("ARG", "JPN", "ESP")) |>
ggplot(aes(x = COUNTRY_ALPHA, fill = as.character(A165))) +
geom_bar(position = "fill")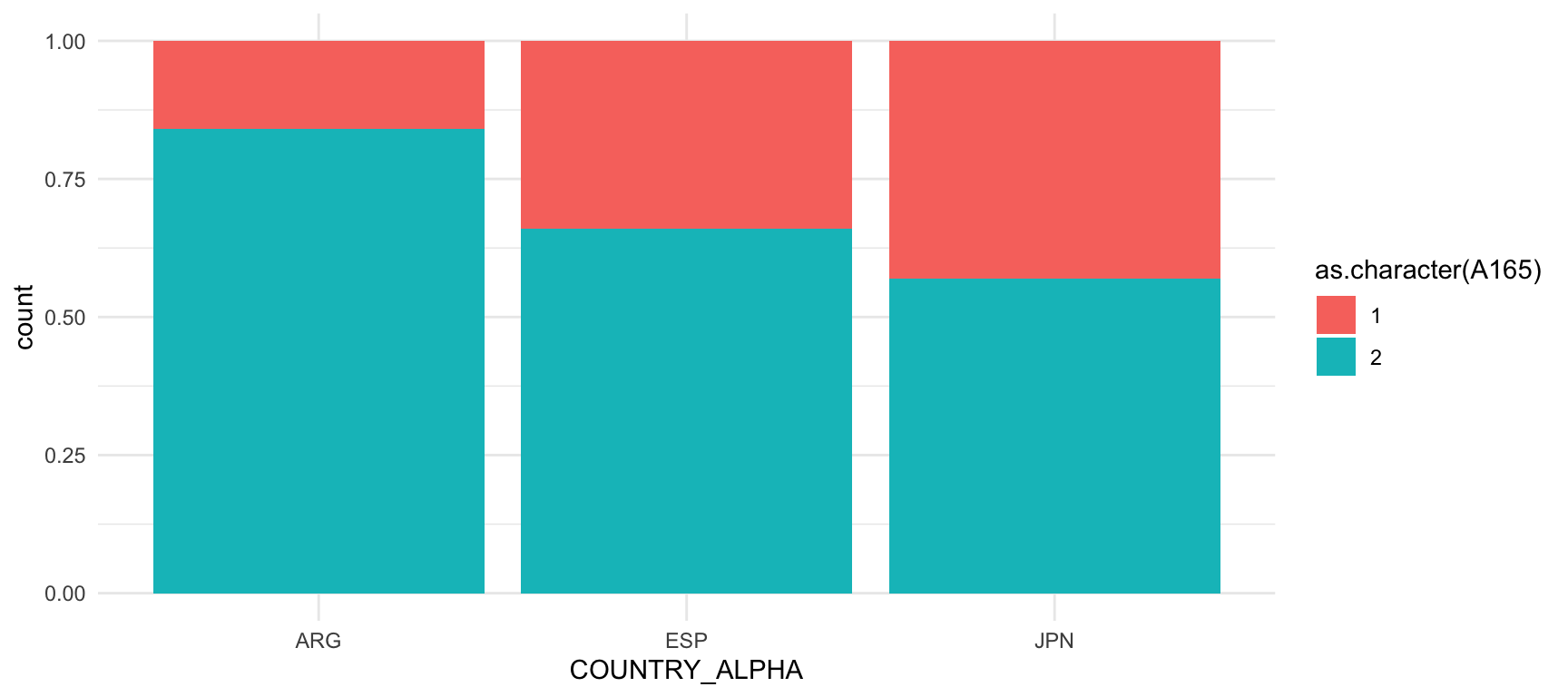
Observamos que, en Argentina, un 80% de los entrevistados declararon que hay que tener cuidado con las personas, mientras que un 20% respondieron que se puede confiar en la mayoría de la gente. En España desconfían de la gente cerca de un 70% de los encuestados, mientras que en Japón cerca de un 60%.
Repite el mismo proceso que hemos hecho, pero eligiendo otra variable y otros países. Para hacer esto, solo hace falta que cambies las ? por la variable y los países que quieras.
wvs_???? <- wvs |>
filter(????? > 0) |>
select(COUNTRY_ALPHA, S002VS, ????)
wvs_??? |>
filter(S002VS == ????) |>
filter(COUNTRY_ALPHA %in% c("???", "???", "???")) |>
ggplot(aes(x = COUNTRY_ALPHA, fill = as.character(???))) +
geom_bar(position = "fill")21.5 Comparación entre países (II)
Veamos otro ejemplo, pero con variables que, en lugar de dos categorías, tienen más. Podríamos usar el mismo código anterior, pero comprobaremos que el resultado no será visualmente tan satisfactorio. Otra opción es la que proponemos a continuación. Cogemos de ejemplo la variable del grado de satisfacción con la situación financiera, que si nos fijamos en el Excel vemos que tiene como código C006. A continuación, observamos las respuestas de la variable con unique().
unique(wvs$C006)
## <labelled<double>[14]>: Satisfaction with financial situation of household
## [1] 4 7 8 3 5 10 6 1 2 9 -1 -2 -4 -5
##
## Labels:
## value label
## -5 Missing; Unknown
## -4 Not asked
## -2 No answer
## -1 Don't know
## 1 Dissatisfied
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
## 7 7
## 8 8
## 9 9
## 10 SatisfiedEn este caso, es una variable que va del 1 (nada satisfecho) al 10 (muy satisfecho). Para eliminar los valores negativos haremos exactamente el mismo procedimiento que antes. En este código, hemos creado el objeto wvs_C006 que contiene la variable país (COUNTRY_ALPHA), la variable de la oleada (S002VS) y la variable de interés (C006).
wvs_C006 <- wvs |>
filter(C006 > 0) |>
select(COUNTRY_ALPHA, S002VS, C006)
wvs_C006
## # A tibble: 435,694 × 3
## COUNTRY_ALPHA S002VS C006
## <chr> <dbl+lbl> <dbl+lbl>
## 1 ALB 4 [1999-2004] 4 [4]
## 2 ALB 4 [1999-2004] 4 [4]
## 3 ALB 4 [1999-2004] 7 [7]
## 4 ALB 4 [1999-2004] 8 [8]
## 5 ALB 4 [1999-2004] 3 [3]
## 6 ALB 4 [1999-2004] 5 [5]
## 7 ALB 4 [1999-2004] 5 [5]
## 8 ALB 4 [1999-2004] 4 [4]
## 9 ALB 4 [1999-2004] 4 [4]
## 10 ALB 4 [1999-2004] 10 [Satisfied]
## # ℹ 435,684 more rowsPara visualizar la distribución entre países, también utilizaremos el diagrama de barras, pero con algunos pequeños cambios:
- En primer lugar, filtramos por la oleada (4) y por los países de Argentina y Japón.
- En el eje de las \(x\) ubicaremos la variable, mientras que rellenaremos las barras según el país.
- Pediremos un diagrama de barras (
geom_bar) con el atributoposition = "dodge".
wvs_C006 |>
filter(S002VS == 4) |>
filter(COUNTRY_ALPHA %in% c("ARG", "JPN")) |>
ggplot(aes(x = C006, fill = COUNTRY_ALPHA)) +
geom_bar(position = "dodge")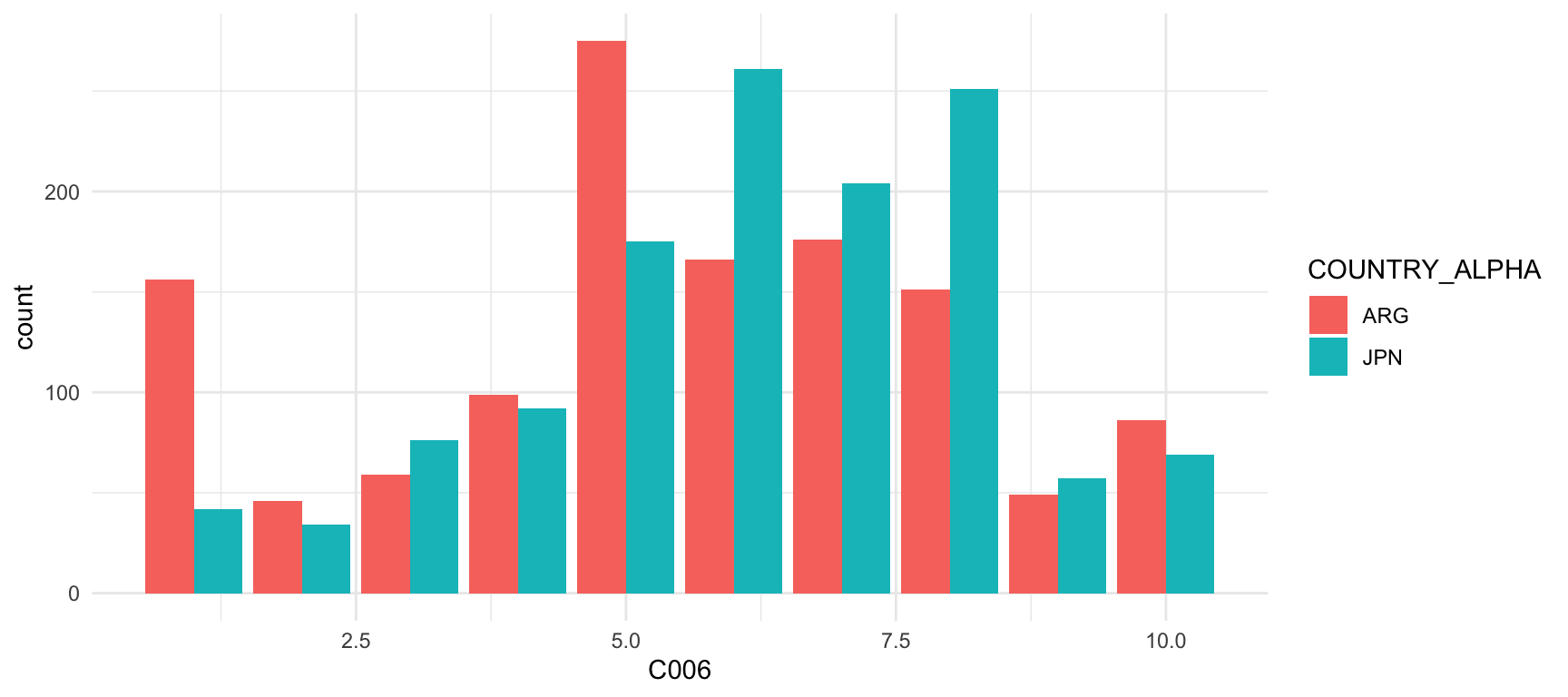
En este gráfico, observamos el grado de satisfacción con la situación financiera en el hogar en Argentina y Japón hacia el año 2000, siendo 10 el valor máximo y 1 el valor mínimo. Observamos que en general los argentinos estaban más descontentos con su situación financiera, en comparación con los japoneses.
Repite el mismo proceso que hemos hecho, pero eligiendo otra variable y otros países. Para hacer esto, solo hace falta que cambies las ? por la variable y los países que quieras.
wvs_???? <- wvs |>
filter(????? > 0) |>
select(COUNTRY_ALPHA, S002VS, ????)
wvs_??? |>
filter(S002VS == ????) |>
filter(COUNTRY_ALPHA %in% c("???", "???")) |>
ggplot(aes(x = ???, fill = COUNTRY_ALPHA)) +
geom_bar(position = "dodge")21.6 Comparación temporal
En lugar de hacer una comparación entre países en una oleada concreta, la otra opción es ver cómo han evolucionado los valores a lo largo del tiempo. En este caso, la mejor manera para ver la evolución de unos datos en el tiempo es el diagrama de líneas. Una cuestión importante que se tiene que tener en cuenta es seleccionar alguna pregunta que tenga una cierta longitud temporal y que se haya preguntado a lo largo de varias oleadas de la WVS. Por ejemplo, la variable E018 pregunta si el respeto por la autoridad es positivo o negativo.
Fijémonos en la variable. Oscila entre 1 y 3.
unique(wvs$E018)
## <labelled<double>[7]>: Future changes: Greater respect for authority
## [1] 2 1 3 -1 -2 -5 -4
##
## Labels:
## value label
## -5 Missing; Not available
## -4 Not asked
## -2 No answer
## -1 Don't know
## 1 Good thing
## 2 Don't mind
## 3 Bad thingNuevamente, eliminaremos los valores negativos. En este código, hemos creado el objeto wvs_E018, que contiene la variable país (COUNTRY_ALPHA), la variable de la oleada (S002VS) y la variable de interés (E018).
wvs_E018 <- wvs |>
filter(E018 > 0) |>
select(COUNTRY_ALPHA, S002VS, E018)
wvs_E018
## # A tibble: 427,155 × 3
## COUNTRY_ALPHA S002VS E018
## <chr> <dbl+lbl> <dbl+lbl>
## 1 ALB 4 [1999-2004] 2 [Don't mind]
## 2 ALB 4 [1999-2004] 2 [Don't mind]
## 3 ALB 4 [1999-2004] 2 [Don't mind]
## 4 ALB 4 [1999-2004] 2 [Don't mind]
## 5 ALB 4 [1999-2004] 2 [Don't mind]
## 6 ALB 4 [1999-2004] 1 [Good thing]
## 7 ALB 4 [1999-2004] 1 [Good thing]
## 8 ALB 4 [1999-2004] 1 [Good thing]
## 9 ALB 4 [1999-2004] 2 [Don't mind]
## 10 ALB 4 [1999-2004] 2 [Don't mind]
## # ℹ 427,145 more rowsEn este código:
- Cogemos los países.
- Agrupamos los datos por país y oleada.
- Pedimos la media, de forma que obtendremos los datos de la media por país u oleada.
- Pondremos \(x\) oleada y \(y\) la media y habrá una línea de un color diferente para cada país.
- Marcamos la geometría
geom_line().
wvs_E018 |>
filter(COUNTRY_ALPHA %in% c("ARG", "JPN", "ESP")) |>
group_by(COUNTRY_ALPHA, S002VS) |>
summarize(mean = mean(E018, na.rm = T)) |>
ggplot(aes(x = S002VS, y = mean, col = COUNTRY_ALPHA)) +
geom_line()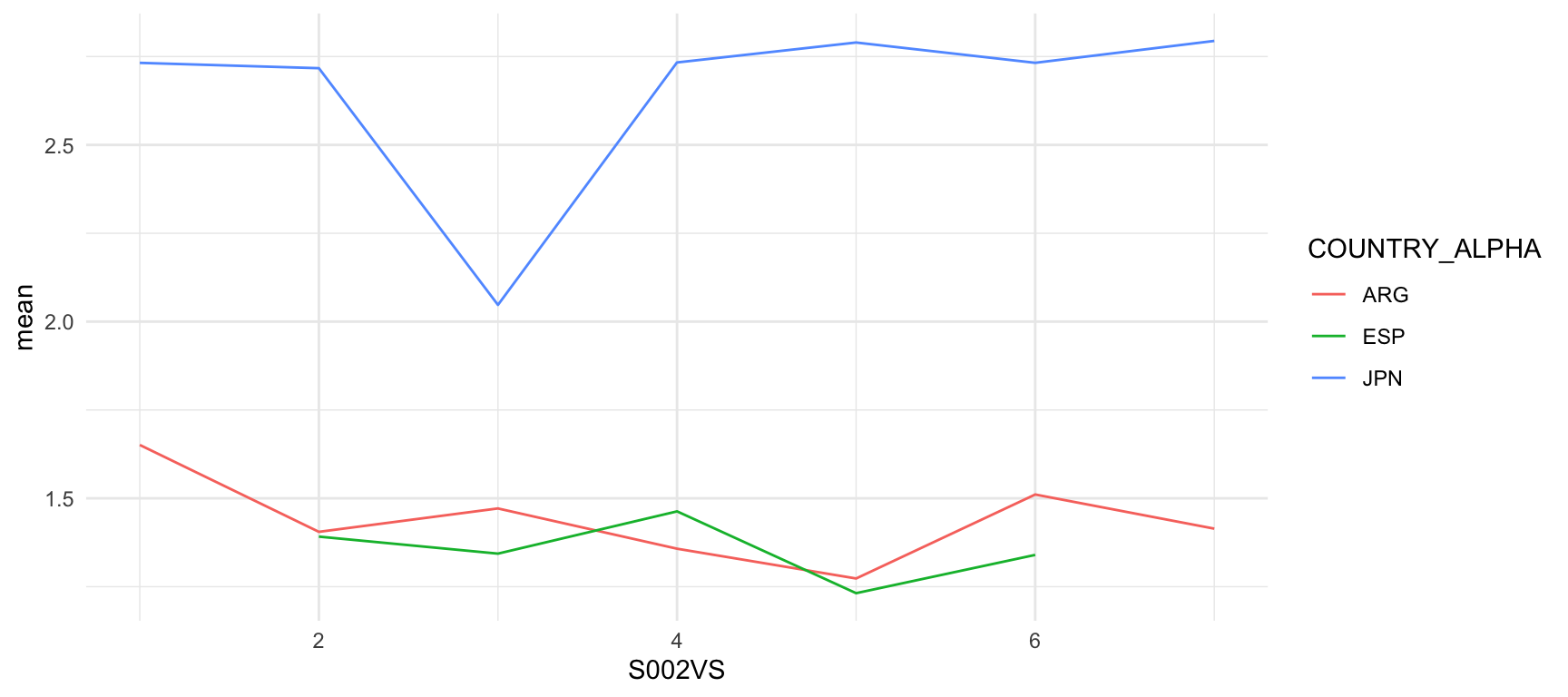
Repite el mismo proceso que hemos hecho, pero eligiendo otra variable y otros países. Para hacer esto, solo hace falta que cambies las ? por la variable y los países que quieras.
wvs_???? <- wvs |>
filter(????? > 0) |>
select(COUNTRY_ALPHA, S002VS, ????)
wvs_???? |>
filter(COUNTRY_ALPHA %in% c("???", "???", "???")) |>
group_by(COUNTRY_ALPHA, S002VS) |>
summarize(mean = mean(???, na.rm = T)) |>
ggplot(aes(x = S002VS, y = mean, col = COUNTRY_ALPHA)) +
geom_line()