17 SDR Data
17.1 Introducció
En aquest mòdul treballarem amb les dades dels Objectius de Desenvolupament Sostenible (ODS). Els ODS són uns objectius presentats i avaluats per les Nacions Unides, que incideixen en molts contextos i matèries relacionades amb el desenvolupament, com el medi ambient i la sostenibilitat. Aquests objectius es classifiquen en 17 categories i més d’un centenar d’indicadors.
Més enllà de la seva rellevància política, la quantificació de moltes facetes del desenvolupament pot ser rellevant per analitzar les diferències existents entre països a través de la varietat d’indicadors. Aquest és el propòsit d’aquesta secció.

17.2 Baixar i explorar les dades amb Excel
Hi ha moltes maneres de treballar amb els ODS, ja que es troben disponibles en múltiples pàgines. Una opció és utilitzar alguna de les organitzacions que treballen amb aquestes dades, com el SDG Transformation Center que lidera l’economista Jeffrey Sachs. A la pàgina web d’aquest centre trobarem informes i també les dades actualitzades de cada any. A nosaltres ens interessa descarregar-nos els indicadors, que estan disponibles en format Excel. Per descarregar-los, seguirem aquesta ruta:
- Entrarem a l’edició de 2023 a la seva pàgina web.
- A la part inferior de la pàgina, buscarem la pestanya “Resources”.
- Clicarem el botó “Download Data”.
Alternativament, també pots descarregar l’últim informe a la secció de descàrregues del web Sustainable Development Report. Només cal clicar a “Acces full database”.
Les dades es descarreguen amb un arxiu de nom SDR2023-data.xlsx o similar. Obrirem aquest arxiu amb Excel o Google Spreadsheets, això ens permetrà obtenir una primera visió general del seu contingut. Si observem la part inferior del document, veurem que està organitzat en diverses pestanyes. En el cas de l’edició del 2023, el fitxer consta de sis fulls de càlcul. Cada full està organitzat de forma diferent i conté informació diversa sobre els ODS. Vegem les pestanyes, una per una.

- About: és la pàgina inicial, on s’explica què trobarem als altres fulls, i una descripció de tots els aspectes formals (com citar-la, llicència, etc.).
- Overview: es classifica cada país segons el grau d’acompliment de cada ODS i la seva evolució (positiva o negativa). És la part més divulgativa, ja que no s’hi ensenyen dades concretes, només tendències.
- Codebook: indica exactament què mesura cadascuna de les variables que trobarem en els altres fulls del document. Aquest full és indispensable perquè ens permetrà comprendre els detalls de cada variable.
- SDR2023 Data: és la pestanya on trobem de manera més detallada els indicadors del 2023.
- Raw data (time series): semblant a la pestanya anterior, però aquí s’hi afegeixen els indicadors d’anys anteriors, cosa que ens permetrà veure tendències temporals.
- Data for trends: hi trobem les puntuacions dels ODS per cada any calculats retroactivament amb sèries de dades anuals.
Les dades que ens interessen estan principalment ubicades a les pestanyes SDR 2023 Data i a Raw data (time series). I per entendre-les, serà imprescindible tenir en compte el llibre de codis, que es troba a la pestanya Codebook.
Ara que saps com està organitzada aquesta base de dades, busca a quin full hauries d’anar per trobar:
- El percentatge de fumadors respecte a la població major de 15 anys a l’estat espanyol el 2020.
- L’evolució de l’objectiu 15 de desenvolupament sostenible a Corea del Nord.
17.3 Importar-les a R
Un cop ja t’has orientat amb el document, el que faràs serà importar les dades a R; això et permetrà una anàlisi més eficient i ràpida de les dades. Per poder seguir correctament aquest mòdul, has de carregar els paquets dplyr, readr, ggplot2, readxl i stringr (Wickham, François, et al., 2023; Wickham, Hester, et al., 2023; Wickham, 2023; Wickham et al., 2024; Wickham & Bryan, 2023):
Recorda que per utilitzar un paquet, aquest ha d’estar prèviament instal·lat a RStudio. Si no has instal·lat algun d’aquests paquets, ara és el moment de fer-ho:
install.packages(c("dplyr", "readr",
"ggplot2", "readxl", "stringr"))Com que anteriorment ja ens hem descarregat l’arxiu dels ODS, ara només caldrà obrir un projecte a RStudio i ubicar l’arxiu d’Excel a la carpeta del projecte. L’edició del 2023 es veuria de la manera següent:

Per treballar aquest arxiu a R, cal tenir-lo emmagatzemat en un objecte. Per això importarem aquestes dades a dins l’objecte sdg utilitzant la funció read_xlsx(), que serveix per llegir arxius .xlsx. Aquesta funció pertany al paquet readxl, que haurem de tenir carregat per poder fer la importació. De la funció, utilitzarem dos arguments:
-
"SDR2023-data.xlsx": indiquem el nom del fitxer que volem importar. -
sheet = 4: indiquem que volem importar la quarta pestanya del document (és a dir, la pestanya SDR2023 Data)1.
1 Si no ho especifiquéssim, només ens carregaria el primer full de càlcul del fitxer.
sdg <- read_xlsx("SDR2023-data.xlsx", sheet = 4)Abans de començar a treballar amb l’objecte sdg, farem una segona acció que més endavant resultarà molt útil per treballar amb les dades. Importarem el tercer full de càlcul (sheet = 3), on es trobava el llibre de codis, i el guardarem a l’objecte codebook.
codebook <- read_xlsx("SDR2023-data.xlsx", sheet = 3)Tens algun problema a l’hora d’importar l’arxiu? El més probable és que no tinguis l’arxiu a la carpeta del projecte. Assegura’t que:
- Has creat un projecte (veuràs el títol del projecte a l’extrem dret superior del gràfic).
- Tens l’arxiu ubicat a la carpeta del projecte (a la finestra ‘Files’, assegura’t que estàs a la carpeta correcta i que l’arxiu en qüestió està ubicat en aquesta carpeta).
17.3.1 Cercador al llibre de codis
Amb les funcions d’R es pot crear un petit cercador, de manera que, si posem una paraula clau, ens retorni quins indicadors concrets existeixen per a aquesta paraula concreta. Aquest cercador l’hem creat de la manera següent:
- La construcció principal del codi és
codebook[ , ]. Com ja sabem, això significa que farem una selecció específica de files o de columnes de l’objectecodebook. - A les files, utilitzarem la funció
str_detect(), del paquet stringr, que transforma en TRUE tots els valors d’un vector que compleixen un determinat requisit. Especifiquem el vectorcodebook$Indicatori com a requisit especifiquem"Poverty"2. - També afegim el codi
!is.na(codebook$Indicator)que elimina els valors perduts.
2 Per entendre el seu funcionament, tecleja str_detect(codebook$Indicator, "Poverty") i fixa’t que retorna un vector lògic que indica TRUE, si a la fila Indicator hi surt la paraula Poverty i FALSE, quan no hi surt.
codebook[str_detect(codebook$Indicator, "Poverty") & !is.na(codebook$Indicator), ]
## # A tibble: 3 × 25
## IndCode SDG global oecd spillover trend trendoecd Indicator New
## <chr> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 sdg1_wpc 1 yes yes <NA> yes yes Poverty headc… Modi…
## 2 sdg1_lmicpov 1 yes yes <NA> yes yes Poverty headc… Modi…
## 3 sdg1_oecdpov 1 no yes <NA> <NA> yes Poverty rate … <NA>
## # ℹ 16 more variables: `Period for trend calculation` <chr>,
## # `Reference year` <dbl>, Direction <chr>, Optimum <dbl>,
## # `Green threshold` <dbl>, `Red threshold` <dbl>, `Lower bound` <dbl>,
## # `Justification for Optimum` <chr>, `UNSD match` <chr>, `UNSD target` <chr>,
## # dwldlink <chr>, Source <chr>, Reference <chr>, Description <chr>,
## # Imputation <chr>, Computation <chr>Si ens resulta més còmode veure les dades en una pestanya nova, podem envoltar el codi amb la funció View():
View(codebook[str_detect(codebook$Indicator, "Poverty") & !is.na(codebook$Indicator), ])Fixem-nos que ens ha retornat tres vectors que contenen informació de pobresa. Quan observem en detall el marc de dades resultant, veurem que corresponen a les variables següents:
-
sdg1_wpc: Poverty headcount ratio at $2.15/day (2017 PPP, %). -
sdg1_lmicpov: Poverty headcount ratio at $3.65/day (2017 PPP, %). -
sdg1_oecdpov: Poverty rate after taxes and transfers (%).
Si et dona algun error en aquest apartat, recorda que has de carregar els paquets:
-
library(readxl): permet llegir l’Excel. -
library(stringr): contéstr_detect(), que permet cercar caràcters.
Així, doncs, per buscar altres indicadors només caldrà que substitueixis al codi anterior la paraula “Poverty” per una altra que prefereixis. Si no surt cap resultat, prova d’introduir la paraula en lletra minúscula o intenta altres paraules semblants.
Busca quins indicadors hi ha sobre aigua (water) en aquesta base de dades. Recorda que:
- S’ha d’escriure en anglès.
- El cercador és sensible a les majúscules i les minúscules.
17.4 Exploració de dades
Una vegada carregades les dades a R, podem explorar-les una mica més en detall. Aquest procés d’exploració es divideix en dues fases: una exploració més general i una exploració més específica. En l’exploració general observarem tot el marc de dades, mentre que en l’exploració específica ens centrarem en variables concretes.
17.4.1 Exploració general
Tenim principalment dues maneres d’explorar un marc de dades. La primera consisteix a escriure el nom de l’objecte gdp a la consola.
sdg
## # A tibble: 206 × 666
## `Country Code ISO3` Country `2023 SDG Index Score` `2023 SDG Index Rank`
## <chr> <chr> <dbl> <dbl>
## 1 FIN Finland 86.8 1
## 2 SWE Sweden 86.0 2
## 3 DNK Denmark 85.7 3
## 4 DEU Germany 83.4 4
## 5 AUT Austria 82.3 5
## 6 FRA France 82.0 6
## 7 NOR Norway 82.0 7
## 8 CZE Czechia 81.9 8
## 9 POL Poland 81.8 9
## 10 EST Estonia 81.7 10
## # ℹ 196 more rows
## # ℹ 662 more variables: `Percentage missing values` <dbl>,
## # `International Spillovers Score (0-100)` <dbl>,
## # `Regional Score (0-100)` <dbl>, `International Spillovers Rank` <dbl>,
## # `Regions used for the SDR` <chr>, `Population in 2022` <dbl>,
## # `Goal 1 Dash` <chr>, `Goal 1 Trend` <chr>, `Goal 2 Dash` <chr>,
## # `Goal 2 Trend` <chr>, `Goal 3 Dash` <chr>, `Goal 3 Trend` <chr>, …Amb aquesta acció podem observar els elements següents:
- El marc de dades té 206 observacions i 666 (!) variables.
- Amb una vista de les primeres 10 observacions, constatem que a cada observació tenim dades d’un país diferent.
- Ens fixem que les observacions estan ordenades per la variable
2023 SDG Index Score, de manera que podem veure els països que puntuen més alt en l’SDG Index. - També veurem més o menys columnes del marc de dades segons la consola d’R sigui més o menys ampla.
La segona manera d’explorar les dades és amb la funció glimpse(). Aquesta funció és especialment útil en marcs de dades de moltes variables, ja que les desplega totes en format vertical i permet visualitzar només les primeres observacions de cada una d’elles. Així ens podem fer una idea del contingut de cada variable. A continuació, veiem només les primeres 20 variables, però si ho reprodueixes a la teva consola veuràs tota la llista de 666 variables.
glimpse(sdg)Rows: 206
Columns: 15
$ `Country Code ISO3` <chr> "FIN", "SWE", "DNK", "DEU", "…
$ Country <chr> "Finland", "Sweden", "Denmark…
$ `2023 SDG Index Score` <dbl> 86.76059, 85.98140, 85.68364,…
$ `2023 SDG Index Rank` <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10…
$ `Percentage missing values` <dbl> 2.061856, 3.092784, 1.030928,…
$ `International Spillovers Score (0-100)` <dbl> 73.73608, 67.30785, 68.00446,…
$ `Regional Score (0-100)` <dbl> 77.81407, 77.81407, 77.81407,…
$ `International Spillovers Rank` <dbl> 128, 139, 137, 144, 152, 148,…
$ `Regions used for the SDR` <chr> "OECD", "OECD", "OECD", "OECD…
$ `Population in 2022` <dbl> 5538263, 10517669, 5867977, 8…
$ `Goal 1 Dash` <chr> "green", "green", "green", "y…
$ `Goal 1 Trend` <chr> "↑", "↑", "➚", "↓", "➚", "➚",…
$ `Goal 2 Dash` <chr> "red", "red", "orange", "oran…
$ `Goal 2 Trend` <chr> "→", "→", "→", "→", "→", "→",…
$ `Goal 3 Dash` <chr> "yellow", "yellow", "yellow",…17.4.2 Exploració específica
Una vegada tenim una idea general sobre el contingut de les dades, podem fer una exploració més específica de variables concretes amb algunes funcions d’R. Per exemple, la funció table() permet obtenir un recompte de quantes categories existeixen en un vector de caràcter determinat. Si volem conèixer el nombre de països que hi ha en cadascuna de les regions de l’informe, només caldrà indicar dins de la funció que volem veure la columna Regions used for the SDR del marc de dades sdg.
table(sdg$`Regions used for the SDR`)
##
## E. Europe & C. Asia East & South Asia LAC MENA
## 27 21 29 17
## Oceania OECD Sub-Saharan Africa
## 12 38 49En el resultat observem que la regió que conté més països és l’Àfrica subsahariana amb 49.
Quan els vectors contenen espais, com és el cas de Regions used for the SDR, a l’hora de fer servir el vector haurem d’envoltar el seu nom amb l’accent obert (``) perquè R ho interpreti correctament. Fixa’t en l’exemple següent:
- En el primer cas, donarà error.
- En el segon cas, es reproduirà el vector.
sdg$Regions used for the SDR
sdg$`Regions used for the SDR`Hem pogut observar que el marc de dades conté molts vectors numèrics, per la qual cosa serà interessant conèixer algunes funcions per examinar-los amb facilitat. A continuació veiem algunes funcions que ens permeten resumir una variable concreta, com el màxim, el mínim, la mitjana o la mediana3. Observem, per exemple, quin és el valor màxim, el mínim, la mitjana i la mediana de la variable Press Freedom Index, que mostra el nivell de llibertat de premsa que tenen els països, sent 100 el valor teòric més alt possible i 0 el valor teòric més baix possible.
3 Quan demanis sumaris de les dades, no oblidis posar com a segon argument na.rm = TRUE. Aquest argument elimina els valors perduts a l’hora de fer els càlculs.
Quin és el valor màxim?
max(sdg$`Press Freedom Index (worst 0-100 best)`, na.rm = TRUE)
## [1] 95.18Quin és el valor mínim?
min(sdg$`Press Freedom Index (worst 0-100 best)`, na.rm = TRUE)
## [1] 21.72Quina és la mitjana?
mean(sdg$`Press Freedom Index (worst 0-100 best)`, na.rm = TRUE)
## [1] 57.84199Quina és la mediana?
median(sdg$`Press Freedom Index (worst 0-100 best)`, na.rm = TRUE)
## [1] 57.899Una altra opció és utilitzar funcions de visualització, que ens permeten representar les dades en un gràfic. La manera més habitual de representar una variable numèrica és l’histograma, que serveix per recomptar el nombre d’observacions que cauen en un interval concret de les dades. Introduirem el nom de la variable dins de la funció hist().
hist(sdg$`Press Freedom Index (worst 0-100 best)`)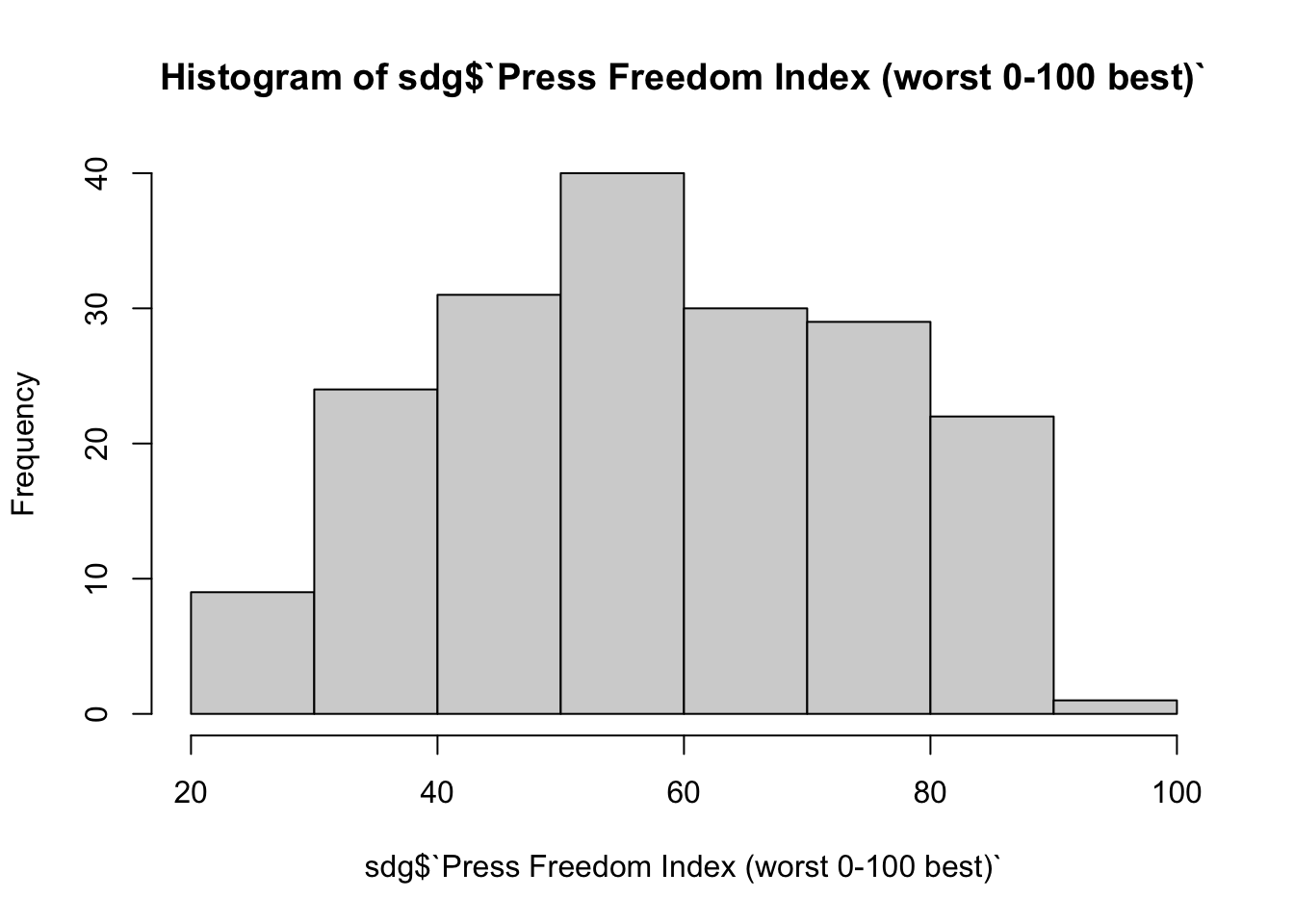
Amb el gràfic podem obtenir informació complementària que no podíem observar amb el resultat de les funcions de sumari que hem vist anteriorment. Per exemple, ens fixem que molt pocs països puntuen una xifra propera a 100 en l’índex de llibertat de premsa. També veiem que l’interval de dades més repetit és el que va de 50 a 60 en l’índex, que inclou aproximadament uns 40 casos.
- Fes una taula que mostri quina quantitat de països estan tenint una bona tendència (trend) de l’objectiu 2 (
Goal 2 Trend). - Visualitza amb un histograma quina és la distribució del percentatge de població que fa servir internet.
Si tens problemes per trobar variables concretes en escriure sdg$, recorda que pots buscar tota la llista de variables de forma senzilla si prems el tabulador després d’escriure el símbol del dòlar.
17.5 Creuament de dades
També podem creuar dades per veure com estan relacionades dues variables numèriques entre elles. En aquest cas, la visualització més habitual és el diagrama de dispersió, que es pot executar molt ràpidament amb plot(). Per utilitzar-la, dins de la funció posarem els dos vectors numèrics que volem examinar, separats per una coma. A continuació, observem com es relaciona la llibertat de premsa amb les percepcions de corrupció. Sobre aquesta segona variable, cal concretar que els països amb més percepció de corrupció tindran un valor que s’acostarà a 0, mentre que els països on la percepció de la corrupció és menor tindran un valor proper a 100.
plot(sdg$`Press Freedom Index (worst 0-100 best)`,
sdg$`Corruption Perceptions Index (worst 0-100 best)`)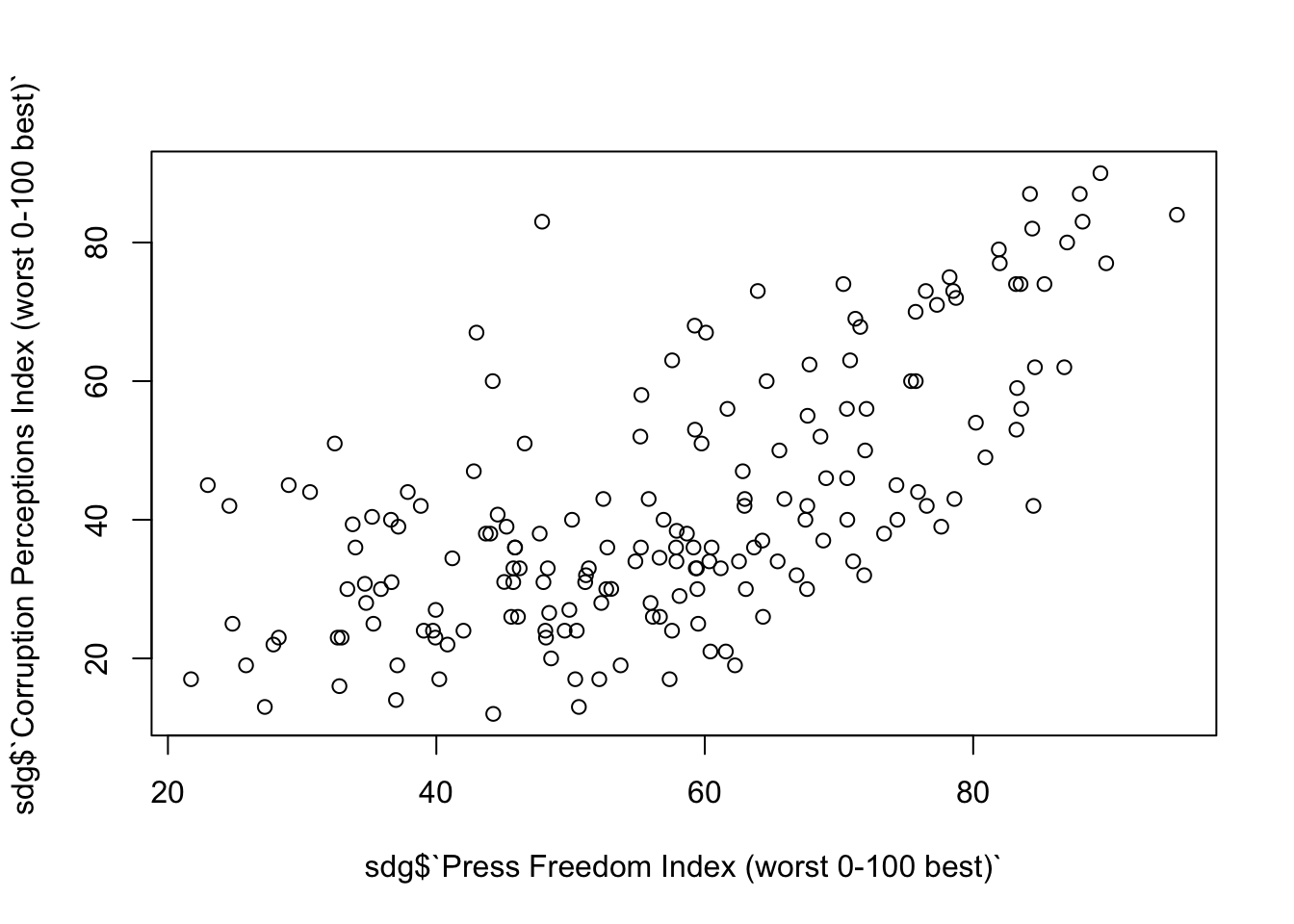
Si ens fixem en el gràfic, veiem que hi ha una relació positiva entre la llibertat de premsa i la percepció de la corrupció. És a dir, els països que tenen més llibertat de premsa també tenen una millor percepció de la corrupció (per tant, menor), mentre que els països amb menor llibertat de premsa tenen una pitjor percepció de la corrupció (per tant, major).