21 World Values Survey
Un dels temes clàssics dels estudis internacionals ha estat estudiar la diferència de valors entre diverses societats. A quin lloc del món tenen els valors més seculars? I on tenen valors més tradicionals? A quins països es troben les societats més religioses? On es valoren millor les institucions internacionals com les Nacions Unides? Amb l’objectiu de respondre aquestes i altres preguntes va sorgir el World Values Survey (WVS) (Inglehart et al., 2020), un programa internacional de recerca dedicat a l’estudi científic dels valors socials, polítics, culturals, econòmics i religiosos d’arreu del món.
El seu instrument principal de recerca és una enquesta representativa comparada que es duu a terme cada cinc anys i inclou preguntes relacionades amb múltiples disciplines d’investigació, com poden ser la sociologia, la ciència política, les relacions internacionals, l’economia, la salut pública, la demografia, la psicologia social i un llarg etcètera. A més, la WVS ha estat durant anys l’únic estudi acadèmic que cobria de manera àmplia el planeta, ja que ha fet enquestes tant als països més desenvolupats i rics com en aquells més pobres, capturant així les variacions culturals del món.
21.1 Descarregar i explorar les dades
La WVS té un motor propi d’anàlisi en línia, que pot ser molt útil per navegar de forma exploratòria per les seves onades, els països on han fet les enquestes i les preguntes que han realitzat. Per entrar-hi, cal anar a l’apartat Online Analysis, dins de la secció “Data and Documentation” de la seva pàgina web. Per utilitzar les dades haurem de seleccionar:
- L’onada de l’enquesta (2017-2022, per exemple).
- Els països dels quals volem dades.
- Les variables. En aquest camp, podem començar a teclejar algun nom en anglès (per exemple, “Enviro…”) i un desplegable ens mostrarà totes les variables que coincideixen amb el nom.
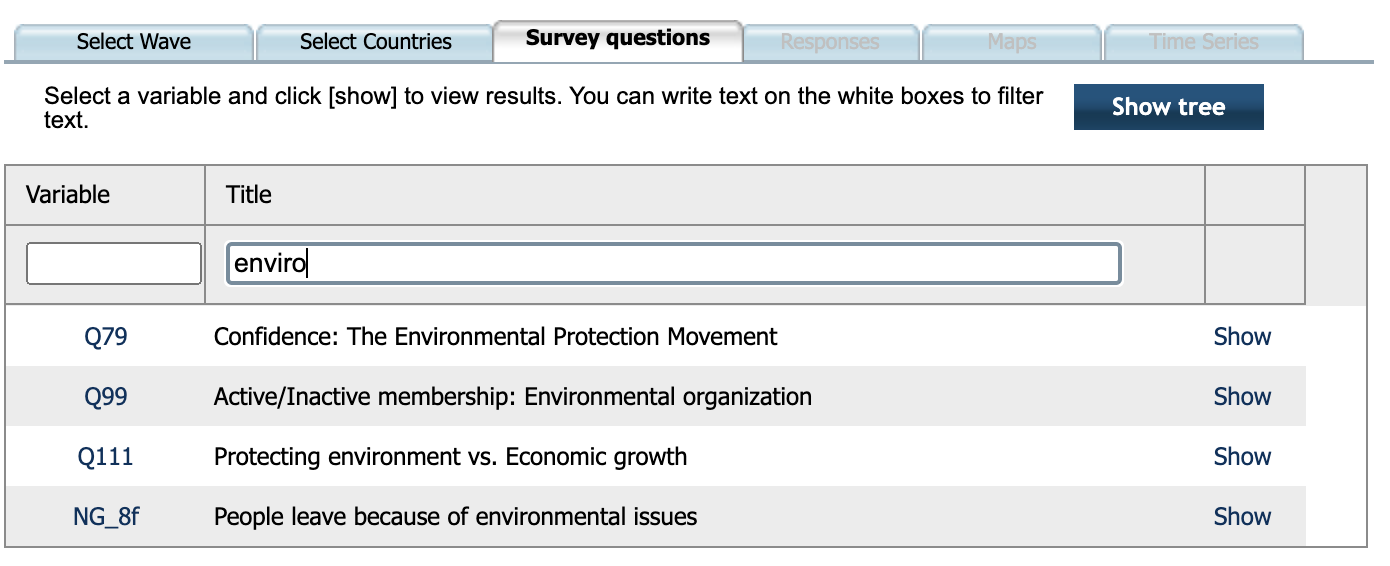
L’altra opció, que s’explica en detall en aquest mòdul, és descarregar-se les dades a través de l’apartat Data Download. En el mateix desplegable de l’esquerra, seleccionarem a continuació Time Series (1981-2022) i ens portarà a una pàgina que conté tota la documentació. Una vegada dins, podem descarregar-nos els fitxers que necessitem:
- A la secció Codebook & Results, descarregarem tota la documentació. En particular, WVS Time Series List of Variables and equivalences 1981 2022 v3.1 (Excel), on es troba la descripció de totes les variables.
- A la secció Longitudinal Data Files (vegeu imatge de la dreta), farem clic a l’enllaç de
WVS TimeSeries 1981 2022 Rds v4.0 zip, que queda cap a la part final de la pàgina web1.
1 hem optat per la descàrrega del fitxer en rds perquè és un dels formats que permet reduir de forma més considerable el pes de la informació que utilitzarem.
Això ens portarà a una nova pàgina que ens demana els motius de la descàrrega. Simplement cal que posem les nostres dades i les raons per les quals volem utilitzar les dades. Podeu emplenar-lo de la forma següent i a Brief descripcion, indicar “Undergraduate course assignment at UOC”:
Una vegada superat aquest tràmit, descarregarem un fitxer .zip que conté un fitxer .rds anomenat wvs_TimeSeries_4_0.rds, que és on hi ha totes les dades que utilitzarem. Ubicarem aquest fitxer en el directori de treball i el carregarem amb la funció read_rds() del paquet readr juntament amb els altres paquets que necessitarem (Wickham, François, et al., 2023; Wickham, Hester, et al., 2023; Wickham et al., 2024):
Recorda que per utilitzar un paquet, aquest ha d’estar prèviament instal·lat a RStudio. Si no has instal·lat algun d’aquests paquets, ara és el moment de fer-ho:
install.packages(c("dplyr", "readr", "ggplot2"))wvs <- read_rds("WVS_TimeSeries_4_0.rds")L’arxiu ocupa més de 70 Mb, per la qual cosa és possible que aquest procés trigui una mica més del que estem acostumats.
21.2 Exploració de les dades
La base de dades longitudinal de la WVS conté dades d’enquesta des del 1981 fins a l’actualitat en diversos països del món. En la versió descarregada per realitzar aquest mòdul tutorial, veiem que el marc de dades té 450.869 observacions i 1.045 variables. Ho obtenim teclejant wvs. Això significa que, en total, al llarg dels anys la WVS ha entrevistat gairebé mig milió de persones de tot el món, ja que cada observació és una entrevista.
En aquests conjunts de dades tan descomunals, una bona opció és limitar el nombre de columnes de les dades amb els claudàtors i, acte seguit, utilitzar la funció glimpse() per veure el llistat de les primeres columnes del marc de dades. En aquest exemple, hem reduït les dades a 20 columnes.
glimpse(wvs[, 1:20])
## Rows: 450,869
## Columns: 20
## $ version <chr> "4-0-0", "4-0-0", "4-0-0", "4-0-0", "4-0-0", "4-0-0", "4…
## $ doi <chr> "doi:10.14281/18241.22", "doi:10.14281/18241.22", "doi:1…
## $ S002VS <dbl+lbl> 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4…
## $ S003 <dbl+lbl> 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8…
## $ COUNTRY_ALPHA <chr> "ALB", "ALB", "ALB", "ALB", "ALB", "ALB", "ALB", "ALB", …
## $ COW_NUM <dbl+lbl> 339, 339, 339, 339, 339, 339, 339, 339, 339, 339, 33…
## $ COW_ALPHA <chr> "ALB", "ALB", "ALB", "ALB", "ALB", "ALB", "ALB", "ALB", …
## $ S004 <dbl+lbl> -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, …
## $ S006 <dbl+lbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, …
## $ S007 <dbl+lbl> 80420001, 80420002, 80420003, 80420004, 80420005, 80…
## $ S008 <dbl+lbl> -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, …
## $ mode <dbl+lbl> 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6…
## $ S010 <dbl+lbl> 60, 64, 75, 75, 90, 140, 130, 60, 130, 60, 6…
## $ S011A <dbl+lbl> -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, …
## $ S011B <dbl+lbl> 10.30, 10.50, 14.35, 15.20, 17.00, 12.20, 10.00, 19.…
## $ S012 <dbl+lbl> -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, …
## $ S013 <dbl+lbl> 2, 3, 3, 1, 2, 3, 1, 1, 2, 2, 1, 3, 3, 1, 3, 2, 3, 1…
## $ S013B <dbl+lbl> -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, -4, …
## $ S016 <dbl+lbl> 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, …
## $ S016B <dbl+lbl> 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 10…Fixem-nos en alguns elements de les dades:
- A la variable
S002VShi apareix l’onada de l’enquesta. Observem que hi ha set valors i cada un d’ells correspon a una de les onades. Per tant, si volem obtenir les dades de la primera onada (1981-1984), haurem de filtrar el marc de dades pel valor 1.
unique(wvs$S002VS)
## <labelled<double>[7]>: Chronology of EVS-WVS waves
## [1] 4 3 6 5 7 2 1
##
## Labels:
## value label
## 1 1981-1984
## 2 1989-1993
## 3 1994-1998
## 4 1999-2004
## 5 2005-2009
## 6 2010-2014
## 7 2017-2022- A la variable
COUNTRY_ALPHAhi apareix el país. Ambcount()podem demanar un recompte de quantes observacions tenim de cada país i onada. I si les ordenem (amb l’argumentsort = T), trobem que l’enquesta més grossa va ser a Colòmbia, corresponent a la tercera onada de la WVS, amb 6.025 entrevistats.
count(wvs, COUNTRY_ALPHA, S002VS, sort = T)
## # A tibble: 310 × 3
## COUNTRY_ALPHA S002VS n
## <chr> <dbl+lbl> <int>
## 1 COL 3 [1994-1998] 6025
## 2 IND 6 [2010-2014] 4078
## 3 CAN 7 [2017-2022] 4018
## 4 ZAF 6 [2010-2014] 3531
## 5 TUR 4 [1999-2004] 3401
## 6 IDN 7 [2017-2022] 3200
## 7 EGY 5 [2005-2009] 3051
## 8 CHN 7 [2017-2022] 3036
## 9 COL 5 [2005-2009] 3025
## 10 EGY 4 [1999-2004] 3000
## # ℹ 300 more rows- Trobem altres variables, com
S010, que indica el total de minuts que va durar l’enquesta, oS016, que indica el codi d’idioma amb què es va fer l’enquesta. Per conèixer el significat d’aquestes variables, haurem de consultar el llibre de codis, que es troba en un dels arxius d’Excel que ens hem descarregat prèviament.
21.3 Orientació a la WVS
Totes les variables que ens poden resultar interessants de la WVS estan situades més enllà de la vintena variable del marc de dades que acabem d’observar. Com que hi ha una quantitat d’informació tan gran, serà molt més eficient per a nosaltres si ens acostumem a no visualitzar directament el marc de dades a la pantalla i utilitzem un dels arxius d’Excel que ens hem descarregat prèviament:
- WVS Time Series List of Variables and equivalences 1981 2022 v3.1 (Excel)
En aquest full d’Excel trobem totes les preguntes que s’han fet a la WVS, sigui quina sigui l’onada. Per exemple, podem voler examinar quines diferències hi ha en la confiança envers els altres que tenen les societats. Si busquem ‘Trust’ a l’Excel, veiem com un ítem de l’enquesta correspon a: ‘Most people can be trusted’ i té el codi de variable A165. A més, apareix a totes les onades de l’enquesta, com podem observar en el fet que està referenciada a les altres columnes (WVS7, WVS6, WVS5, etc.). En canvi, la següent pregunta ‘Do you think most people try to take advantage of you’ només apareix a la WVS6 i a la WVS4.

Per conèixer més detalls sobre qualsevol variable, podem consultar les seves categories amb unique().
unique(wvs$A165)
## <labelled<double>[5]>: Most people can be trusted
## [1] 2 -1 1 -2 -4
##
## Labels:
## value label
## -5 Missing: other
## -4 Not asked
## -2 No answer
## -1 Don't know
## 1 Most people can be trusted
## 2 Need to be very carefulEn aquest resultat, observem com es donen dues opcions de resposta: els enquestats poden respondre que “es pot confiar en la majoria de les persones” (most people can be trusted), assignat al valor 1. O bé que “s’ha d’anar amb molt de compte” (need to be very careful), assignat al valor 2.
També podem inspeccionar els detalls de la variable, així com la pregunta concreta de l’enquesta, a l’eina d’anàlisi online. Haurem de fer el següent:
- Accedim a l’eina online.
- Seleccionem una onada i un país qualsevol.
- Al cercador, busquem per exemple ‘trust’ i ens apareixerà la variable.
- Cliquem a ‘Show’.
A la pàgina que ens apareixerà, veurem a la part inferior la pregunta concreta.

Un cop ja hem recollit tota la informació de tall operacional de la variable, procedirem a eliminar els valors negatius de la variable. Per això:
- Demanarem que conservi els valors que siguin superiors a 0 (per tant, que elimini tots els valors negatius i conservi només els positius).
- Crearem un nou objecte,
wvs_A165.
wvs_A165 <- wvs |>
filter(A165 > 0) |>
select(COUNTRY_ALPHA, S002VS, A165)
wvs_A165
## # A tibble: 432,975 × 3
## COUNTRY_ALPHA S002VS A165
## <chr> <dbl+lbl> <dbl+lbl>
## 1 ALB 4 [1999-2004] 2 [Need to be very careful]
## 2 ALB 4 [1999-2004] 2 [Need to be very careful]
## 3 ALB 4 [1999-2004] 2 [Need to be very careful]
## 4 ALB 4 [1999-2004] 1 [Most people can be trusted]
## 5 ALB 4 [1999-2004] 2 [Need to be very careful]
## 6 ALB 4 [1999-2004] 2 [Need to be very careful]
## 7 ALB 4 [1999-2004] 2 [Need to be very careful]
## 8 ALB 4 [1999-2004] 2 [Need to be very careful]
## 9 ALB 4 [1999-2004] 2 [Need to be very careful]
## 10 ALB 4 [1999-2004] 2 [Need to be very careful]
## # ℹ 432,965 more rowsEl marc de dades wvs_A165 conté totes les respostes que, al llarg del temps, han donat els ciutadans de tots els països a la pregunta sobre el nivell de confiança cap a les altres persones (A165). Hem conservat, també, la variable de l’onada (S002VS).
21.4 Comparació entre països (I)
Una manera de fer comparacions de resposta entre països és amb un diagrama de barres. Cada barra serà un país diferent, mentre que l’alçada de les barres marcarà el nombre de persones que han fet una determinada resposta. Per diferenciar entre respostes, pintarem les barres de diferent color.
Si agafem el marc de dades anterior, wvs_A165, hi aplicarem el codi següent:
- Indiquem en quina onada volem fer la comparació. Hem marcat la 4 (1999-2004).
- Indiquem quins països volem comparar (hem triat Argentina, Japó i Espanya).
- Ubiquem la variable
COUNTRY_ALPHAa l’eix de les \(x\) i també indiquem que empleni (fill) les barres segons els diferents valors que pren la variableA165. - La geometria serà un diagrama de barres (
geom_bar()).
wvs_A165 |>
filter(S002VS == 4) |>
filter(COUNTRY_ALPHA %in% c("ARG", "JPN", "ESP")) |>
ggplot(aes(x = COUNTRY_ALPHA, fill = as.character(A165))) +
geom_bar()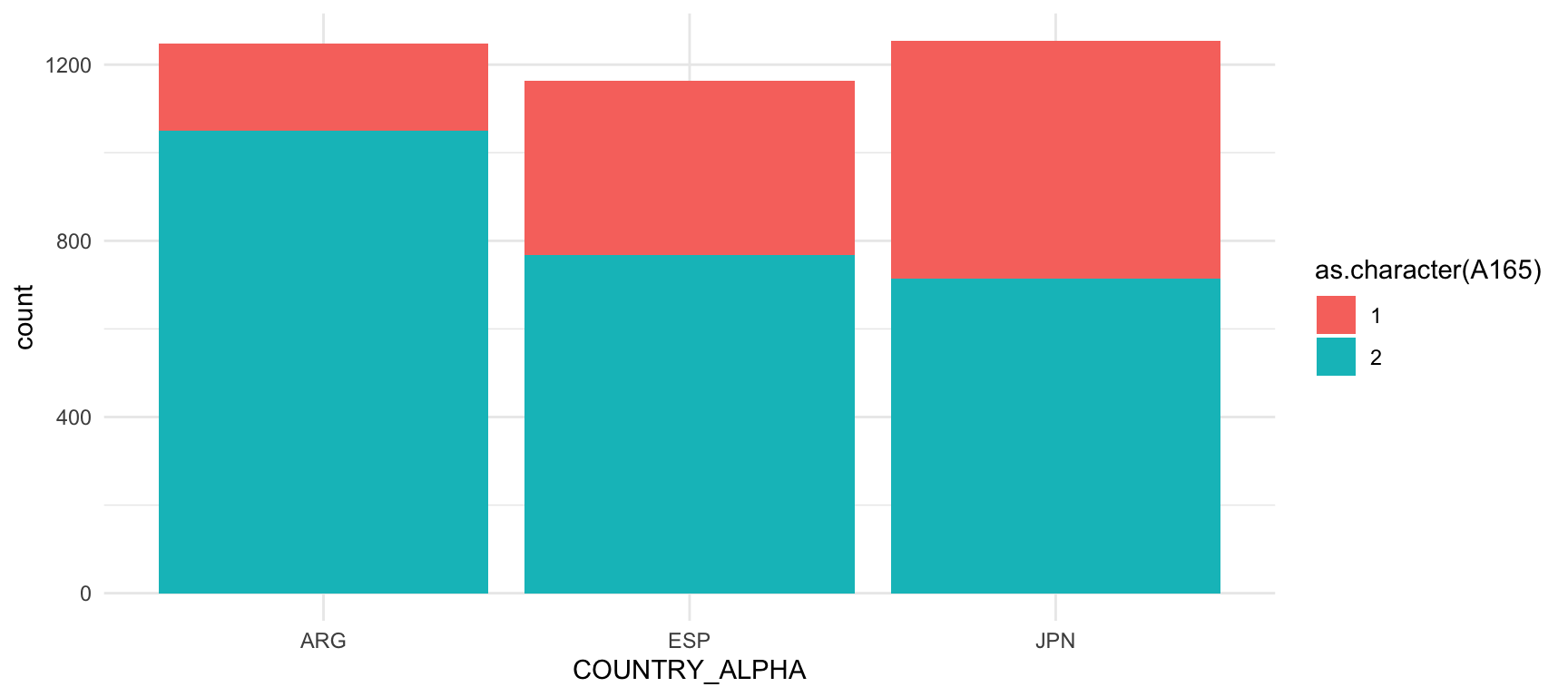
A la quarta onada de la WVS, es van entrevistar aproximadament unes 1.200 persones, tant a Argentina, com a Espanya i al Japó. Més de 1.000 argentins van respondre que s’ha d’anar en compte amb les persones, mentre que a Espanya van respondre en el mateix sentit unes 800 persones i al Japó, menys de 800. En general, sembla que les persones són més desconfiades a l’Argentina que no pas a Espanya o al Japó.
Habitualment, però, no ens interessarà tant el nombre de persones que hagin respost, sinó el percentatge de persones que hagin pres una opció o una altra. Per això farem una petita modificació al codi anterior, indicant position = "fill" a dins de la funció geom_bar().
wvs_A165 |>
filter(S002VS == 4) |>
filter(COUNTRY_ALPHA %in% c("ARG", "JPN", "ESP")) |>
ggplot(aes(x = COUNTRY_ALPHA, fill = as.character(A165))) +
geom_bar(position = "fill")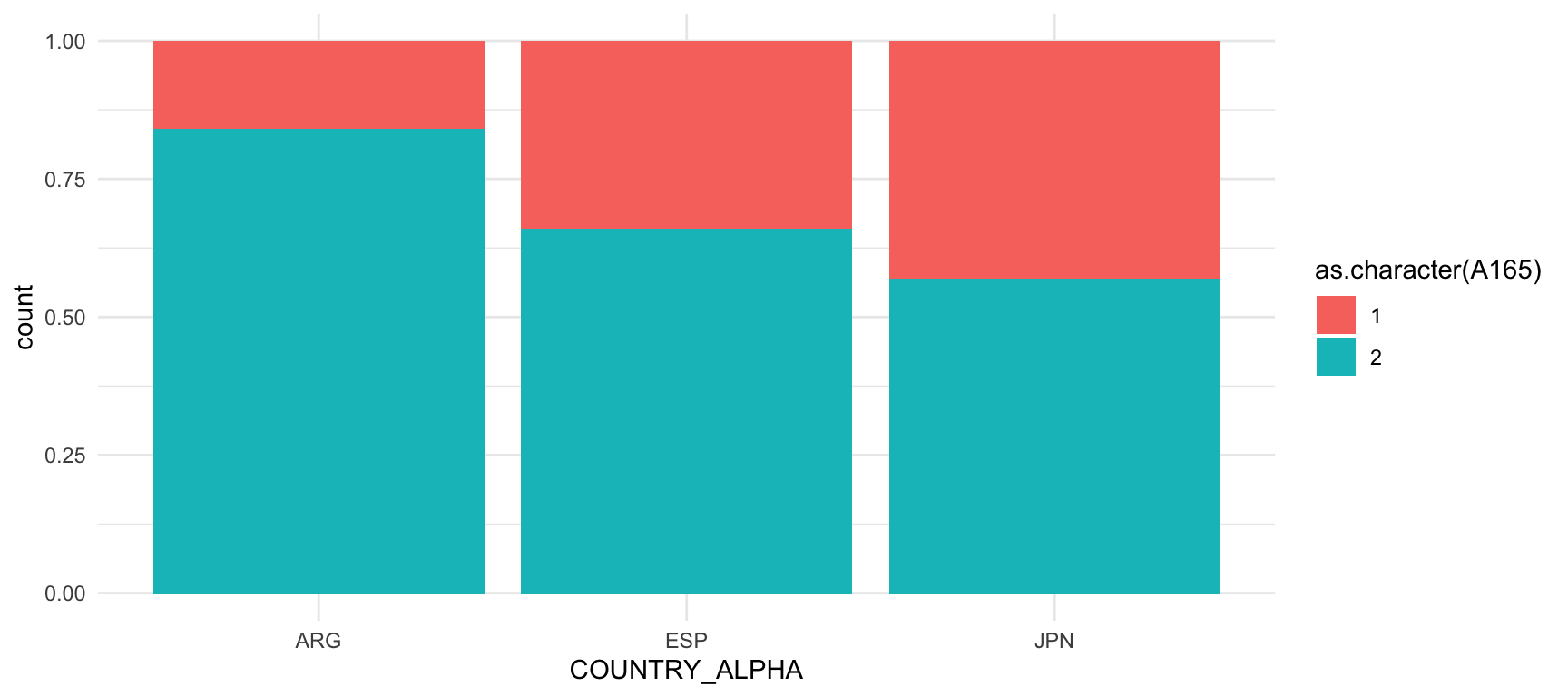
Observem que, a Argentina, un 80% dels entrevistats van declarar que s’ha d’anar en compte amb les persones, mentre que un 20% van respondre que es pot confiar en la majoria de les persones. A Espanya desconfien de les persones prop d’un 70% dels enquestats, mentre que al Japó prop d’un 60%.
Repeteix el mateix procés que hem fet, però triant una altra variable i uns altres països. Per fer això, només cal que canviïs les ? per la variable i els països que vulguis.
wvs_???? <- wvs |>
filter(????? > 0) |>
select(COUNTRY_ALPHA, S002VS, ????)
wvs_??? |>
filter(S002VS == ????) |>
filter(COUNTRY_ALPHA %in% c("???", "???", "???")) |>
ggplot(aes(x = COUNTRY_ALPHA, fill = as.character(???))) +
geom_bar(position = "fill")21.5 Comparació entre països (II)
Vegem un altre exemple, però amb variables que, en lloc de dues categories, en tenen més. Podríem fer servir el mateix codi anterior, però comprovarem que el resultat no serà visualment tan satisfactori. Una altra opció és la que proposem a continuació. Agafem d’exemple la variable del grau de satisfacció amb la situació financera, que si ens hi fixem a l’Excel veurem que té com a codi C006. A continuació, observem les respostes de la variable amb unique().
unique(wvs$C006)
## <labelled<double>[14]>: Satisfaction with financial situation of household
## [1] 4 7 8 3 5 10 6 1 2 9 -1 -2 -4 -5
##
## Labels:
## value label
## -5 Missing; Unknown
## -4 Not asked
## -2 No answer
## -1 Don't know
## 1 Dissatisfied
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
## 7 7
## 8 8
## 9 9
## 10 SatisfiedEn aquest cas, és una variable que va de l’1 (gens satisfet) al 10 (molt satisfet). Per eliminar els valors negatius farem exactament el mateix procediment que abans. En aquest codi, hem creat l’objecte wvs_C006 que conté la variable país (COUNTRY_ALPHA), la variable de l’onada (S002VS) i la variable d’interès (C006).
wvs_C006 <- wvs |>
filter(C006 > 0) |>
select(COUNTRY_ALPHA, S002VS, C006)
wvs_C006
## # A tibble: 435,694 × 3
## COUNTRY_ALPHA S002VS C006
## <chr> <dbl+lbl> <dbl+lbl>
## 1 ALB 4 [1999-2004] 4 [4]
## 2 ALB 4 [1999-2004] 4 [4]
## 3 ALB 4 [1999-2004] 7 [7]
## 4 ALB 4 [1999-2004] 8 [8]
## 5 ALB 4 [1999-2004] 3 [3]
## 6 ALB 4 [1999-2004] 5 [5]
## 7 ALB 4 [1999-2004] 5 [5]
## 8 ALB 4 [1999-2004] 4 [4]
## 9 ALB 4 [1999-2004] 4 [4]
## 10 ALB 4 [1999-2004] 10 [Satisfied]
## # ℹ 435,684 more rowsPer visualitzar la distribució entre països, també utilitzarem el diagrama de barres, però amb alguns petits canvis:
- En primer lloc, filtrem per l’onada (4) i pels països d’Argentina i Japó.
- A l’eix de les \(x\) hi ubicarem la variable, mentre que emplenarem les barres segons el país.
- Demanarem un diagrama de barres (
geom_bar) amb l’atributposition = "dodge".
wvs_C006 |>
filter(S002VS == 4) |>
filter(COUNTRY_ALPHA %in% c("ARG", "JPN")) |>
ggplot(aes(x = C006, fill = COUNTRY_ALPHA)) +
geom_bar(position = "dodge")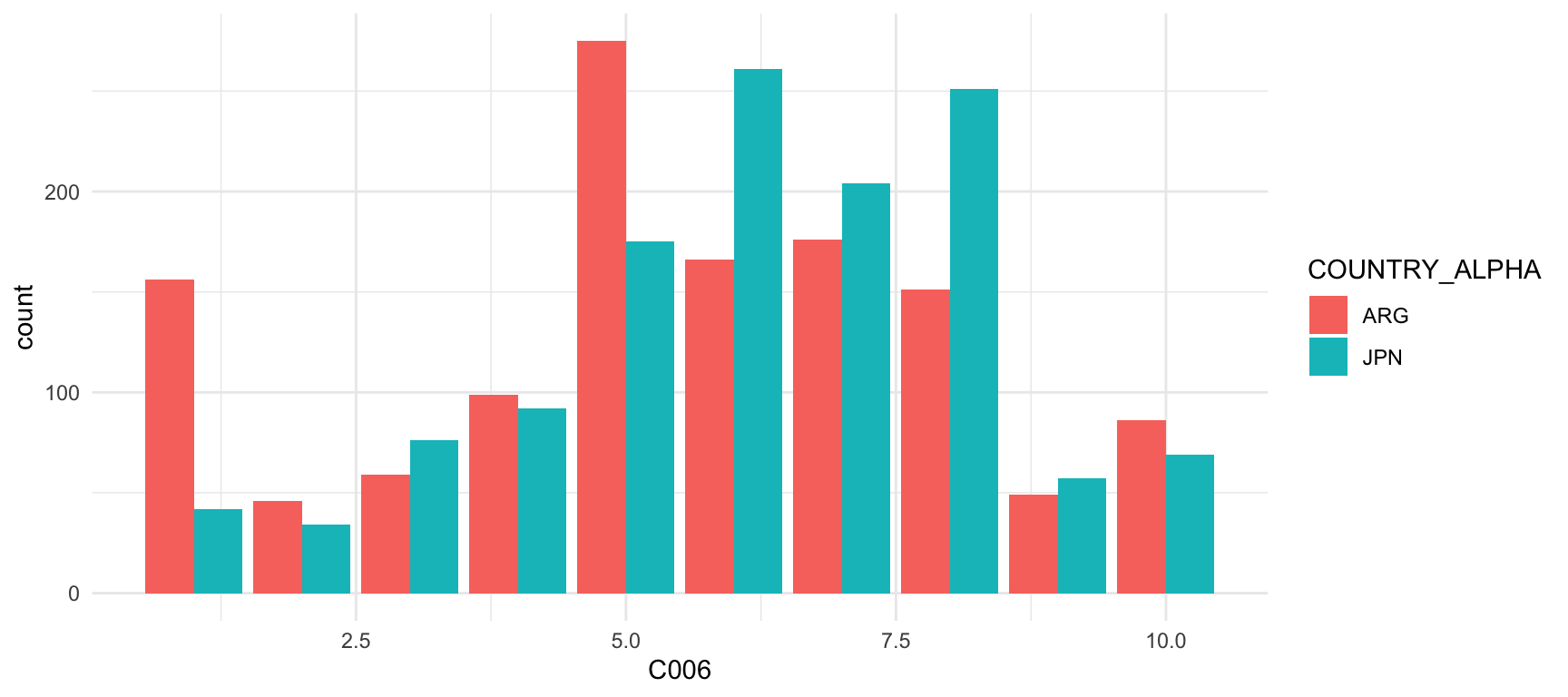
En aquest gràfic, observem el grau de satisfacció amb la situació financera a la llar a l’Argentina i el Japó cap a l’any 2000, sent 10 el valor màxim i 1 el valor mínim. Observem que en general els argentins estaven més descontents amb la seva situació financera, en comparació amb els japonesos.
Repeteix el mateix procés que hem fet, però triant una altra variable i uns altres països. Per fer això, només cal que canviïs les ? per la variable i els països que vulguis.
wvs_???? <- wvs |>
filter(????? > 0) |>
select(COUNTRY_ALPHA, S002VS, ????)
wvs_??? |>
filter(S002VS == ????) |>
filter(COUNTRY_ALPHA %in% c("???", "???")) |>
ggplot(aes(x = ???, fill = COUNTRY_ALPHA)) +
geom_bar(position = "dodge")21.6 Comparació temporal
En lloc de fer una comparació entre països en una onada concreta, l’altra opció és veure com han evolucionat els valors al llarg del temps. En aquest cas, la millor manera per veure l’evolució d’unes dades en el temps és el diagrama de línies. Una qüestió important que s’ha de tenir en compte és seleccionar alguna pregunta que tingui una certa longitud temporal i que s’hagi preguntat al llarg de diverses onades de la WVS. Per exemple, la variable E018 pregunta si el respecte per l’autoritat és positiu o negatiu.
Fixem-nos amb la variable. Oscil·la entre 1 i 3.
unique(wvs$E018)
## <labelled<double>[7]>: Future changes: Greater respect for authority
## [1] 2 1 3 -1 -2 -5 -4
##
## Labels:
## value label
## -5 Missing; Not available
## -4 Not asked
## -2 No answer
## -1 Don't know
## 1 Good thing
## 2 Don't mind
## 3 Bad thingNovament, eliminarem els valors negatius. En aquest codi, hem creat l’objecte wvs_E018, que conté la variable país (COUNTRY_ALPHA), la variable de l’onada (S002VS) i la variable d’interès (E018).
wvs_E018 <- wvs |>
filter(E018 > 0) |>
select(COUNTRY_ALPHA, S002VS, E018)
wvs_E018
## # A tibble: 427,155 × 3
## COUNTRY_ALPHA S002VS E018
## <chr> <dbl+lbl> <dbl+lbl>
## 1 ALB 4 [1999-2004] 2 [Don't mind]
## 2 ALB 4 [1999-2004] 2 [Don't mind]
## 3 ALB 4 [1999-2004] 2 [Don't mind]
## 4 ALB 4 [1999-2004] 2 [Don't mind]
## 5 ALB 4 [1999-2004] 2 [Don't mind]
## 6 ALB 4 [1999-2004] 1 [Good thing]
## 7 ALB 4 [1999-2004] 1 [Good thing]
## 8 ALB 4 [1999-2004] 1 [Good thing]
## 9 ALB 4 [1999-2004] 2 [Don't mind]
## 10 ALB 4 [1999-2004] 2 [Don't mind]
## # ℹ 427,145 more rowsEn aquest codi:
- Agafem els països.
- Agrupem les dades per país i onada.
- Demanem la mitjana, de manera que obtindrem les dades de la mitjana per país o onada.
- Posem \(x\) onada i \(y\) la mitjana i hi haurà una línia d’un color diferent per a cada país.
- Marquem la geometria
geom_line().
wvs_E018 |>
filter(COUNTRY_ALPHA %in% c("ARG", "JPN", "ESP")) |>
group_by(COUNTRY_ALPHA, S002VS) |>
summarize(mean = mean(E018, na.rm = T)) |>
ggplot(aes(x = S002VS, y = mean, col = COUNTRY_ALPHA)) +
geom_line()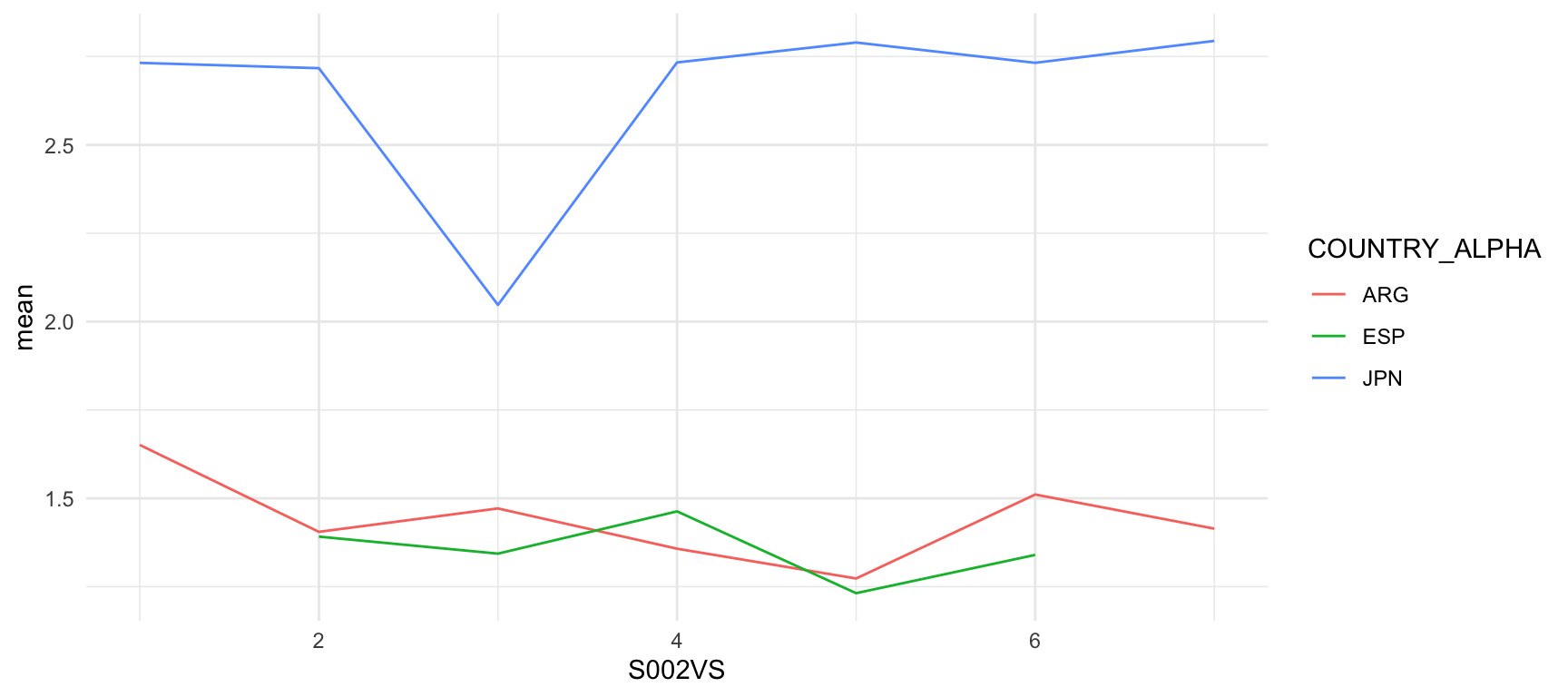
Repeteix el mateix procés que hem fet, però triant una altra variable i uns altres països. Per fer això, només cal que canviïs les ? per la variable i els països que vulguis.
wvs_???? <- wvs |>
filter(????? > 0) |>
select(COUNTRY_ALPHA, S002VS, ????)
wvs_???? |>
filter(COUNTRY_ALPHA %in% c("???", "???", "???")) |>
group_by(COUNTRY_ALPHA, S002VS) |>
summarize(mean = mean(???, na.rm = T)) |>
ggplot(aes(x = S002VS, y = mean, col = COUNTRY_ALPHA)) +
geom_line()