19 Calidad de Gobierno
19.1 Introducción
El Quality of Government Institute (QoG a partir de ahora) es una institución de investigación asociada a la Universidad de Gotemburgo (Suecia). Fue fundada en 2004 y es famosa por haber realizado múltiples estudios y elaborado varias bases de datos alrededor de la calidad de Gobierno. Los conjuntos de datos que almacenan acostumbran a agrupar indicadores de varias organizaciones internacionales, de forma que son un recurso muy útil como cajón de sastre si necesitamos datos que tienen como unidad de observación el país-año. El conjunto de datos más amplio es el Standard Dataset, que contiene más de 2.100 (!) variables. También podemos encontrar bases de datos especializadas en la sostenibilidad y el medio ambiente (Environmental Indicators Dataset) y datos de nivel subnacional (EU Regional Dataset).
En esta actividad, trataremos con una versión reducida de la Standard Dataset, la Basic Dataset (Dahlberg et al., 2020), que contiene 400 variables, una cantidad suficiente y bastante interesante para trabajar con datos relacionados con la gobernanza.
19.2 Descarga por web o paquete
Para descargar los datos de QoG, iremos a su página web, donde hay colgadas todas las bases de datos en formato abierto. Cuando entremos en esta página web, veremos que en la parte derecha de la pantalla se ofrecen varias posibilidades de descarga.
-
Cross-Section: es un conjunto de datos organizado a nivel de país en el último año registrado de datos, que otorga cada observación (192 en total) a un país diferente. No la utilizaremos, pero hay muchas formas de descarga:
- DTA (Stata)
- CSV (fichero separado por comas)
- XLSX (Excel “normal”)
- SAV (pensado para SPSS, suele venir etiquetado)
Time-Series: es un conjunto de datos que tiene como unidad de observación el país-año y tiene un alcance temporal muy amplio, que empieza al final de la Segunda Guerra Mundial y llega hasta la actualidad. Al ser una base de datos mucho más grande (casi 16.000 observaciones), solo podemos descargarla en tres formatos diferentes.
En esta actividad descargaremos los datos Time Series en formato CSV desde el margen derecho de la pantalla, tal como se muestra en la parte inferior de la Figura 19.1. Cuando descarguemos el fichero, lo guardaremos con el nombre de qog_timeseries.csv y lo situaremos en el directorio de trabajo. Seguidamente, lo importaremos a RStudio con la función read_csv() del paquete readr, que tendremos que cargar junto con todos los otros paquetes que usaremos en esta actividad (Wickham, François, et al., 2023; Wickham, Hester, et al., 2023; Wickham et al., 2024).
Una alternativa para importar la base de datos es con el paquete de R rqog (R-rqog?). Si queréis probar este método, opcionalmente podéis seguir este procedimiento:
- Instalar y cargar el paquete
devtools, que nos permite abrir paquetes subidos a Github. - Instalar y cargar el paquete
rqogcon la funcióninstall_github. - Cargar el dataset QoG basic utilizando la función
read_qog()y añadiendo el argumentowhich_data = "basic". También añadimos la funcióntibble()para convertir los datos en formato tibble.
install.packages("devtools")
library(devtools)
install_github("ropengov/rqog")
library(rqog)
qog_basic <- tibble(read_qog(which_data = "basic"))Es posible que esta segunda forma dé problemas o errores en algunos ordenadores, porque implica modificaciones un poco complejas al instalar paquetes externos al ambiente de Rstudio. Por lo tanto, si no te funciona, simplemente descarga el archivo CSV desde la web, tal como hemos hecho anteriormente.
19.3 Libro de códigos
El libro de códigos es imprescindible para comprender el contenido del conjunto de datos. El de QoG se encuentra en la misma web de donde nos hemos descargado los datos, también en el margen derecho, en la sección Codebook, tal como se muestra en la Figura 19.2.
Aquí nos descargaremos el libro de códigos en formato PDF. Encontraremos un fichero de unas 400 páginas, donde se especifica en detalle el contenido del conjunto de datos, qué variables encontramos, qué explican exactamente, de dónde han salido y la disponibilidad, tanto temporal (qué años incluyen) como geográfica (de qué países tienen datos).
Podemos perdernos un poco y curiosear cada una de estas páginas, pero antes intentaremos entender cómo está organizado este libro de códigos. Por ello, intentaremos buscar si hay datos de la percepción de la corrupción. Esto nos permitirá familiarizarnos con el proceso de búsqueda de variables en el documento, que consiste en dos pasos:
- En el apartado 2 del libro de códigos, consultaremos la lista de variables. Una de las categorías de esta lista es Quality of Government, donde vemos que nos indica la página donde buscar el Corruption Perceptions Index. En este caso está en la página 82, pero hay que tener en cuenta que los libros de códigos se actualizan regularmente y que, por lo tanto, puede ser que si consultas una versión más nueva encuentres este indicador en una página diferente.
Verás como este libro de códigos habla de algunas variables que no se encuentran en el Basic Dataset. La razón por la cual no están es probablemente porque estas variables se encuentran a la Standard Dataset. También puede ser debido al hecho de que la base de datos se actualiza regularmente y, a veces, puede haber discrepancias con el libro de códigos, teniendo en cuenta que es una base de datos tan grande.
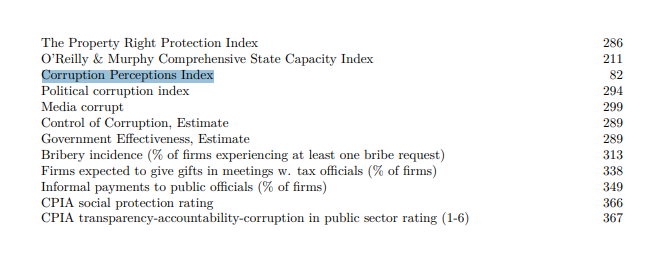
- Una vez localizado el Corruption Perceptions Index dentro del libro de códigos, iremos a la página en cuestión y leeremos atentamente la información técnica de la variable.

Fijémonos que esta variable:
- Tiene por nombre:
ti_cpi, por lo que la tendremos que buscar en el marco de datos comoqog_basic$ti_cpi - El valor 0 equivale al valor más alto de corrupción percibida y el valor 100 equivale al nivel más bajo de corrupción percibida.
- Es una variable continua (es decir, numérica de ratio) con escala de 0 a 100.
- Tiene una alta disponibilidad temporal (2012-2022) y geográfica (179 países), con su correspondiente mapa de disponibilidad y un gráfico donde explica la evolución de los países incluidos en esta variable.
Ahora que sabes cómo leer un libro de códigos, busca si en esta base de datos hay alguna variable que hable de:
- ¿Cuál es el número efectivo de partidos en los parlamentos nacionales? ¿Hay varias fórmulas para calcularlo?
- ¿Qué porcentaje de asientos tienen los partidos agrarios en los parlamentos?
¡Recuerda que tienes que buscar los nombres en inglés!
19.4 Explorar datos
Una vez sabemos descifrar qué nos intentan explicar los indicadores, podemos empezar a explorar este conjunto de datos.
19.4.1 Exploración general
Antes que nada examinaremos el objeto qog_basic, que habíamos almacenado previamente. En la versión descargada para hacer este tutorial, observamos que el marco de datos tiene 15.564 observaciones y 252 variables.
qog_basic
## # A tibble: 15,564 × 252
## ccode cname year ccode_qog cname_qog ccodealp ccodecow version cname_year
## <dbl> <chr> <dbl> <dbl> <chr> <chr> <dbl> <chr> <chr>
## 1 4 Afghani… 1946 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 2 4 Afghani… 1947 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 3 4 Afghani… 1948 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 4 4 Afghani… 1949 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 5 4 Afghani… 1950 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 6 4 Afghani… 1951 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 7 4 Afghani… 1952 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 8 4 Afghani… 1953 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 9 4 Afghani… 1954 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 10 4 Afghani… 1955 4 Afghanis… AFG 700 QoGBas… Afghanist…
## # ℹ 15,554 more rows
## # ℹ 243 more variables: ccodealp_year <chr>, ajr_settmort <dbl>,
## # atop_ally <dbl>, atop_number <dbl>, bci_bci <dbl>, bicc_gmi <dbl>,
## # biu_offrel <dbl>, bmr_dem <dbl>, bmr_demdur <dbl>, cai_cai2 <dbl>,
## # cbi_cbiu <dbl>, cbi_cbiw <dbl>, cbie_index <dbl>, ccp_cc <dbl>,
## # ccp_childwrk <dbl>, ccp_equal <dbl>, ccp_freerel <dbl>, ccp_slave <dbl>,
## # ccp_strike <dbl>, chga_demo <dbl>, ciri_assn <dbl>, ciri_dommov <dbl>, …En la parte inferior del marco de datos aparecen todas las variables que, debido al extenso número de columnas, no aparecen en pantalla. Hay dos funciones que permiten examinar más a fondo todas las variables:
- Con
glimpse(qog_basic)se despliegan todas las variables en formato vertical y se visualizan las primeras observaciones de cada una de ellas. - Con
names(qog_basic)se obtiene un vector de carácter con los nombres de todas las variables.
Utilizando estas dos funciones podremos comprobar si las variables que aparecen en el libro de códigos lo hacen también en el marco de datos. Tenemos que pensar que es posible que algunas variables no aparezcan en la Basic Dataset que estamos trabajando, pero sí en la Standard Dataset.
19.4.2 Exploración específica
Una vez tenemos una idea general sobre el marco de datos y sus variables, podemos hacer una exploración más específica de variables concretas con algunas funciones de R. A continuación nos haremos unas preguntas sobre algunas de las variables que aparecen en el marco de datos:
-
¿Cuál es el rango de años de los datos? Para saberlo, usaremos la función
range()y le indicaremos el vector del marco de datos que nos interesa. En este caso solo hay que escribirqog_basice indicar que queremos explorar la columna de año a través de escribir un símbolo de$y el nombre de la columna correspondienteyear. La operación nos devolverá el valor numérico más bajo y más alto del vector.
range(qog_basic$year)
## [1] 1946 2023-
¿De qué años tenemos datos? Para saber el resultado, tendremos que preguntar qué categorías únicas tiene la variable
yearcon la funciónunique().
unique(qog_basic$year)
## [1] 1946 1947 1948 1949 1950 1951 1952 1953 1954 1955 1956 1957 1958 1959 1960
## [16] 1961 1962 1963 1964 1965 1966 1967 1968 1969 1970 1971 1972 1973 1974 1975
## [31] 1976 1977 1978 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990
## [46] 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005
## [61] 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020
## [76] 2021 2022 2023-
¿De cuántos años tenemos datos? Para saber el resultado tendremos que pedir la longitud del vector anterior. Por lo tanto, combinaremos
length()yunique().
- ¿Cuál es el intervalo de datos de una determinada variable? Utilizando una de las variables que has buscado anteriormente con el ejercicio 1, podemos ver, por ejemplo, cuál es el porcentaje más alto y más bajo de asientos que tienen los partidos agrarios a través de este código.
Si te fijas, la función range() incluye un segundo argumento, na.rm = T, que pide a R que obvie si hay valores perdidos. ¿Qué pasaría si no la pusiéramos?
Pues que simplemente nos daría como resultado NA NA, porque tendría en cuenta los valores perdidos a la hora de calcular el mínimo y el máximo de los datos.
range(qog_basic$cpds_la, na.rm = T)
## [1] 0.0 40.6-
¿De cuántos países diferentes tenemos datos? De nuevo, volvemos a combinar las funciones
length()yunique(), ahora en el vectorqog_basic$cname, y sabremos los nombres únicos de países que aparecen en el marco de datos.
-
¿Cuál es el tipo de régimen autocrático más frecuente?: La función
count()devuelve un recuento de frecuencias de una variable. Dentro de la función tendremos que indicar tres argumentos, separados por comas:- El marco de datos:
qog_basic. - El vector que interesa recontar:
gwf_regimetype. - Si se ordena el recuento dejando los grupos más numerosos en la parte superior del resultado:
sort = TRUE.
- El marco de datos:
count(qog_basic,
gwf_regimetype,
sort = TRUE)
## # A tibble: 11 × 2
## gwf_regimetype n
## <dbl> <int>
## 1 NA 11041
## 2 4 1435
## 3 2 1152
## 4 1 595
## 5 5 386
## 6 3 291
## 7 7 251
## 8 8 177
## 9 6 133
## 10 9 66
## 11 10 37
Para interpretar el resultado, tendremos que seguir el libro de códigos, donde se explica el significado de cada valor numérico (Figura 19.3). Si lo consultamos a fondo, veremos que la variable categoriza del 1 al 10 diferentes tipos de regímenes autocráticos y deja como valor perdido (NA) los regímenes democráticos. Por ejemplo, podemos suponer que 11.041 observaciones son regímenes democráticos, y que el tipo de régimen autocrático más repetido con 1.152 observaciones es la autocracia de partido, que corresponde al número 4. Tenemos que pensar que la unidad de observación del marco de datos es país-año, por lo cual la cifra de 1.435 indica la cantidad de observaciones país-año que, entre 1946 y 2023, califican como régimen de autocracia de partido.
19.5 Visualización
No todas las autocracias son igual de autocráticas. Algunas pueden tener algunos rasgos más democráticos que otras, como, por ejemplo, organizar elecciones, permitir la concurrencia de varias formaciones políticas en las elecciones o reprimir de manera moderada su población. Podremos ver de manera general estas diferencias si comparamos una variable categórica como la del tipo de régimen (gwf_regimetype) con una variable numérica como la variable de democracia liberal de V-Dem (vdem_libdem) (Coppedge et al., 2020).
La variable vdem_libdem indica que un país es autocrático cuando se aproxima al valor 0 y que un país se aproxima al ideal de una democracia liberal a medida que se acerca al valor 1. A continuación veremos hasta qué punto algunos países autocráticos tienen ciertos atributos próximos a la democracia liberal. Pondremos como año de referencia 2010, para reducir los datos y almacenarlos en el objeto qog_basic10.
qog_basic10 <- qog_basic |>
filter(year == 2010)19.5.1 Visualizar una variable
En primer lugar, examinaremos más a fondo la nueva variable de interés. Como es una variable numérica, visualizaremos la distribución de los datos con un histograma, que sirve para recontar el número de observaciones que caen en un intervalo concreto de los datos. Introduciremos el nombre de la variable dentro de la función hist().
hist(qog_basic10$vdem_libdem)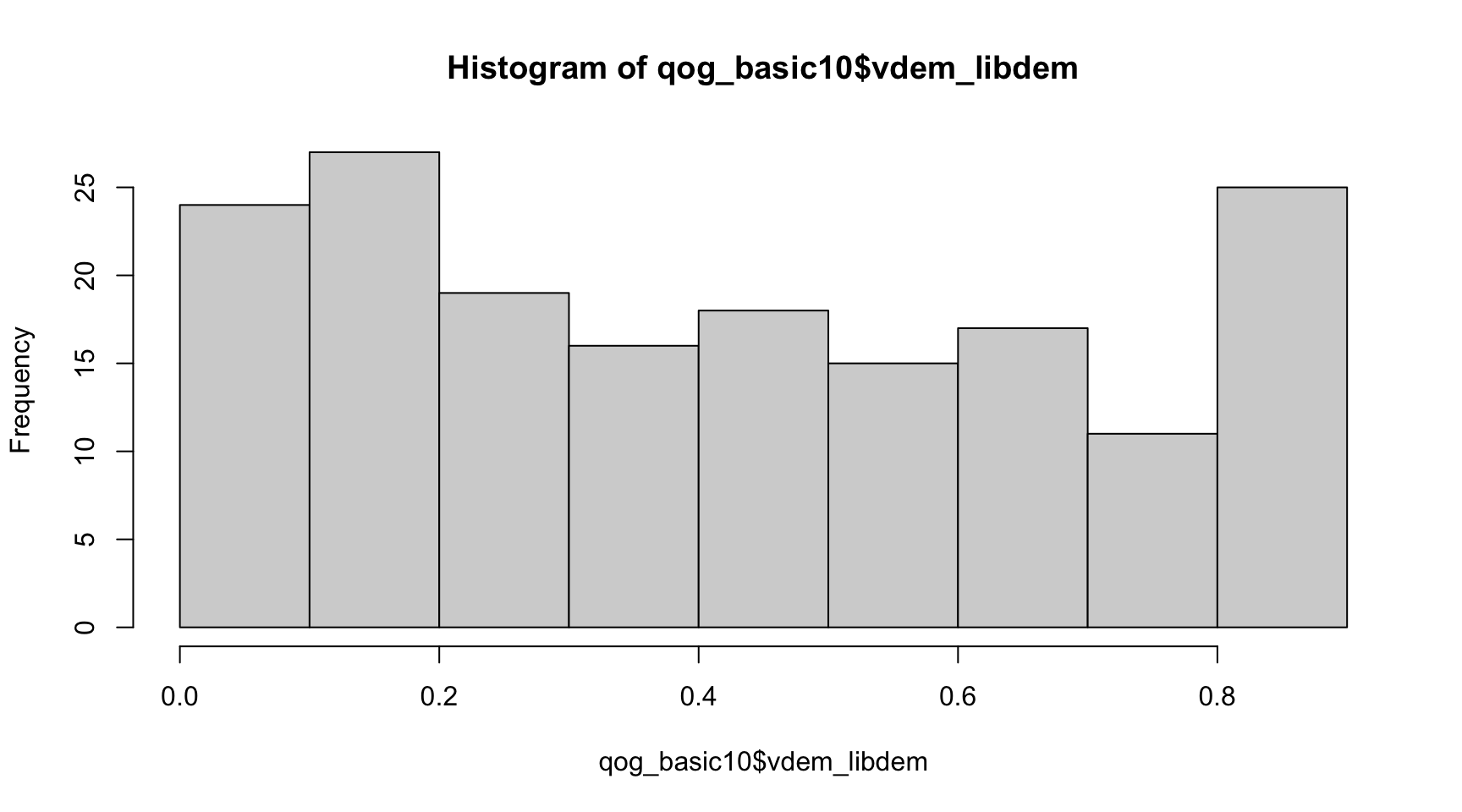
Fijémonos que en 2010 había mucha variabilidad entre regímenes políticos. Unos 25 regímenes eran muy autocráticos, muy próximos al valor 0. También unos 25 regímenes políticos se acercaban al valor 0,2, señal de que eran bastante autocráticos. Encontramos una cantidad parecida de regímenes políticos (entre 15 y 25) en aproximadamente todos los intervalos de datos del histograma. En el extremo superior, observamos que unos 25 países tenían un valor de democracia liberal superior a 0,8.
19.5.2 Cruce de variables
¿Qué niveles de calidad democrática tenían en 2010 las autocracias personales y las partidistas? Para responder a esta pregunta, utilizaremos principalmente dos variables del objeto qog_basic10, ya filtradas por el año 2010:
- Los niveles de democracia liberal:
vdem_libdem. - Tipo de régimen:
gwf_regimetype.
En el código siguiente, hemos realizado las siguientes operaciones:
- Filtrar los datos por el tipo de régimen (
gwf_regimetype) 2 (autocracias personales) y 4 (autocracias partidistas). - Visualizar en el eje horizontal de las \(x\) los datos de tipos de régimen (
gwf_regimetype), transformados como vector de carácter, y en el eje vertical de las \(y\), los niveles de democracia (vdem_libdem). - Visualizar el valor de cada observación con un texto (
geom_text()), que describa las iniciales del país (variableccodealp). Para poder ver más claramente el texto, sacudiremos su posición de manera aleatoria. - Pedir la media por cada categoría con
stat_summary(), en rojo.
qog_basic10 |>
filter(gwf_regimetype %in% c(2, 4)) |>
ggplot(aes(x = as.character(gwf_regimetype),
y = vdem_libdem)) +
geom_text(aes(label = ccodealp),
position = position_jitter(width = 0.2)) +
stat_summary(col = "red")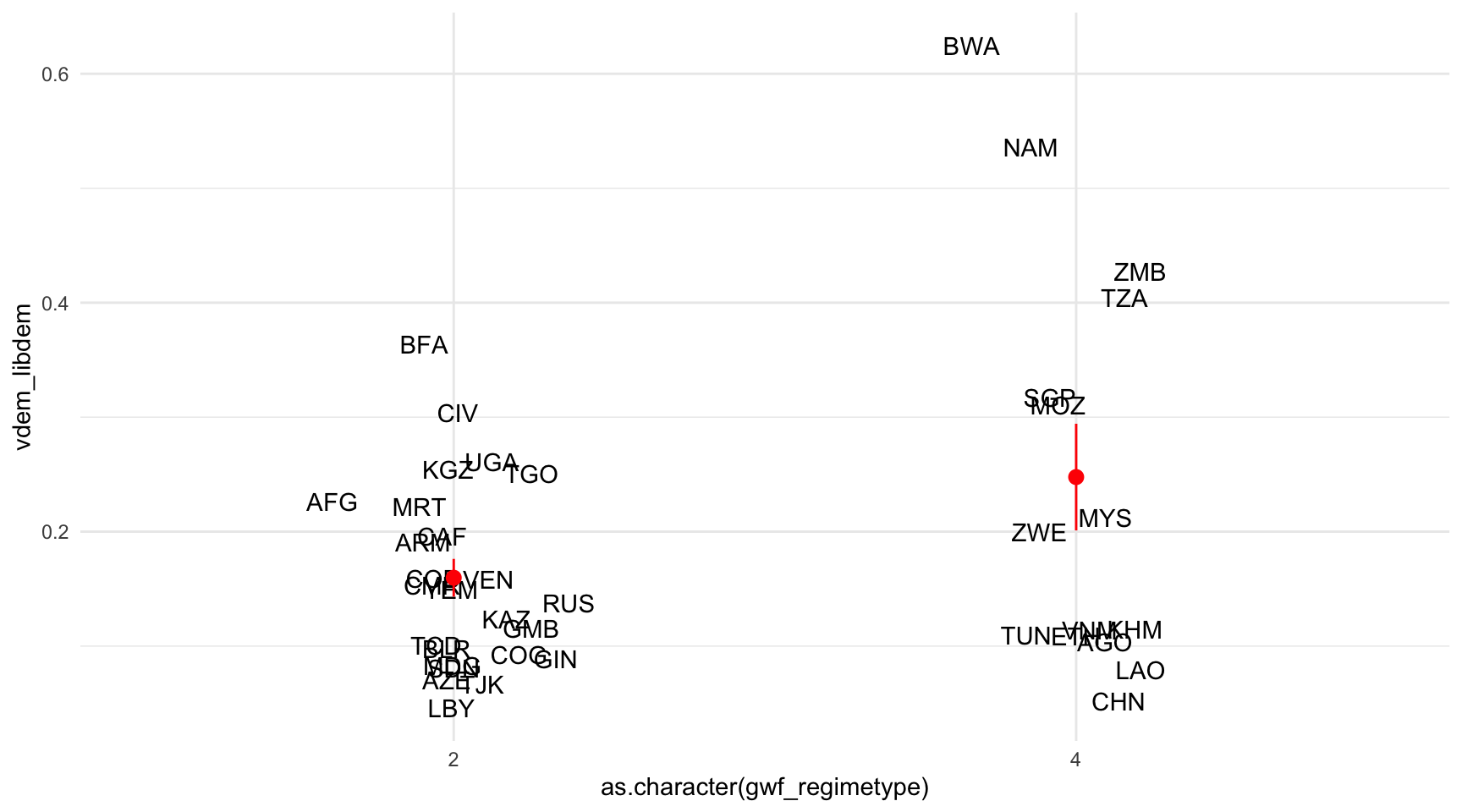
Fíjate cómo hemos incluido la función as.character() antes de la variable year y gwf_regimetype. Esta función nos permite indicar a R que entienda que estas variables las estamos tratando como categóricas, y no como simples variables continuas. Es decir, R entenderá que el valor 1 en la variable gwf_regimetype no es un número solo, sino que indica una categoría diferenciada, y lo tratará de forma diferente.
Según observamos en los datos de 2010, las autocracias partidistas son, de media, más democráticas que las autocracias personales. En el primer caso, la media se sitúa alrededor del 0,25, mientras que, en el segundo caso, la media se sitúa alrededor del valor de 0,15. Llama la atención la presencia de algunas autocracias partidistas que puntúan con un valor relativamente alto en el índice de democracia liberal, como son Botsuana y Namibia. En cambio, las autocracias personales no superan el valor de 0,4, siendo Burkina Faso el valor más alto.
Observa bien el gráfico anterior y compara los niveles de democracia de las oligarquías y las monarquías en el 2000.
19.5.3 Graficar una evolución temporal
¿Cómo evoluciona la democracia liberal en el mundo? En este apartado aprenderemos a ver la evolución temporal de una variable en países concretos como Estados Unidos y el Reino Unido. Por eso, de la base de datos de QoG que tenemos almacenada en el objeto qog_basic, necesitamos información diversa:
- Los niveles de democracia liberal:
vdem_libdem. - Año:
year.
En el código haremos las siguientes operaciones:
- Filtrar los datos del vector
cname_qogpara los países que nos interesan: Estados Unidos y el Reino Unido. - Visualizar en el eje horizontal de las \(x\) los años (
year) y en el eje vertical de las \(y\) los niveles de democracia (vdem_libdem). - Distinguir los datos de cada país (
cname_qog) con un color diferente. - Visualizar los datos con la geometría del diagrama de líneas (
geom_line()).
qog_basic |>
filter(cname_qog %in% c("United States", "United Kingdom")) |>
ggplot(aes(x = year, y = vdem_libdem, col = cname_qog)) +
geom_line()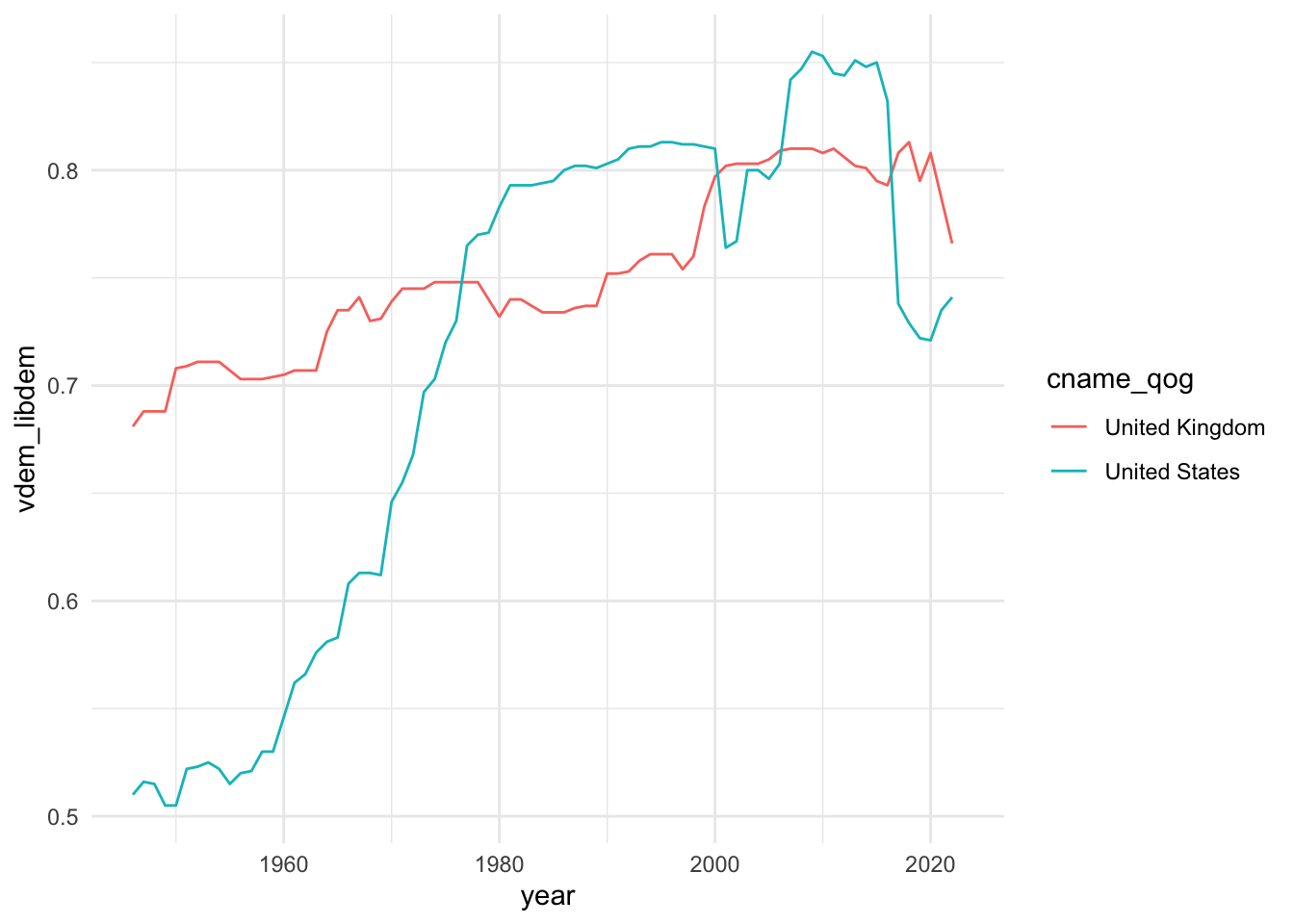
Ahora que sabes cómo graficar evoluciones temporales con variables continuas, y sin alejarte de los índices que crea VDem, busca en el libro de códigos el nombre de la variable que evalúa cómo de políticamente empoderadas están las mujeres, y haz un gráfico con los mismos países. Cambia los ?que correspondan al código siguiente para conseguirlo. Si quieres probar algo un poco más complicado, intenta añadir también los resultados provenientes de España.
qog_basic |>
filter(cname_qog %in% c("United States", "United Kingdom")) |>
ggplot(aes(x = year, y = ?, col = cname_qog)) +
geom_line()