17 SDR Data
17.1 Introducción
En este módulo trabajaremos con los datos de los Objetivos de Desarrollo Sostenible (ODS). Los ODS son unos objetivos presentados y evaluados por las Naciones Unidas, que inciden en muchos contextos y materias relacionadas con el desarrollo, como el medio ambiente y la sostenibilidad. Estos objetivos se clasifican en 17 categorías y más de un centenar de indicadores.
Más allá de su relevancia política, la cuantificación de muchas facetas del desarrollo puede ser relevante para analizar las diferencias existentes entre países a través de la variedad de indicadores. Este es el propósito de esta sección.

17.2 Bajar y explorar los datos con Excel
Hay muchas maneras de trabajar con los ODS, puesto que se encuentran disponibles en múltiples páginas. Una opción es utilizar alguna de las organizaciones que trabajan con estos datos, como el SDG Transformation Center que lidera el economista Jeffrey Sachs. En la página web de este centro encontraremos informes y también los datos actualizados de cada año. A nosotros nos interesa descargarnos los indicadores, que están disponibles en formato Excel. Para descargarlos, seguiremos esta ruta:
- Entraremos en la edición de 2023 en su página web.
- En la parte inferior de la página, buscaremos la pestaña “Resources”.
- Clicaremos el botón “Download Data”.
Alternativamente, también puedes descargar el último informe en la sección de descargas de la web Sustainable Development Report. Solo hay que clicar en “Acces full database”.
Los datos se descargan con un archivo de nombre SDR2023-data.xlsx o similar. Abriremos este archivo con Excel o Google Spreadsheets, esto nos permitirá obtener una primera visión general de su contenido. Si observamos la parte inferior del documento, veremos que está organizado en varias pestañas. En el caso de la edición de 2023, el fichero consta de seis hojas de cálculo. Cada hoja está organizada de forma diferente y contiene información diversa sobre los ODS. Veamos las pestañas, una por una.

- About: es la página inicial, donde se explica qué encontraremos en las otras hojas y una descripción de todos los aspectos formales (cómo citarla, licencia, etc.).
- Overview: se clasifica cada país según el grado de desempeño de cada ODS y su evolución (positiva o negativa). Es la parte más divulgativa, puesto que no se enseñan datos concretos, solo tendencias.
- Codebook: indica exactamente qué mide cada una de las variables que encontraremos en las otras hojas del documento. Esta hoja es indispensable porque nos permitirá comprender los detalles de cada variable.
- SDR2023 Data: es la pestaña donde encontramos de manera más detallada los indicadores de 2023.
- Raw data (time series): parecida a la pestaña anterior, pero aquí se añaden los indicadores de años anteriores, cosa que nos permitirá ver tendencias temporales.
- Data for trends: encontramos las puntuaciones de los ODS para cada año calculadas retroactivamente con series de datos anuales.
Los datos que nos interesan están principalmente ubicados en las pestañas SDR 2023 Data y en Raw data (time series). Y, para entenderlas, será imprescindible tener en cuenta el libro de códigos, que se encuentra en la pestaña Codebook.
Ahora que sabes cómo está organizada esta base de datos, busca a qué hoja tendrías que ir para encontrar:
- El porcentaje de fumadores respecto a la población mayor de 15 años en el Estado español en 2020.
- La evolución del objetivo 15 de desarrollo sostenible en Corea del Norte.
17.3 Importarlas a R
Una vez ya te has orientado con el documento, lo que harás será importar los datos a R; esto te permitirá un análisis más eficiente y rápido de los datos. Para poder seguir correctamente este módulo, tienes que cargar los paquetes dplyr, readr, ggplot2, readxl y stringr (Wickham, François, et al., 2023; Wickham, Hester, et al., 2023; Wickham, 2023; Wickham et al., 2024; Wickham & Bryan, 2023):
Recuerda que para utilizar un paquete, este tiene que estar previamente instalado en RStudio. Si no has instalado alguno de estos paquetes, ahora es el momento de hacerlo:
install.packages(c("dplyr", "readr",
"ggplot2", "readxl", "stringr"))Como anteriormente ya nos hemos descargado el archivo de los ODS, ahora solo habrá que abrir un proyecto en RStudio y ubicar el archivo de Excel en la carpeta del proyecto. La edición de 2023 se vería de la siguiente manera:

Para trabajar este archivo en R, hay que tenerlo almacenado en un objeto. Por eso importaremos estos datos dentro del objeto sdg utilizando la función read_xlsx(), que sirve para leer archivos .xlsx. Esta función pertenece al paquete readxl, que tendremos que tener cargado para poder hacer la importación. De la función, utilizaremos dos argumentos:
-
"SDR2023-data.xlsx": indicamos el nombre del fichero que queremos importar. -
sheet = 4: indicamos que queremos importar la cuarta pestaña del documento (es decir, la pestaña SDR2023 Data)1.
1 Si no lo especificáramos, solo nos cargaría la primera hoja de cálculo del fichero.
sdg <- read_xlsx("SDR2023-fecha.xlsx", sheet = 4)Antes de empezar a trabajar con el objeto sdg, realizaremos una segunda acción que más adelante resultará muy útil para trabajar con los datos. Importaremos la tercera hoja de cálculo (sheet = 3), donde se encontraba el libro de códigos, y lo guardaremos en el objeto codebook.
codebook <- read_xlsx("SDR2023-data.xlsx", sheet = 3)¿Tienes algún problema a la hora de importar el archivo? Lo más probable es que no tengas el archivo en la carpeta del proyecto. Asegúrate de que:
- Has creado un proyecto (verás el título del proyecto en el extremo derecho superior del gráfico).
- Tienes el archivo ubicado en la carpeta del proyecto (en la ventana ‘Files’, asegúrate de que estás en la carpeta correcta y que el archivo en cuestión está ubicado en esta carpeta).
17.3.1 Buscador en el libro de códigos
Con las funciones de R se puede crear un pequeño buscador, de forma que, si ponemos una palabra clave, nos devuelva qué indicadores concretos existen para esta palabra concreta. Este buscador lo hemos creado de la siguiente manera:
- La construcción principal del código es
codebook[ , ]. Como ya sabemos, esto significa que haremos una selección específica de filas o de columnas del objetocodebook. - En las filas, utilizaremos la función
str_detect(), del paquete stringr, que transforma en TRUE todos los valores de un vector que cumplen un determinado requisito. Especificamos el vectorcodebook$Indicatory como requisito especificamos"Poverty"2. - También añadimos el código
!is.na(codebook$Indicator), que elimina los valores perdidos.
2 Para entender su funcionamiento, teclea str_detect(codebook$Indicator, "Poverty") y fíjate que devuelve un vector lógico que indica TRUE, si en la fila Indicator sale la palabra Poverty y FALSE, cuando no sale.
codebook[str_detect(codebook$Indicator, "Poverty") & !is.na(codebook$Indicator), ]
## # A tibble: 3 × 25
## IndCode SDG global oecd spillover trend trendoecd Indicator New
## <chr> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 sdg1_wpc 1 yes yes <NA> yes yes Poverty headc… Modi…
## 2 sdg1_lmicpov 1 yes yes <NA> yes yes Poverty headc… Modi…
## 3 sdg1_oecdpov 1 no yes <NA> <NA> yes Poverty rate … <NA>
## # ℹ 16 more variables: `Period for trend calculation` <chr>,
## # `Reference year` <dbl>, Direction <chr>, Optimum <dbl>,
## # `Green threshold` <dbl>, `Red threshold` <dbl>, `Lower bound` <dbl>,
## # `Justification for Optimum` <chr>, `UNSD match` <chr>, `UNSD target` <chr>,
## # dwldlink <chr>, Source <chr>, Reference <chr>, Description <chr>,
## # Imputation <chr>, Computation <chr>Si nos resulta más cómodo ver los datos en una pestaña nueva, podemos rodear el código con la función View():
View(codebook[str_detect(codebook$Indicator, "Poverty") & !is.na(codebook$Indicator), ])Fijémonos que nos ha devuelto tres vectores que contienen información de pobreza. Cuando observamos en detalle el marco de datos resultante, veremos que corresponden a las siguientes variables:
-
sdg1_wpc: Poverty headcount ratio at $2.15/day (2017 PPP, %). -
sdg1_lmicpov: Poverty headcount ratio at $3.65/day (2017 PPP, %). -
sdg1_oecdpov: Poverty rate after taxes and transfers (%).
Si te da algún error en este apartado, recuerda que tienes que cargar los paquetes:
-
library(readxl): permite leer el Excel. -
library(stringr): contienestr_detect(), que permite buscar caracteres.
Así pues, para buscar otros indicadores solo hará falta que sustituyas en el código anterior la palabra “Poverty” por otra que prefieras. Si no sale ningún resultado, prueba introduciendo la palabra en letra minúscula o intenta otras palabras parecidas.
Busca qué indicadores hay sobre agua (water) en esta base de datos. Recuerda que:
- Hay que escribir en inglés.
- El buscador es sensible a las mayúsculas y las minúsculas.
17.4 Exploración de datos
Una vez cargados los datos en R, podemos explorarlos algo más en detalle. Este proceso de exploración se divide en dos fases: una exploración más general y una exploración más específica. En la exploración general observaremos todo el marco de datos, mientras que en la exploración específica nos centraremos en variables concretas.
17.4.1 Exploración general
Tenemos principalmente dos maneras de explorar un marco de datos. La primera consiste en escribir el nombre del objeto gdp en la consola.
sdg
## # A tibble: 206 × 666
## `Country Code ISO3` Country `2023 SDG Index Score` `2023 SDG Index Rank`
## <chr> <chr> <dbl> <dbl>
## 1 FIN Finland 86.8 1
## 2 SWE Sweden 86.0 2
## 3 DNK Denmark 85.7 3
## 4 DEU Germany 83.4 4
## 5 AUT Austria 82.3 5
## 6 FRA France 82.0 6
## 7 NOR Norway 82.0 7
## 8 CZE Czechia 81.9 8
## 9 POL Poland 81.8 9
## 10 EST Estonia 81.7 10
## # ℹ 196 more rows
## # ℹ 662 more variables: `Percentage missing values` <dbl>,
## # `International Spillovers Score (0-100)` <dbl>,
## # `Regional Score (0-100)` <dbl>, `International Spillovers Rank` <dbl>,
## # `Regions used for the SDR` <chr>, `Population in 2022` <dbl>,
## # `Goal 1 Dash` <chr>, `Goal 1 Trend` <chr>, `Goal 2 Dash` <chr>,
## # `Goal 2 Trend` <chr>, `Goal 3 Dash` <chr>, `Goal 3 Trend` <chr>, …Con esta acción podemos observar los siguientes elementos:
- El marco de datos tiene 206 observaciones y 666 (!) variables.
- Con una vista de las primeras 10 observaciones, constatamos que en cada observación tenemos datos de un país diferente.
- Nos fijamos en que las observaciones están ordenadas por la variable
2023 SDG Index Score, de forma que podemos ver los países que puntúan más alto en el SDG Index. - También veremos más o menos columnas del marco de datos según si la consola de R es más o menos ancha.
La segunda manera de explorar los datos es con la función glimpse(). Esta función es especialmente útil en marcos de datos de muchas variables, puesto que las despliega todas en formato vertical y permite visualizar solo las primeras observaciones de cada una de ellas. Así nos podemos hacer una idea del contenido de cada variable. A continuación, vemos solo las primeras 20 variables, pero si lo reproduces en tu consola verás toda la lista de 666 variables.
glimpse(sdg)Rows: 206
Columns: 15
$ `Country Code ISO3` <chr> "FIN", "SWE", "DNK", "DEU", "…
$ Country <chr> "Finland", "Sweden", "Denmark…
$ `2023 SDG Index Score` <dbl> 86.76059, 85.98140, 85.68364,…
$ `2023 SDG Index Rank` <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10…
$ `Percentage missing values` <dbl> 2.061856, 3.092784, 1.030928,…
$ `International Spillovers Score (0-100)` <dbl> 73.73608, 67.30785, 68.00446,…
$ `Regional Score (0-100)` <dbl> 77.81407, 77.81407, 77.81407,…
$ `International Spillovers Rank` <dbl> 128, 139, 137, 144, 152, 148,…
$ `Regions used for the SDR` <chr> "OECD", "OECD", "OECD", "OECD…
$ `Population in 2022` <dbl> 5538263, 10517669, 5867977, 8…
$ `Goal 1 Dash` <chr> "green", "green", "green", "y…
$ `Goal 1 Trend` <chr> "↑", "↑", "➚", "↓", "➚", "➚",…
$ `Goal 2 Dash` <chr> "red", "red", "orange", "oran…
$ `Goal 2 Trend` <chr> "→", "→", "→", "→", "→", "→",…
$ `Goal 3 Dash` <chr> "yellow", "yellow", "yellow",…17.4.2 Exploración específica
Una vez tenemos una idea general sobre el contenido de los datos, podemos hacer una exploración más específica de variables concretas con algunas funciones de R. Por ejemplo, la función table() permite obtener un recuento de cuántas categorías existen en un vector de carácter determinado. Si queremos conocer el número de países que hay en cada una de las regiones del informe, solo habrá que indicar dentro de la función que queremos ver la columna Regions used for the SDR del marco de datos sdg.
table(sdg$`Regions used for the SDR`)
##
## E. Europe & C. Asia East & South Asia LAC MENA
## 27 21 29 17
## Oceania OECD Sub-Saharan Africa
## 12 38 49En el resultado observamos que la región que contiene más países es África subsahariana con 49.
Cuando los vectores contienen espacios, como es el caso de Regions used for the SDR, a la hora de usar el vector tendremos que rodear su nombre con el acento abierto (``) para que R lo interprete correctamente. Fíjate en el siguiente ejemplo:
- En el primer caso, dará error.
- En el segundo caso, se reproducirá el vector.
sdg$Regions used for the SDR
sdg$`Regions used for the SDR`Hemos podido observar que el marco de datos contiene muchos vectores numéricos, por lo cual será interesante conocer algunas funciones para examinarlos con facilidad. A continuación vemos algunas funciones que nos permiten resumir una variable concreta, como el máximo, el mínimo, la media o la mediana3. Observamos, por ejemplo, cuál es el valor máximo, el mínimo, la media y la mediana de la variable Press Freedom Index, que muestra el nivel de libertad de prensa que tienen los países, siendo 100 el valor teórico más alto posible y 0 el valor teórico más bajo posible.
3 Cuando pidas sumarios de los datos, no olvides poner como segundo argumento na.rm = TRUE. Este argumento elimina los valores perdidos a la hora de hacer los cálculos.
¿Cuál es el valor máximo?
max(sdg$`Press Freedom Index (worst 0-100 best)`, na.rm = TRUE)
## [1] 95.18¿Cuál es el valor mínimo?
min(sdg$`Press Freedom Index (worst 0-100 best)`, na.rm = TRUE)
## [1] 21.72¿Cuál es la media?
mean(sdg$`Press Freedom Index (worst 0-100 best)`, na.rm = TRUE)
## [1] 57.84199¿Cuál es la mediana?
median(sdg$`Press Freedom Index (worst 0-100 best)`, na.rm = TRUE)
## [1] 57.899Otra opción es utilizar funciones de visualización, que nos permiten representar los datos en un gráfico. La manera más habitual de representar una variable numérica es el histograma, que sirve por recontar el número de observaciones que caen en un intervalo concreto de los datos. Introduciremos el nombre de la variable dentro de la función hist().
hist(sdg$`Press Freedom Index (worst 0-100 best)`)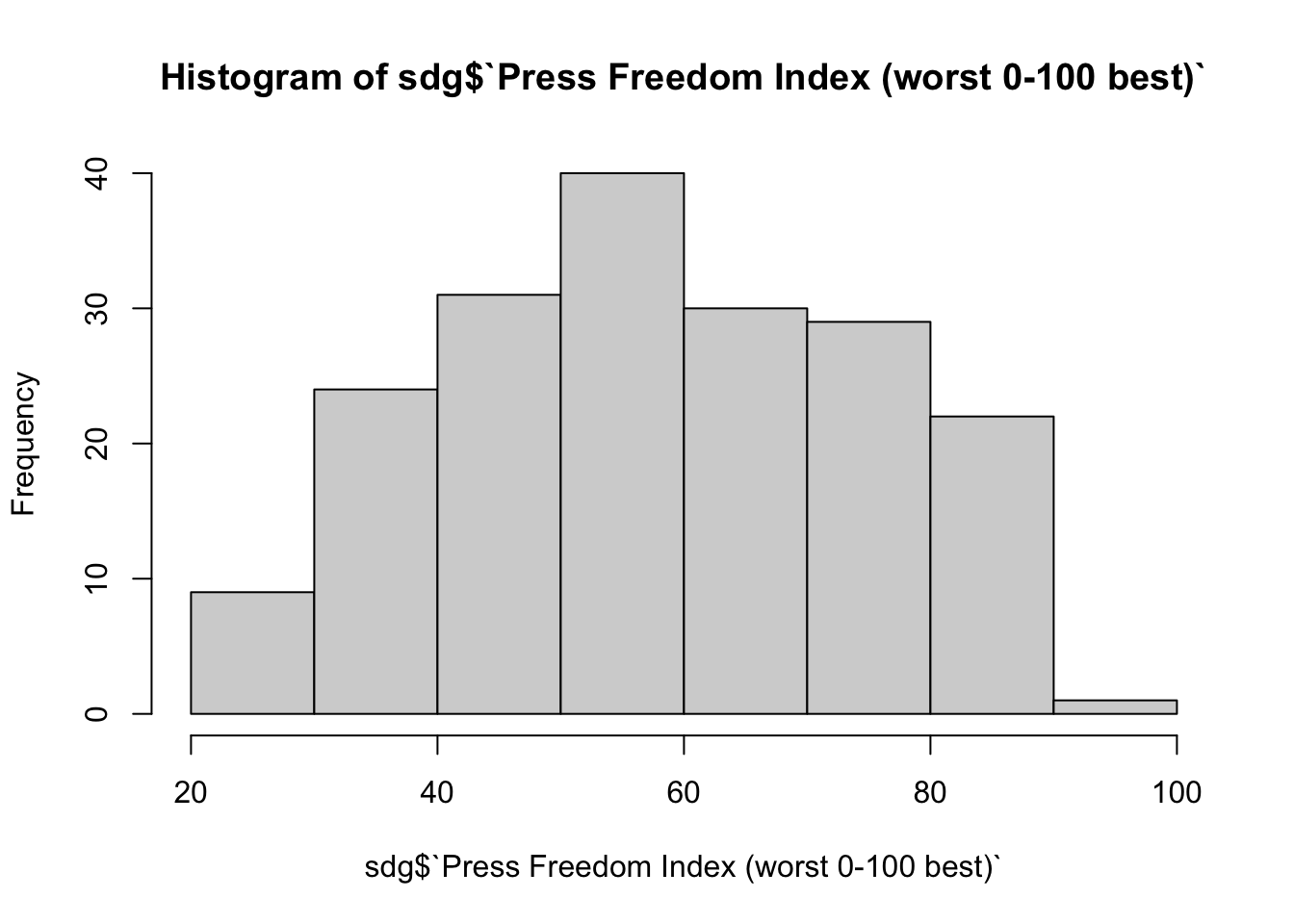
Con el gráfico podemos obtener información complementaria que no podíamos observar con el resultado de las funciones de sumario que hemos visto anteriormente. Por ejemplo, nos fijamos en que muy pocos países puntúan una cifra próxima a 100 en el índice de libertad de prensa. También vemos que el intervalo de datos más repetido es el que va de 50 a 60 en el índice, que incluye aproximadamente unos 40 casos.
- Haz una tabla que muestre qué cantidad de países están teniendo una buena tendencia (trend) del objetivo 2 (
Goal 2 Trend). - Visualiza con un histograma cuál es la distribución del porcentaje de población que usa internet.
Si tienes problemas para encontrar variables concretas al escribir sdg$, recuerda que puedes buscar toda la lista de variables de forma sencilla si pulsas el tabulador después de escribir el símbolo del dólar.
17.5 Cruce de datos
También podemos cruzar datos para ver cómo están relacionadas dos variables numéricas entre sí. En este caso, la visualización más habitual es el diagrama de dispersión, que se puede ejecutar muy rápidamente con plot(). Para utilizarla, dentro de la función pondremos los dos vectores numéricos que queremos examinar, separados por una coma. A continuación, observamos cómo se relaciona la libertad de prensa con las percepciones de corrupción. Sobre esta segunda variable, hay que concretar que los países con más percepción de corrupción tendrán un valor que se acercará a 0, mientras que los países donde la percepción de la corrupción es menor tendrán un valor próximo a 100.
plot(sdg$`Press Freedom Index (worst 0-100 best)`,
sdg$`Corruption Perceptions Index (worst 0-100 best)`)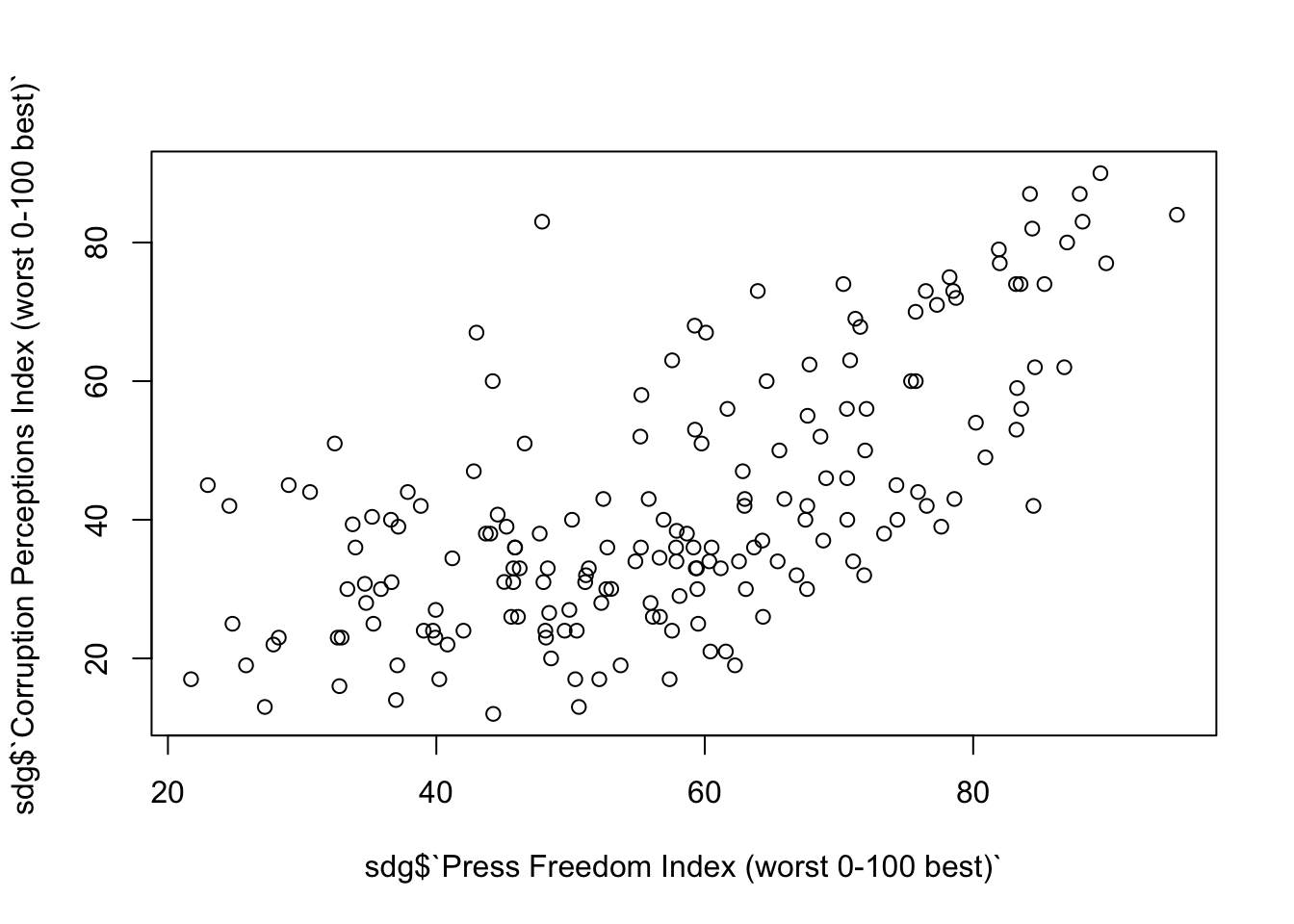
Si nos fijamos en el gráfico, vemos que hay una relación positiva entre la libertad de prensa y la percepción de la corrupción. Es decir, los países que tienen más libertad de prensa también tienen una mejor percepción de la corrupción (por lo tanto, menor), mientras que los países con menor libertad de prensa tienen una peor percepción de la corrupción (por lo tanto, mayor).