20 CHES data
20.1 Introducción
La Chapel Hill Expert Survey (CHES) (Bakker et al., 2020) es una base de datos que ofrece información detallada sobre el posicionamiento político de los partidos de toda Europa en varios ámbitos, como el eje izquierda-derecha, la integración europea y la inmigración, entre otras. Esta base de datos es una iniciativa de la Universidad de Chapel Hill, en Estados Unidos, y lleva más de dos décadas clasificando sistemáticamente los partidos políticos. Empezó en 1999 con 14 países, se amplió a 24 países en 2006 y llegó a cubrir 31 países en 2019, aumentando el número de partidos evaluados de 143 a 277.
La metodología utilizada se basa en encuestas a expertos. Este proceso implica que cada partido político es evaluado por varios expertos en ciencias políticas, que puntúan el posicionamiento ideológico del partido en diferentes ámbitos. Los expertos seleccionados para participar en las encuestas son académicos e investigadores reconocidos en el campo de la política comparada, con un conocimiento profundo de los sistemas políticos y de los partidos de los países analizados. Los resultados obtenidos de las encuestas son después agregados y analizados para proporcionar una visión clara y sistemática del panorama político europeo, permitiendo comparaciones entre países y a lo largo del tiempo.
20.2 Descarga de datos
Para trabajar los datos de CHES, nos descargaremos el libro de códigos (Codebook) y los dos conjuntos de datos de 2019. Estos datos proporcionan la misma información, pero en dos niveles de análisis diferentes:
- Partidos políticos (versión en CSV de Dataset): la unidad de observación es el partido político.
- Expertos (versión en CSV de Expert-level Dataset): la unidad de observación es la evaluación de un partido político por parte de un experto.
Una vez descargados los dos conjuntos de datos en formato CSV, situaremos los archivos en el directorio de trabajo e importaremos los datos a R a través del código siguiente. Tendremos que utilizar la función read_csv() del paquete readr, que cargaremos junto con todos los otros paquetes que usaremos en esta actividad (Wickham, François, et al., 2023; Wickham, Hester, et al., 2023; Wickham, 2023; Wickham et al., 2024).
Una opción alternativa es descargar los datos directamente de su localización en internet. Solo habrá que indicar el enlace como valor de carácter dentro de la función.
20.3 Datos a nivel de partido político
En el conjunto de datos que hemos almacenado en el objeto ches, cada observación corresponde a un partido político diferente. Las primeras observaciones corresponden al país 1 (que si lo buscamos en el libro de códigos, veremos que corresponden a Bélgica) y tiene partidos políticos como el PS, el SP/SPA, etc. Cada partido político tiene un código numérico de identificación, especificado en la columna party_id y del quinto vector en adelante observamos el posicionamiento ideológico de cada partido político en determinados temas. Por ejemplo, eu_position clasifica los partidos en función de su posicionamiento hacia la Unión Europea (UE), siendo 1 muy desfavorable y 7 muy favorable. Como vemos, el partido que tiene un posicionamiento más desfavorable en la UE es VB (Vlaams Belang), con una puntuación de 2,25.
ches
## # A tibble: 277 × 55
## country eastwest party party_id eu_position eu_position_sd eu_salience
## <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 1 1 PS 102 6.08 0.289 4.27
## 2 1 1 SP/SPA 103 6 0.426 4.18
## 3 1 1 ECOLO 104 6.58 0.515 4.82
## 4 1 1 AGALEV 105 6.58 0.515 4.82
## 5 1 1 PRL/MR 106 6.5 0.674 5.09
## 6 1 1 VLD/PVV 107 6.83 0.389 5.09
## 7 1 1 PSC/CDH 108 6.42 0.793 4.36
## 8 1 1 CDV 109 6.58 0.669 4.73
## 9 1 1 VU/NVA 110 4.25 0.965 4.27
## 10 1 1 VB 112 2.25 0.622 4.73
## # ℹ 267 more rows
## # ℹ 48 more variables: eu_dissent <dbl>, eu_blur <dbl>, eu_cohesion <dbl>,
## # eu_foreign <dbl>, eu_intmark <dbl>, eu_budgets <dbl>, eu_asylum <dbl>,
## # lrgen <dbl>, lrecon <dbl>, lrecon_sd <dbl>, lrecon_salience <dbl>,
## # lrecon_dissent <dbl>, lrecon_blur <dbl>, galtan <dbl>, galtan_sd <dbl>,
## # galtan_salience <dbl>, galtan_dissent <dbl>, galtan_blur <dbl>,
## # immigrate_policy <dbl>, immigrate_salience <dbl>, …20.3.1 Exploración de los datos
En lugar de estudiar el posicionamiento de los partidos políticos de Bélgica, en este tutorial examinaremos más a fondo los partidos políticos en España. Con el código siguiente, crearemos un nuevo objeto llamado ches_es, donde tendremos que:
- Filtrar por el número de país, según la clasificación del libro de códigos. Vemos que España está identificada con el número 5.
- Seleccionar las variables que nos interesan.
Recuerda que es importante tener a mano el libro de códigos de la base de datos CHES. Dentro del documento encontrarás más información de las variables que acabamos de seleccionar, como EU_POSITION o LRECON.
Ahora que has visto cómo filtrar solo los datos para España, filtra la base de datos para que solo tenga datos de Francia haciendo los cambios que tocan en el código siguiente:
ches_fr <- ches |>
filter(country == ?) |>
select(party, eu_position, lrecon, galtan, multiculturalism, environment)Si hemos hecho bien la operación anterior, el objeto tendrá que contener solo los datos de los partidos de España. Reproduciremos el objeto para comprobarlo.
ches_es
## # A tibble: 13 × 6
## party eu_position lrecon galtan multiculturalism environment
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 PSOE 6.80 3.8 2.93 4.33 3.8
## 2 PPP 6.47 7.93 8 7.87 7.33
## 3 IU 5.29 1.8 2.2 3.2 3.2
## 4 PNV 6.40 5.80 5.67 5.25 4.92
## 5 ERC 5.53 3.40 2.87 4 3.77
## 6 BNG 5.55 2.92 3.08 3.3 3.78
## 7 CC 6.38 6.36 6.31 6.25 5.45
## 8 EHB 4.5 1.47 1.75 2.90 2.40
## 9 Podemos 5.27 2.13 1.33 2.27 2.27
## 10 Cs 6.73 7.40 5.47 6.64 6.71
## 11 Vox 3.27 9.33 9.67 8.67 8.80
## 12 Pais 5.87 2.8 1.67 2.64 2.07
## 13 PdeCat 5.13 6.87 5.87 6.62 6.07Hagámonos, ahora, algunas preguntas sobre los datos, con funciones que conocemos:
- ¿Cuál es la media en el posicionamiento izquierda-derecha? Si nos fijamos en el libro de códigos, el valor 0 correspondería a la extrema izquierda (denominada también izquierda radical) y el valor 10, a la extrema derecha (denominada también derecha radical).
mean(ches_es$lrecon)
## [1] 4.770273- ¿Cuál es el partido que tiene una posición más desfavorable en la Unión Europea? Si nos fijamos en el libro de códigos, el valor 1 correspondería a fuertemente desfavorable y el valor 7, a fuertemente favorable.
ches_es[ches_es$eu_position == min(ches_es$eu_position), ]
## # A tibble: 1 × 6
## party eu_position lrecon galtan multiculturalism environment
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Vox 3.27 9.33 9.67 8.67 8.80- ¿Y el partido que tiene una posición más favorable en el multiculturalismo? Si nos fijamos en el libro de códigos, el valor 0 significa que el partido está a favor del multiculturalismo y el valor 10, que está en contra.
ches_es[ches_es$multiculturalism == min(ches_es$multiculturalism), ]
## # A tibble: 1 × 6
## party eu_position lrecon galtan multiculturalism environment
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Podemos 5.27 2.13 1.33 2.27 2.27¿Cuál es el partido en España con posiciones más desfavorables respecto al medio ambiente? Recuerda hacer estos pasos:
- Consultar cómo está construida la variable en el libro de códigos.
- Buscar cuál es el nombre de la variable en cuestión en el marco de datos.
- Modificar el código anterior para obtener el resultado.
20.3.2 Visualización de datos
Un ejercicio interesante con los datos de partidos políticos es ver cómo están alineados los ejes en dos temáticas determinantes. Por eso podemos crear un diagrama de dispersión, que nos muestra cómo están relacionadas dos variables numéricas entre sí. A continuación, veremos la ubicación ideológica de todos los partidos españoles en el eje económico (0, extrema derecha y 10, extrema izquierda) y en la posición respecto a la integración de los inmigrantes o refugiados (0, a favor de la multiculturalidad y 10, a favor de la asimilación).
Para hacerlo, utilizaremos las funciones del paquete ggplot2 de la manera siguiente:
- En el eje de las \(x\) ubicamos
lrecon(la ubicación en el eje económico). - En el eje de las \(y\) ubicamos
multiculturalism(la posición integración/multiculturalidad). - Como geometría, usaremos el
geom_text(), que permite graficar con los nombres de los partidos (party). Esta geometría solo se puede usar cuando los nombres de las observaciones son de pocos caracteres, como es el caso. - Como son variables donde el mínimo es 0 y el máximo es 10, también especificaremos los límites de los ejes del gráfico con la función
lims().
ches_es |>
ggplot(aes(x = lrecon, y = multiculturalism)) +
geom_text(aes(label = party)) +
lims(x = c(0, 10), y = c(0, 10))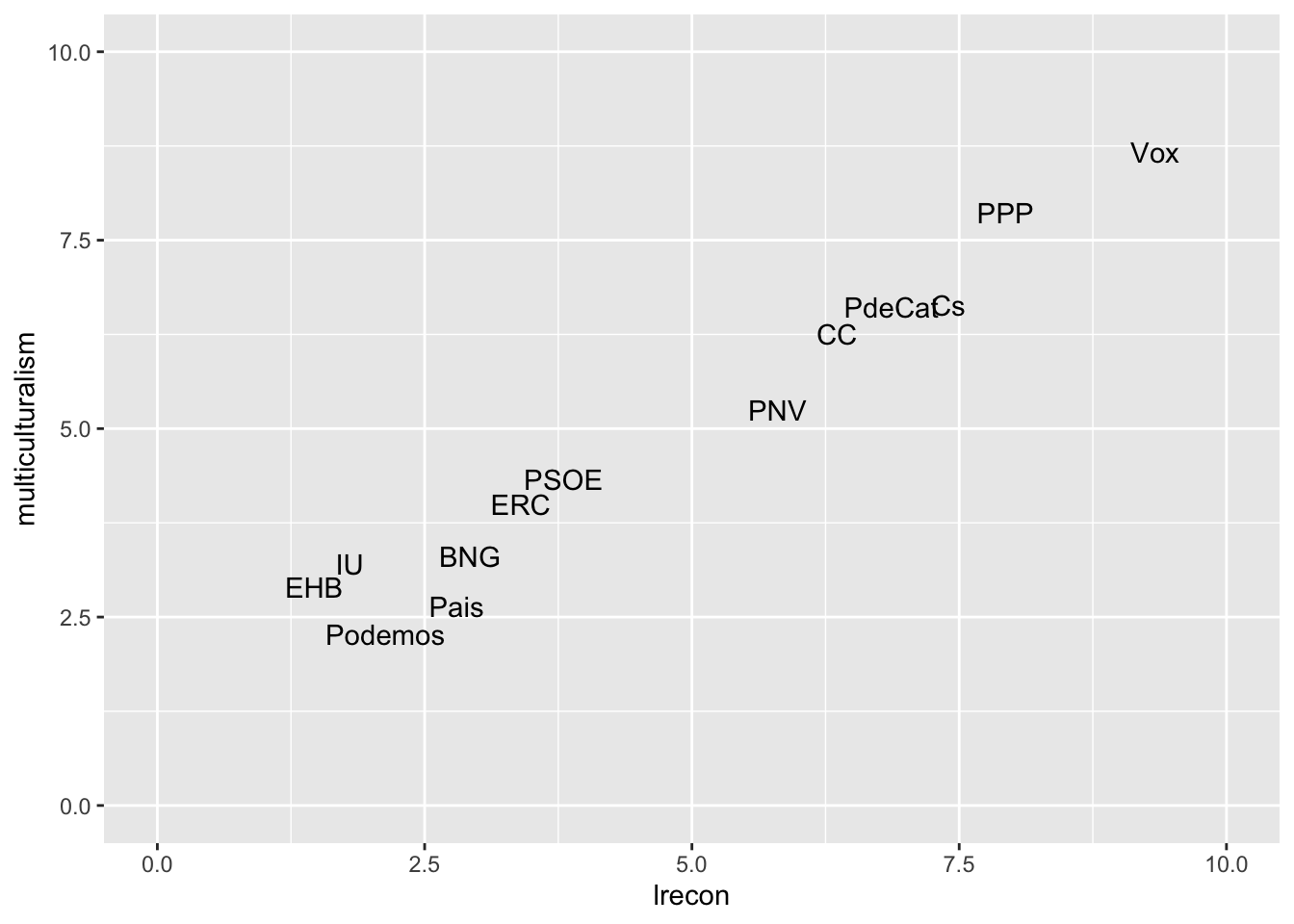
Como podemos ver en este gráfico, parece que hay una correlación bastante fuerte entre la preferencia de multiculturalidad y el eje económico. Vemos que VOX queda en el margen superior derecho (derecha económica y asimilación cultural), mientras que Bildu y Podemos quedan en el margen izquierdo (izquierda económica y multiculturalidad).
Ahora intenta hacer un gráfico de dispersión con dos variables diferentes del conjunto de datos.
ches_es |>
ggplot(aes(x = ?, y = ?)) +
geom_text(aes(label = party))20.4 Datos a nivel de codificador
Veamos el otro conjunto de datos que hemos descargado. Concretamente, el que hemos almacenado en el objeto ches_exp, donde cada observación corresponde a la valoración que hace un experto de un determinado partido político. La primera observación de los datos, por ejemplo, corresponde a la valoración que hace el experto con código de identificación 1 del partido GERB. Este experto puntuó este partido con un 7 en su posicionamiento respecto a la UE.
ches_exp
## # A tibble: 3,823 × 63
## id party party_name party_id position eu_salience eu_dissent eu_blur
## <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 1 GERB 2010 7 9 1 NA
## 2 1 2 BSP 2003 5 6 4 NA
## 3 1 3 DPS 2004 7 9 2 NA
## 4 1 4 Volya 2017 3 6 4 NA
## 5 1 5 NFSB 2014 3 6 4 NA
## 6 1 6 Ataka 2007 3 6 4 NA
## 7 1 7 BMRO 2005 5 6 2 NA
## 8 1 8 DB 2018 7 10 0 NA
## 9 1 9 DSB 2008 7 10 0 NA
## 10 1 10 Slavi Trifonov 2019 6 9 1 NA
## # ℹ 3,813 more rows
## # ℹ 55 more variables: lrecon <chr>, lrecon_blur <chr>, lrecon_dissent <dbl>,
## # lrecon_salience <dbl>, galtan <chr>, galtan_blur <dbl>,
## # galtan_dissent <dbl>, galtan_salience <dbl>, lrgen <dbl>,
## # immigrate_policy <dbl>, immigra_salience <dbl>, immigrate_dissent <dbl>,
## # multiculturalism <dbl>, multicult_salience <dbl>, multicult_dissent <dbl>,
## # redistribution <dbl>, redist_salience <dbl>, environment <dbl>, …Antes de continuar, hay que advertir que hay un error en esta base de datos. La variable país no existe, y la variable más parecida es la de cname (que se encuentra en las últimas columnas), que no nos sirve porque muchos países no tienen identificador en esta variable. Para resolverlo, aplicaremos el siguiente código, que nos permitirá crear una variable numérica con código de país en los mismos términos que tenemos en el libro de códigos.
ches_exp$country <- as.numeric(str_sub(ches_exp$party_id, end = -3))20.4.1 Exploración de los datos
A continuación, haremos el mismo procedimiento que en el apartado anterior y exploraremos los datos de España. Para este propósito, usaremos un código muy parecido y lo guardaremos en el objeto ches_exp_es:
El objeto ches_exp_es contiene la evaluación de cada uno de los expertos que han codificado los partidos políticos en España. En las primeras observaciones vemos las codificaciones en el PSOE. El experto con número de identificación 11 consideró que el PSOE tenía un posicionamiento hacia la UE (position) de 6 sobre 7 (por lo tanto, muy favorable), mientras que en el eje izquierda-derecha (lrecon) lo puntuó con un 4 (por lo tanto, en el centro, ligeramente a la izquierda). Vemos que hay una fuerte coincidencia entre los expertos, puesto que la mayoría ubican el PSOE con un 4 en el eje izquierda-derecha. También observamos otro hecho destacable: algunos expertos no se atreven a decir (seguramente porque lo desconocen) cuál es el nivel de importancia que dan las élites del partido a la interferencia rusa en los asuntos domésticos.
ches_exp_es
## # A tibble: 195 × 6
## id party_name position lrecon multiculturalism russian_interference
## <dbl> <chr> <dbl> <chr> <dbl> <dbl>
## 1 11 PSOE 6 4 5 1
## 2 3 PSOE 7 4 4 0
## 3 15 PSOE 7 4 2 0
## 4 12 PSOE 7 4 3 NA
## 5 5 PSOE 7 4 3 0
## 6 6 PSOE 7 4 3 NA
## 7 13 PSOE 6 4 5 NA
## 8 8 PSOE 7 3 1 NA
## 9 2 PSOE 7 3 5 0
## 10 4 PSOE 7 3 4 7
## # ℹ 185 more rowsBusca qué partidos políticos hay en Dinamarca. Para ello solo hace falta que busques qué valor numérico tiene Dinamarca en el libro de códigos y lo incluyas en la función filter. ¡No olvides las comillas!
¿Qué partidos hay en España? Los podemos examinar con unique().
unique(ches_exp_es$party_name)
## [1] "PSOE" "PP/A-PP" "IU/PCE" "PNV" "ERC" "BNG" "CC"
## [8] "EHB" "Podemos" "Cs" "Vox" "PdCAT" "Pais"Entonces, podemos ver cómo los expertos han puntuado un partido concreto. Por ejemplo, el PP (según la categorización de CHES, "PP/A-PP"). Los expertos ubican al PP de manera muy parecida al PSOE en el eje europeo (entre el 6 y el 7), mientras que lo ubican entre el 7 y el 9 en el eje izquierda-derecha. También observamos que muchos expertos no saben responder sobre la interferencia rusa, y los que lo hacen emiten juicios bastante diferentes entre ellos.
ches_exp_es |>
filter(party_name == "PP/A-PP")
## # A tibble: 15 × 6
## id party_name position lrecon multiculturalism russian_interference
## <dbl> <chr> <dbl> <chr> <dbl> <dbl>
## 1 3 PP/A-PP 7 8 8 0
## 2 14 PP/A-PP 7 8 4 NA
## 3 13 PP/A-PP 6 8 8 NA
## 4 15 PP/A-PP 7 9 10 0
## 5 4 PP/A-PP 7 8 6 5
## 6 1 PP/A-PP 6 7 9 0
## 7 7 PP/A-PP 6 7 10 4
## 8 12 PP/A-PP 7 9 8 NA
## 9 11 PP/A-PP 6 8 7 1
## 10 5 PP/A-PP 6 7 8 0
## 11 2 PP/A-PP 7 8 8 0
## 12 9 PP/A-PP 6 8 10 2
## 13 6 PP/A-PP 6 8 8 NA
## 14 8 PP/A-PP 6 8 9 NA
## 15 10 PP/A-PP 7 8 5 620.4.2 Visualización de los datos
Seguidamente, podemos visualizar más en detalle las respuestas de los expertos. Nos fijaremos en su respuesta a la variable de la interferencia rusa (russian_interference). Esta variable, recordémoslo, juzga cuál es el nivel de importancia que dan las élites de un partido determinado a la interferencia rusa en los asuntos domésticos, donde 0 es la mínima importancia y 10, la máxima. Ya hemos visto anteriormente que esta pregunta es problemática. Primero porque es difícil de entender en el libro de códigos. Segundo, porque muchos expertos no responden. Y, finalmente, porque las respuestas son un poco dispersas. Ahora lo examinaremos con detalle.
A continuación, crearemos un diagrama de barras que muestra cuántos expertos han respondido a cada valor de la escala. Por eso, hemos hecho lo siguiente:
- Filtramos los datos de partido (
party_name) para el PP y el PSOE. - Seleccionamos las variables que se visualizan en el eje horizontal (
russian_interference) y en fill (party_name), donde indicamos que cada partido tendrá un color diferente. - La geometría será un diagrama de barras (
geom_bar()). - Estableceremos los límites máximo y mínimo de los gráficos.
- Crearemos dos gráficos, uno para cada partido.
ches_exp_es |>
filter(party_name %in% c("PP/A-PP", "PSOE")) |>
ggplot(aes(x = russian_interference, fill = party_name)) +
geom_bar() +
scale_x_continuous(limits = c(0, 10), breaks = 0:10) +
facet_wrap(.~party_name)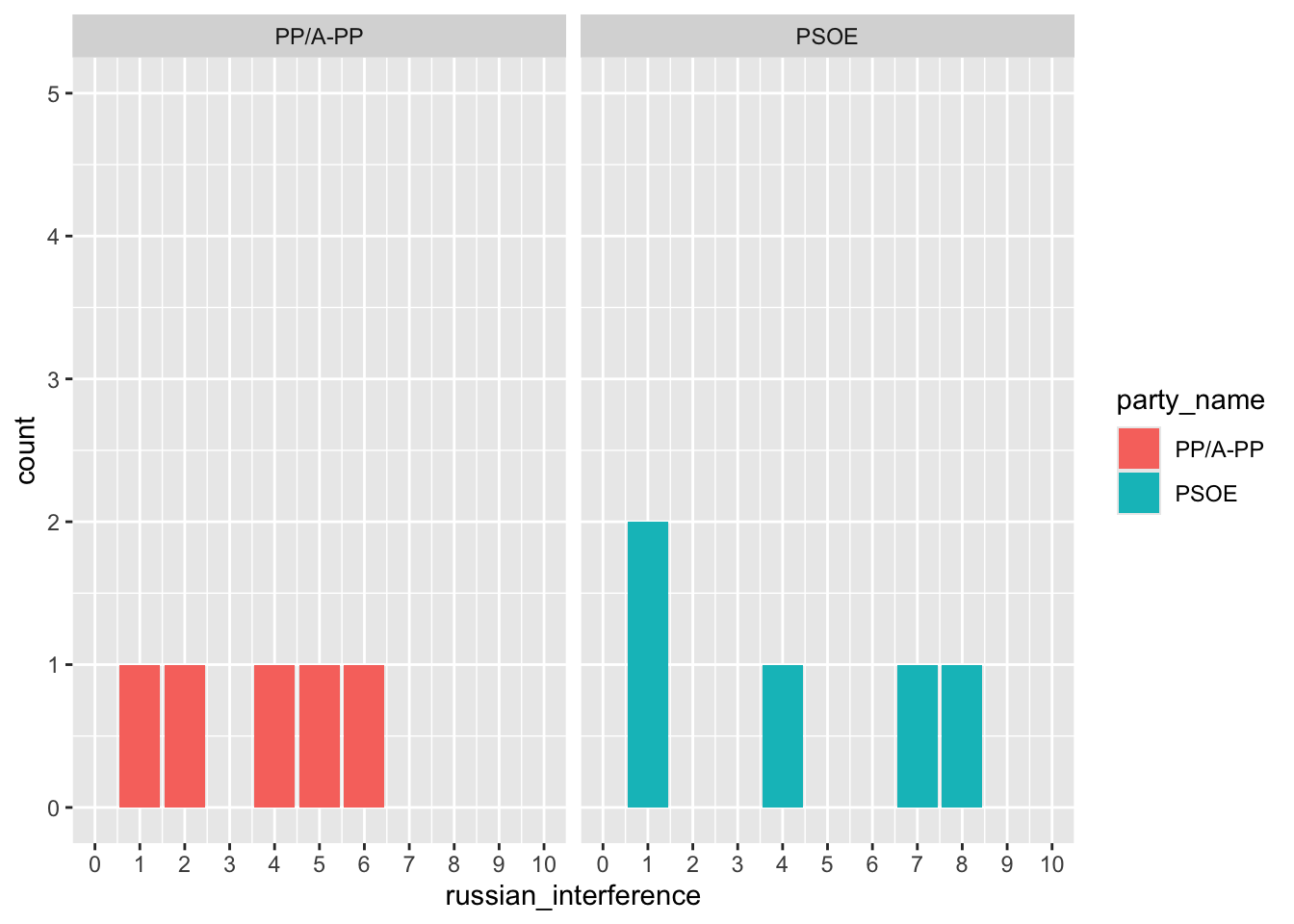
Observamos que solo hay dos expertos que coinciden en el hecho de que el PP tuvo un valor 1 en la variable de interferencia rusa. El resto de las respuestas son muy dispersas, lo cual nos hace pensar que esta variable probablemente no tendrá mucha fiabilidad (ni mucha validez).
20.5 Extra: ¿características de los expertos?
Muchas bases de datos publican también algunas de las características personales de los expertos que realizan las puntuaciones. Por ejemplo, en el conjunto de datos de expertos se incluye el género (gender), el año de nacimiento (dob), la autoubicación en el eje izquierda-derecha (lrecon_self) y la autoubicación en el eje GALTAN (galtan_self).
En este código, hemos incluido todas estas variables así como también el posicionamiento que cada experto da en el partido en cuestiones europeas. El primer experto, por ejemplo, que puntuó con un 6 al PSOE en su posicionamiento respecto a la UE, era una mujer que en 2019 tenía 45 años. El tercer experto puntuó al PSOE con un 7 y era un hombre de 39 años.
ches_exp_es2 <- ches_exp |>
filter(country == 5) |>
select(id, party_name, position, gender:galtan_self) |>
mutate(dob = 2019 - dob)
ches_exp_es2
## # A tibble: 195 × 7
## id party_name position gender dob lrecon_self galtan_self
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 11 PSOE 6 2 45 4 4
## 2 3 PSOE 7 2 34 4 3
## 3 15 PSOE 7 1 39 3 1
## 4 12 PSOE 7 2 31 4 2
## 5 5 PSOE 7 2 39 4 5
## 6 6 PSOE 7 1 41 5 2
## 7 13 PSOE 6 1 31 3 1
## 8 8 PSOE 7 2 68 1 1
## 9 2 PSOE 7 2 71 4 3
## 10 4 PSOE 7 1 33 4 4
## # ℹ 185 more rowsPodremos dar un vistazo a estas características de forma más detallada con View().
View(ches_exp_es2)