16 Banco Mundial
16.1 Introducción
El Banco Mundial (World Bank en inglés) es una institución internacional financiera que se fundó en 1944 en la conferencia de Bretton Woods, junto con otras organizaciones, como el Fondo Monetario Internacional (FMI). Desde su fundación, esta institución se ha encargado de dar préstamos a Gobiernos de todo el mundo, especialmente a países de pocos recursos, para impulsar su desarrollo económico. Pero lo que es especialmente interesante para nosotros es su iniciativa de datos abiertos.
El Banco Mundial contiene más de 1.400 indicadores de más de 200 economías mundiales, con series temporales que van en algunos casos desde finales de la Segunda Guerra Mundial hasta la actualidad. Los datos alcanzan multitud de temas, desde agricultura hasta deuda externa, pasando por indicadores macroeconómicos o indicadores de igualdad de género, entre muchísimos otros. Estos datos se pueden visualizar en su página web a través de una consola interactiva y sencilla de utilizar, donde se pueden seleccionar los datos por países y periodo de tiempo, y que incluso ofrece varios tipos de gráficos posibles.
Esta herramienta permite conseguir la visualización de datos sencillos. Si os queréis hacer una idea de cómo funciona, podéis curiosear con la lista de indicadores aquí. Pero lo que es realmente interesante es cómo el Banco Mundial proporciona en abierto todos los datos, para que los que quieran puedan hacer un uso más avanzado de estos mediante un software estadístico. En este apartado descubriremos cómo hacer un tratamiento de los datos con el paquete de R wbstats.
16.2 El paquete wbstats
El paquete wbstats (Piburn, 2020) permite acceder a la gran mayoría de datos abiertos del Banco Mundial en R con unas pocas líneas de código e importarlas fácilmente a R. Esto evita el hecho de tener que descargar y después cargar manualmente en R cada una de las bases de datos, con la consiguiente despreocupación de los problemas de codificación que pueden surgir. Para poderlo utilizar, necesitaremos tener el paquete activado, junto con otros paquetes de R como dplyr, readr y ggplot2 (Wickham, François, et al., 2023; Wickham, Hester, et al., 2023; Wickham et al., 2024).
Recuerda que para utilizar un paquete, este tiene que estar previamente instalado en RStudio. Si no has instalado alguno de estos paquetes, ahora es el momento de hacerlo:
install.packages(c("dplyr", "readr",
"ggplot2", "wbstats"))El paquete wbstats funciona de una forma muy sencilla, puesto que permite:
- Buscar cualquier indicador presente en las bases de datos del Banco Mundial a través de la función
wb_search(). - Descargar el indicador en cuestión a través de la función
wb_data().
Veamos estas dos funciones paso a paso.
16.3 Buscar datos
La función wb_search() funciona como un buscador de caracteres. Solo hay que indicar entre paréntesis qué palabras clave tiene que buscar para que haga una lista de todos los indicadores que están relacionados con aquella palabra. A continuación, se muestra un código que busca los datos que tiene el Banco Mundial sobre producto interior bruto (PIB) per cápita. Dentro de la función tendremos que introducir:
- Un valor de carácter, especificado entre comillas, por ejemplo
"gdp". - Si queremos especificar varias palabras, lo tendremos que hacer utilizando el separador
.*, por ejemplo,"gdp.*capita".
La búsqueda devuelve un marco de datos con tres columnas:
-
indicator_id: el identificador único de la variable. -
indicator: el título formal de la variable. -
indicator_desc: una breve descripción del indicador en cuestión.
# A tibble: 32 × 3
indicator_id indicator indicator_desc
<chr> <chr> <chr>
1 5.51.01.10.gdp Per capita GDP growth "GDP per capi…
2 6.0.GDPpc_constant GDP per capita, PPP (constant 2011 inter… "GDP per capi…
3 GB.XPD.RSDV.GD.ZS Research and development expenditure (% … "Gross domest…
4 GFDD.DM.01 Stock market capitalization to GDP (%) "Value of lis…
5 GFDD.DM.02 Stock market total value traded to GDP (… "Total value …
6 NE.GDI.FPUB.ZS Gross public investment (% of GDP) "Gross public…
7 NE.GDI.FTOT.CR GDP expenditure on gross fixed capital f… "Gross fixed …
8 NE.GDI.FTOT.SNA08.CR GDP expenditure on gross fixed capital f… <NA>
9 NV.AGR.PCAP.KD.ZG Real agricultural GDP per capita growth … "The growth r…
10 NY.GDP.PCAP.CD GDP per capita (current US$) "GDP per capi…
# ℹ 22 more rowsEn este tipo de marcos de datos, nos puede resultar muy conveniente utilizar la función View(), que nos permite observar los datos en una ventana nueva. Para utilizar esta función, guardaremos primero los datos en un objeto y después examinaremos el resultado.
Como podemos observar, la búsqueda devuelve más de 30 indicadores. Cuando los examinamos de cerca, vemos que no todos estos indicadores resultan útiles. Por ejemplo, si estamos interesados solo en el PIB per cápita de los países, nos daremos cuenta de que muchos son indicadores que utilizan el PIB (gdp) como referencia, pero no nos informan directamente de datos de PIB. Es el caso de SH.XPD.CHEX.GD.ZS, que muestra el gasto sanitario del país respecto a su PIB. Por eso es indispensable leer los títulos y las descripciones para saber exactamente qué nos explica el indicador.
Ahora que ya sabes cómo buscar indicadores con wb_search(), busca qué indicadores tiene el Banco Mundial sobre agricultura. Recuerda que tienes que buscarlo en inglés.
Recuerda que, dentro de la función wb_search(), tienes que introducir un vector de carácter. Por lo tanto, tienes que escribir la palabra o palabras "entre.*comillas".
16.4 Importar datos
Una vez que hemos aprendido cómo buscar los indicadores con el paquete, el siguiente paso será importar los datos del indicador que nos interese con la función wb_data(). La información clave que necesitamos es la que se encuentra en la columna indicator_id del marco de datos que hemos ido examinando en el apartado anterior. Para importar los datos, utilizaremos el bloque de código que queda debajo de estas líneas de la siguiente manera:
- Dentro de la función
wb_data(), indicamos con el argumentoindicator = c("NY.GDP.PCAP.CD")que queremos descargar los datos referentes a los indicadores de PIB per cápita a precios constantes y valorados en US$. Guardaremos los datos en el objetogdp.
- En el argumento
countrypodemos especificar si queremos los datos solo por países (la opción por defecto escountry = "countries only") o bien si queremos datos por regiones o por grupos de renta. Si consultáis la ayuda?wb_data(), encontraréis más información sobre las diferentes posibilidades que tiene este argumento. - También se pueden especificar otras características del marco de datos, como, por ejemplo, si queremos la tabla larga o ancha (
return_wide), el año de inicio de los datos (start_date), el año final (end_date) o el idioma de los resultados (lang)1. Por ejemplo:
1 Consulta los idiomas disponibles con wb_languages().
Si en los pasos siguientes surge algún problema con los datos, prueba de descargarlos de nuevo utilizando el código siguiente:
gdp <- wb_data(indicator = c("NY.GDP.PCAP.CD"),
country = "countries_only") |>
mutate(date = as.numeric(date)) |> as_tibble()El código incorpora algunas funciones más:
- La función
mutate(date = as.numeric(date))recodifica la columna “date” para que R la lea como una variable numérica. - La función
as_tibble()indica a R que nos tiene que devolver esta base de datos en formato tibble, que es más cómodo para trabajar.
16.5 Explorar datos
Para poder usar los datos correctamente, antes es necesario saber exactamente cómo están organizados, las dimensiones de nuestra base de datos o las características de cada una de las variables. A este proceso se le denomina exploración de datos. Los datos que exploraremos son los que importamos con el siguiente código2.:
2 si últimamente el Banco Mundial ha actualizado sus datos, es posible que tus datos no coincidan al 100% con los del ejemplo de este módulo.
Para comprobar que los datos se han importado correctamente, podemos escribir el nombre del objeto (gdp) en la consola de Rstudio, que nos devolverá una muestra de las 10 primeras observaciones de nuestra base de datos.
- El objeto
gdpes una tibble formada por 7.161 observaciones y 9 columnas. - Los datos están ordenados alfabéticamente por países, en las 10 primeras observaciones solo vemos los datos de Aruba, de 1990 hasta 1999.
gdp
## # A tibble: 7,161 × 9
## iso2c iso3c country date NY.GDP.PCAP.CD unit obs_status footnote
## <chr> <chr> <chr> <dbl> <dbl> <lgl> <lgl> <lgl>
## 1 AW ABW Aruba 1990 11639. NA NA NA
## 2 AW ABW Aruba 1991 12850. NA NA NA
## 3 AW ABW Aruba 1992 13658. NA NA NA
## 4 AW ABW Aruba 1993 14970. NA NA NA
## 5 AW ABW Aruba 1994 16675. NA NA NA
## 6 AW ABW Aruba 1995 17140. NA NA NA
## 7 AW ABW Aruba 1996 17375. NA NA NA
## 8 AW ABW Aruba 1997 18713. NA NA NA
## 9 AW ABW Aruba 1998 19742. NA NA NA
## 10 AW ABW Aruba 1999 19834. NA NA NA
## # ℹ 7,151 more rows
## # ℹ 1 more variable: last_updated <date>Para explorar más a fondo el objeto gdp, podemos utilizar unos sencillos mandos de R para responder algunas cuestiones fundamentales sobre los datos:
- ¿De qué países diferentes tenemos datos? Como sabemos, la función unique devuelve un vector de carácter con todos los valores que aparecen como mínimo una vez.
unique(gdp$country)- ¿De cuántos países diferentes tenemos datos? Si la pregunta que queremos responder no es cuáles, sino cuántos países, podemos incluir en el mismo código de antes la función length(). Esta función se encarga de contar la longitud que tiene un vector. Por lo tanto, en este caso contará cuántos nombres (países) salen como mínimo una vez en la variable country.
- ¿Cuál es el rango longitudinal de datos? Podemos comprobar que, efectivamente, los datos empiezan en 1990 y acaban en 2020. La función range()determina el valor mínimo y el valor máximo de un vector. Además, introduciremos el argumento na.rm = TRUE, que indica que la función ignore los valores perdidos y funcione solo con aquellos que conoce.
range(gdp$date, na.rm = TRUE)Recuerda que para que range() funcione, R tiene que ser capaz de entender que una variable es numérica. Si R no la detecta como número, es tan sencillo como convertirla a variable numérica con la función as.numeric(). Por ejemplo:
gdp$date <- as.numeric(gdp$date)Esto transformará la variable date en numérica.
Ahora que sabes cómo explorar los datos, utiliza una de las funciones que acabamos de ver e intenta responder las siguientes preguntas:
- ¿Cuál es el valor más alto de PIB per cápita?
- ¿Cuál es el valor más bajo de PIB per cápita?
16.6 Visualizar datos
En este apartado aprenderemos a visualizar los datos del objeto gdp de dos maneras diferentes: en un año determinado y a través del tiempo. Crearemos las visualizaciones con las funciones del paquete ggplot2 (Wickham et al., 2024).
16.6.1 En un año determinado
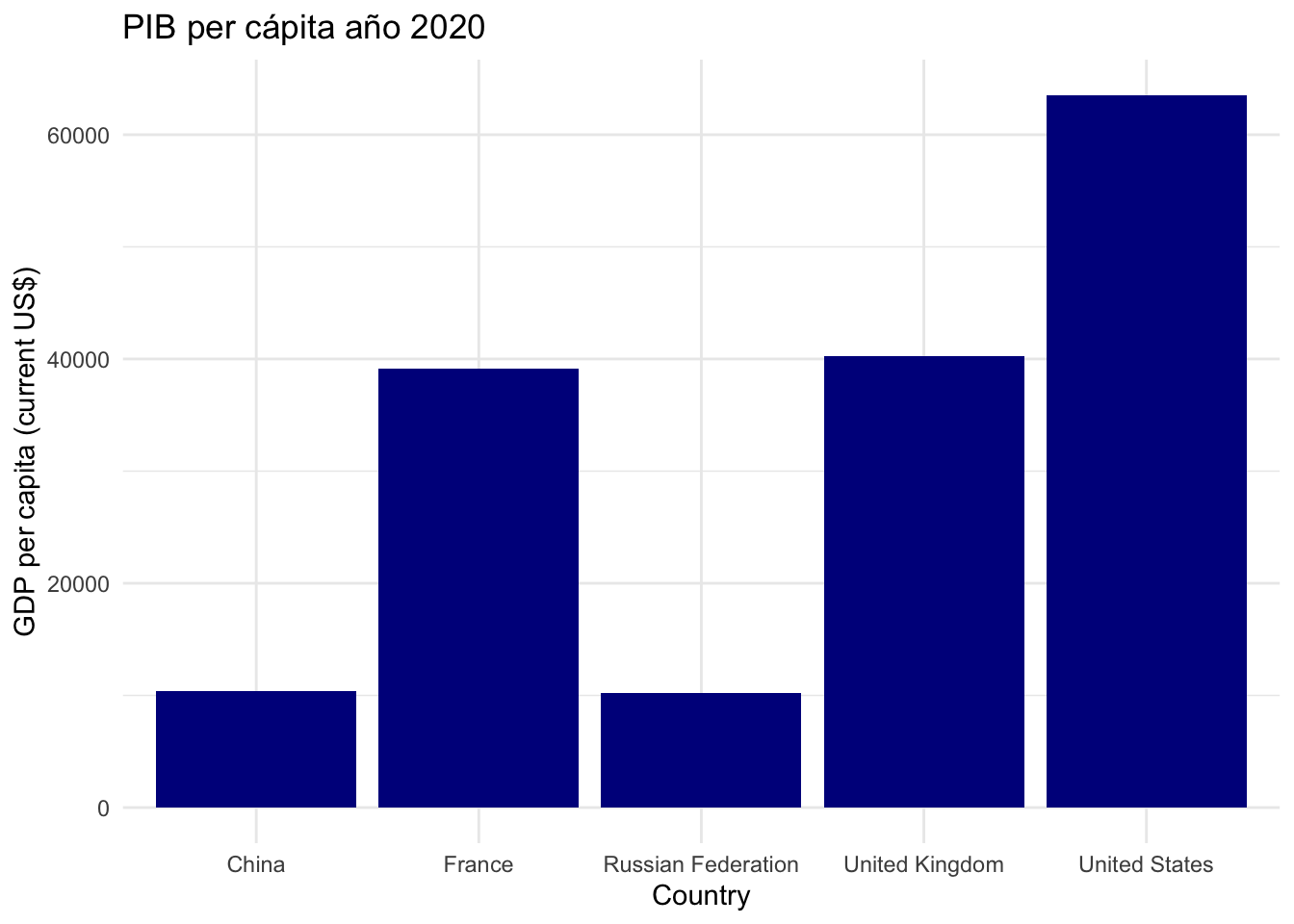
En este primer gráfico observaremos unos datos concretos de diferentes países en un año determinado. En el supuesto que nos ocupa, hemos decidido observar el PIB per cápita de cinco países (Estados Unidos, China, Rusia, el Reino Unido y Francia) en 2020. Para hacerlo correctamente seguiremos estos pasos:
En primer lugar, reduciremos los datos para que muestren solo las observaciones que nos interesan.
- Dentro de la función
filter(), indicaremos el año (date) que nos interesa examinar y los países (country) en cuestión dentro de un vector de carácter. - Fijémonos que esto nos produce un marco de datos de cinco observaciones.
gdp |>
filter(date == 2020,
country %in% c("United States", "China", "Russian Federation",
"United Kingdom", "France"))
## # A tibble: 5 × 9
## iso2c iso3c country date NY.GDP.PCAP.CD unit obs_status footnote
## <chr> <chr> <chr> <dbl> <dbl> <lgl> <lgl> <lgl>
## 1 CN CHN China 2020 10409. NA NA NA
## 2 FR FRA France 2020 39180. NA NA NA
## 3 GB GBR United Kingdom 2020 40217. NA NA NA
## 4 RU RUS Russian Federation 2020 10194. NA NA NA
## 5 US USA United States 2020 63529. NA NA NA
## # ℹ 1 more variable: last_updated <date>El próximo paso será ubicar los vectores en cuestión en un gráfico, por lo que tendremos que tener cargado el paquete ggplot2.
- Dentro de las funciones
ggplot(aes()), especificaremos que en el eje x (horizontal) pondremos los países y en el eje y (vertical) los datos de PIB per cápita. - Fijémonos cómo ggplot2 nos ubica estas dos variables en el gráfico.
Finalmente, indicaremos la geometría y el título del gráfico y de los ejes:
- La geometría será un diagrama de barras (
geom_col()). Con el argumentofillpersonalizaremos el color de las barras del gráfico ("darkblue"). - Especificaremos los títulos del gráfico, indicando dentro de la función
labs()un valor de carácter por cada argumento:x,yytitle.
Ahora que ya has visto lo sencillo que es hacer un gráfico comparando datos de un año de varios países, intenta comparar los datos de PIB per cápita de tres países diferentes, pero del año 2015:
- Añade el valor del año en cuestión.
- Cambia los
?por países que quieras examinar. Como sabes, puedes pedir la lista de países con la funciónunique(). - Cambia el color de las barras, consultando esta web.
- Cambia los títulos del gráfico.
gdp |>
filter(date == ?,
country %in% c("?", "?", "?")) |>
ggplot(aes(x = country, y = NY.GDP.PCAP.CD)) +
geom_col(fill = "darkblue") +
labs(title = "Título del gráfico", x = "Título de x", y = "Título de y")- Recuerda que los países tienen que estar escritos en inglés e ir “entre comillas”. En cambio, los números no hace falta que vayan entre comillas.
- Además, la última línea de código del gráfico no tiene que tener el símbolo
+al final, porque si no ggplot2 no entenderá que el gráfico ya está acabado.
16.6.2 A través del tiempo
El hecho de que el Banco Mundial provea datos de varios años nos permite ver la evolución de algunos indicadores a lo largo del tiempo. Por ejemplo, nos puede interesar ver cómo evolucionan los datos del PIB per cápita de Estados Unidos y China. Para conseguirlo, haremos las siguientes operaciones en el objeto gdp:
- Con
filter(), filtramos los datos del vectorcountrypara los países que nos interesan, de forma que conservaremos solo las observaciones que forman parte de Estados Unidos o de China. - Indicamos con las funciones
ggplot(aes())las variables del gráfico: en el eje horizontal pondremos el año (x = dato); en el eje vertical, el indicador de PIB per cápita (y = NY.GDP.PCAP.CD) y también especificaremos que el color sirva para diferenciar los datos de los países (col = country) - Para ver la evolución de una variable en el tiempo, la geometría más apropiada es el diagrama de líneas
geom_line(). - Finalmente, en la última capa definiremos los títulos del gráfico con la función
labs().
gdp |>
filter(country %in% c("United States", "China")) |>
ggplot(aes(x = date, y = NY.GDP.PCAP.CD, colour = country)) +
geom_line() +
labs(title = "Evolución PIB per cápita (1990-2022)",
x = "Year", y = "GDP per capita (current US$)", col = "País")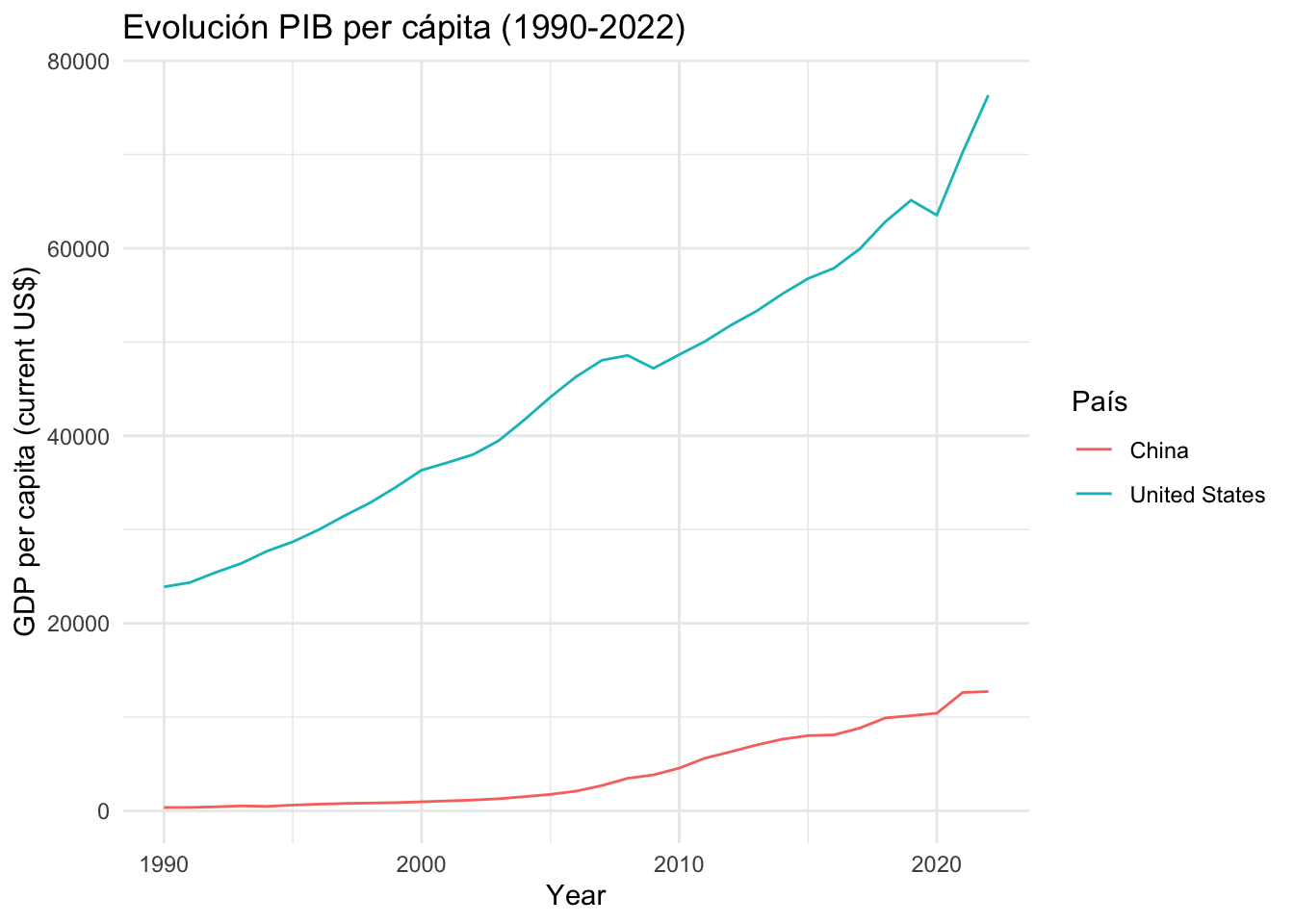
Una vez visto cómo se puede hacer un gráfico sencillo con ggplot, y fijándote en el código que se muestra, prueba a hacer un gráfico comparativo con dos países europeos diferentes. Haz las siguientes modificaciones en el código:
- Filtra los datos por otros valores del vector
country. - Cambia el título del gráfico.
- Opcionalmente, añade el argumento
linetype = countrydentro de la capa deggplot(aes())y observa los resultados.