16 Banc Mundial
16.1 Introducció
El Banc Mundial (World Bank en anglès) és una institució internacional financera que es va fundar el 1944 a la conferència de Bretton Woods, juntament amb altres organitzacions, com el Fons Monetari Internacional (FMI). Des de la seva fundació, aquesta institució s’ha encarregat de donar préstecs a governs d’arreu del món, especialment a països de pocs recursos, per impulsar el seu desenvolupament econòmic. Però el que és especialment interessant per a nosaltres és la seva iniciativa de dades obertes.
El Banc Mundial conté més de 1.400 indicadors de més de 200 economies mundials, amb sèries temporals que van en alguns casos des de finals de la Segona Guerra Mundial fins a l’actualitat. Les dades abasten multitud de temes, des d’agricultura fins a deute extern, passant per indicadors macroeconòmics o indicadors d’igualtat de gènere, entre moltíssims altres. Aquestes dades es poden visualitzar a la seva pàgina web a través d’una consola interactiva i senzilla d’utilitzar, on es poden seleccionar les dades per països i període de temps i que fins i tot ofereix diversos tipus de gràfics possibles.
Aquesta eina permet aconseguir la visualització de dades senzilles. Si us voleu fer una idea de com funciona, podeu tafanejar amb la llista d’indicadors aquí. Però el que és realment interessant és com el Banc Mundial proporciona en obert totes les dades, perquè qui vulgui en pugui fer un ús més avançat mitjançant un programari estadístic. En aquest apartat descobrirem com fer un tractament de les dades amb el paquet d’R wbstats.
16.2 El paquet wbstats
El paquet wbstats (Piburn, 2020) permet accedir a la gran majoria de dades obertes del Banc Mundial a R amb unes poques línies de codi i importar-les fàcilment a R. Això evita el fet d’haver de descarregar i després carregar manualment a R cadascuna de les bases de dades, amb la consegüent despreocupació dels problemes de codificació que poden sorgir. Per poder-lo utilitzar, necessitarem tenir el paquet activat, juntament amb altres paquets d’R com dplyr, readr i ggplot2 (Wickham, François, et al., 2023; Wickham, Hester, et al., 2023; Wickham et al., 2024).
Recorda que per utilitzar un paquet, aquest ha d’estar prèviament instal·lat a RStudio. Si no has instal·lat algun d’aquests paquets, ara és el moment de fer-ho:
install.packages(c("dplyr", "readr",
"ggplot2", "wbstats"))El paquet wbstats funciona d’una forma prou senzilla, ja que permet:
- Buscar qualsevol indicador present en les bases de dades del Banc Mundial a través de la funció
wb_search(). - Descarregar l’indicador en qüestió a través de la funció
wb_data().
Vegem aquestes dues funcions pas a pas.
16.3 Buscar dades
La funció wb_search() funciona com un cercador de caràcters. Només cal indicar entre parèntesis quines paraules clau ha de cercar perquè faci una llista de tots els indicadors que estan relacionats amb aquella paraula. A continuació es mostra un codi que busca les dades que té el Banc Mundial sobre producte interior brut (PIB) per càpita. Dins de la funció haurem d’introduir:
- Un valor de caràcter, especificat entre cometes, per exemple
"gdp". - Si volem especificar vàries paraules, ho haurem de fer utilitzant el separador
.*, per exemple,"gdp.*capita".
La cerca retorna un marc de dades amb tres columnes:
-
indicator_id: l’identificador únic de la variable. -
indicator: el títol formal de la variable. -
indicator_desc: una breu descripció de l’indicador en qüestió.
# A tibble: 32 × 3
indicator_id indicator indicator_desc
<chr> <chr> <chr>
1 5.51.01.10.gdp Per capita GDP growth "GDP per capi…
2 6.0.GDPpc_constant GDP per capita, PPP (constant 2011 inter… "GDP per capi…
3 GB.XPD.RSDV.GD.ZS Research and development expenditure (% … "Gross domest…
4 GFDD.DM.01 Stock market capitalization to GDP (%) "Value of lis…
5 GFDD.DM.02 Stock market total value traded to GDP (… "Total value …
6 NE.GDI.FPUB.ZS Gross public investment (% of GDP) "Gross public…
7 NE.GDI.FTOT.CR GDP expenditure on gross fixed capital f… "Gross fixed …
8 NE.GDI.FTOT.SNA08.CR GDP expenditure on gross fixed capital f… <NA>
9 NV.AGR.PCAP.KD.ZG Real agricultural GDP per capita growth … "The growth r…
10 NY.GDP.PCAP.CD GDP per capita (current US$) "GDP per capi…
# ℹ 22 more rowsEn aquest tipus de marcs de dades, ens pot resultar molt convenient utilitzar la funció View(), que ens permet observar les dades en una finestra nova. Per utilitzar aquesta funció, guardarem primer les dades en un objecte i després n’examinarem el resultat.
Com podem observar, la cerca retorna més de 30 indicadors. Quan els examinem de prop, veurem que no tots aquests indicadors resulten útils. Per exemple, si estem interessats només en el PIB per càpita dels països, ens n’adonarem que molts són indicadors que utilitzen el PIB (gdp) com a referència, però no ens informen directament de dades de PIB. És el cas de SH.XPD.CHEX.GD.ZS, que mostra la despesa sanitària del país respecte al seu PIB. Per això és indispensable llegir els títols i les descripcions per saber exactament què ens explica l’indicador.
Ara que saps com cercar indicadors amb wb_search(), busca quins indicadors té el Banc Mundial sobre agricultura. Recorda que has de buscar-ho en anglès.
Recorda que, a dins de la funció wb_search(), hi has d’introduir un vector de caràcter. Per tant, has d’escriure la paraula o paraules "entre.*cometes".
16.4 Importar dades
Una vegada hem après com buscar els indicadors amb el paquet, el següent pas serà importar les dades de l’indicador que ens interessi amb la funció wb_data(). La informació clau que necessitem és la que es troba a la columna indicator_id del marc de dades que hem estat examinant a l’apartat anterior. Per importar les dades, utilitzarem el bloc de codi que queda a sota d’aquestes línies de la manera següent:
- A dins de la funció
wb_data(), indiquem amb l’argumentindicator = c("NY.GDP.PCAP.CD")que volem descarregar les dades referents als indicadors de PIB per càpita a preus constants i valorats en US$. Guardarem les dades a l’objectegdp.
- A l’argument
countrypodem especificar si volem les dades només per països (l’opció per defecte éscountry = "countries only") o bé si volem dades per regions o per grups de renda. Si consulteu l’ajuda?wb_data(), trobareu més informació sobre les diferents possibilitats que té aquest argument. - També es poden especificar altres característiques del marc de dades, com per exemple si volem la taula llarga o ampla (
return_wide), l’any d’inici de les dades (start_date), l’any final (end_date) o l’idioma dels resultats (lang)1. Per exemple:
1 Consulta els idiomes disponibles amb wb_languages().
Si en els passos següents sorgeix algun problema amb les dades, prova de descarregar-les de nou utilitzant el codi següent:
gdp <- wb_data(indicator = c("NY.GDP.PCAP.CD"),
country = "countries_only") |>
mutate(date = as.numeric(date)) |> as_tibble()El codi incorpora algunes funcions més:
- La funció
mutate(date = as.numeric(date))recodifica la columna “date” perquè R la llegeixi com una variable numèrica. - La funció
as_tibble()indica a R que ens ha de retornar aquesta base de dades en format tibble, que és més còmode per treballar.
16.5 Explorar dades
Per poder fer servir les dades correctament, abans és necessari saber exactament com estan organitzades, les dimensions de la nostra base de dades o les característiques de cadascuna de les variables. D’aquest procés se’n diu exploració de dades. Les dades que explorarem són les que importem amb el següent codi2.:
2 si darrerament el Banc Mundial ha actualitzat les seves dades, és possible que les teves dades no coincideixin al 100% amb les de l’exemple d’aquest mòdul.
Per comprovar que les dades s’han importat correctament, podem escriure el nom de l’objecte (gdp) a la consola d’Rstudio, que ens retornarà una mostra de les 10 primeres observacions de la nostra base de dades.
- L’objecte
gdpés una tibble formada per 7.161 observacions i 9 columnes. - Les dades estan ordenades alfabèticament per països, a les 10 primeres observacions només veiem les dades d’Aruba, del 1990 fins al 1999.
gdp
## # A tibble: 7,161 × 9
## iso2c iso3c country date NY.GDP.PCAP.CD unit obs_status footnote
## <chr> <chr> <chr> <dbl> <dbl> <lgl> <lgl> <lgl>
## 1 AW ABW Aruba 1990 11639. NA NA NA
## 2 AW ABW Aruba 1991 12850. NA NA NA
## 3 AW ABW Aruba 1992 13658. NA NA NA
## 4 AW ABW Aruba 1993 14970. NA NA NA
## 5 AW ABW Aruba 1994 16675. NA NA NA
## 6 AW ABW Aruba 1995 17140. NA NA NA
## 7 AW ABW Aruba 1996 17375. NA NA NA
## 8 AW ABW Aruba 1997 18713. NA NA NA
## 9 AW ABW Aruba 1998 19742. NA NA NA
## 10 AW ABW Aruba 1999 19834. NA NA NA
## # ℹ 7,151 more rows
## # ℹ 1 more variable: last_updated <date>Per explorar més a fons l’objecte gdp, podem utilitzar uns senzills comandaments d’R per respondre algunes qüestions fonamentals sobre les dades:
- De quins països diferents tenim dades? Com sabem, la funció unique retorna un vector de caràcter amb tots els valors que hi apareixen com a mínim una vegada.
unique(gdp$country)- De quants països diferents tenim dades? Si la pregunta que ens volem respondre no és quins, sinó quants països, podem incloure al mateix codi d’abans la funció length(). Aquesta funció s’encarrega de comptar la llargada que té un vector. Per tant, en aquest cas comptarà quants noms (països) surten com a mínim una vegada a la variable country.
- Quin és el rang longitudinal de dades? Podem comprovar que, efectivament, les dades comencen l’any 1990 i acaben el 2020. La funció range()determina el valor mínim i el valor màxim d’un vector. A més, introduirem l’argument na.rm = TRUE, que indica que la funció ignori els valors perduts i funcioni només amb aquells que coneix.
range(gdp$date, na.rm = TRUE)Recorda que perquè range funcioni, R ha de ser capaç d’entendre que una variable és numèrica. Si R no la detecta com a nombre, és tan senzill com convertir-la a variable numèrica amb la funció as.numeric(). Per exemple:
gdp$date <- as.numeric(gdp$date)Això transformarà la variable date en numèrica.
Ara que saps com explorar les dades, utilitza una de les funcions que acabem de veure i intenta respondre les preguntes següents:
- Quin és el valor més alt de PIB per càpita?
- Quin és el valor més baix de PIB per càpita?
16.6 Visualitzar dades
En aquest apartat aprendrem a visualitzar les dades de l’objecte gdp de dues maneres diferents: en un any determinat i a través del temps. Crearem les visualitzacions amb les funcions del paquet ggplot2 (Wickham et al., 2024).
16.6.1 En un any determinat
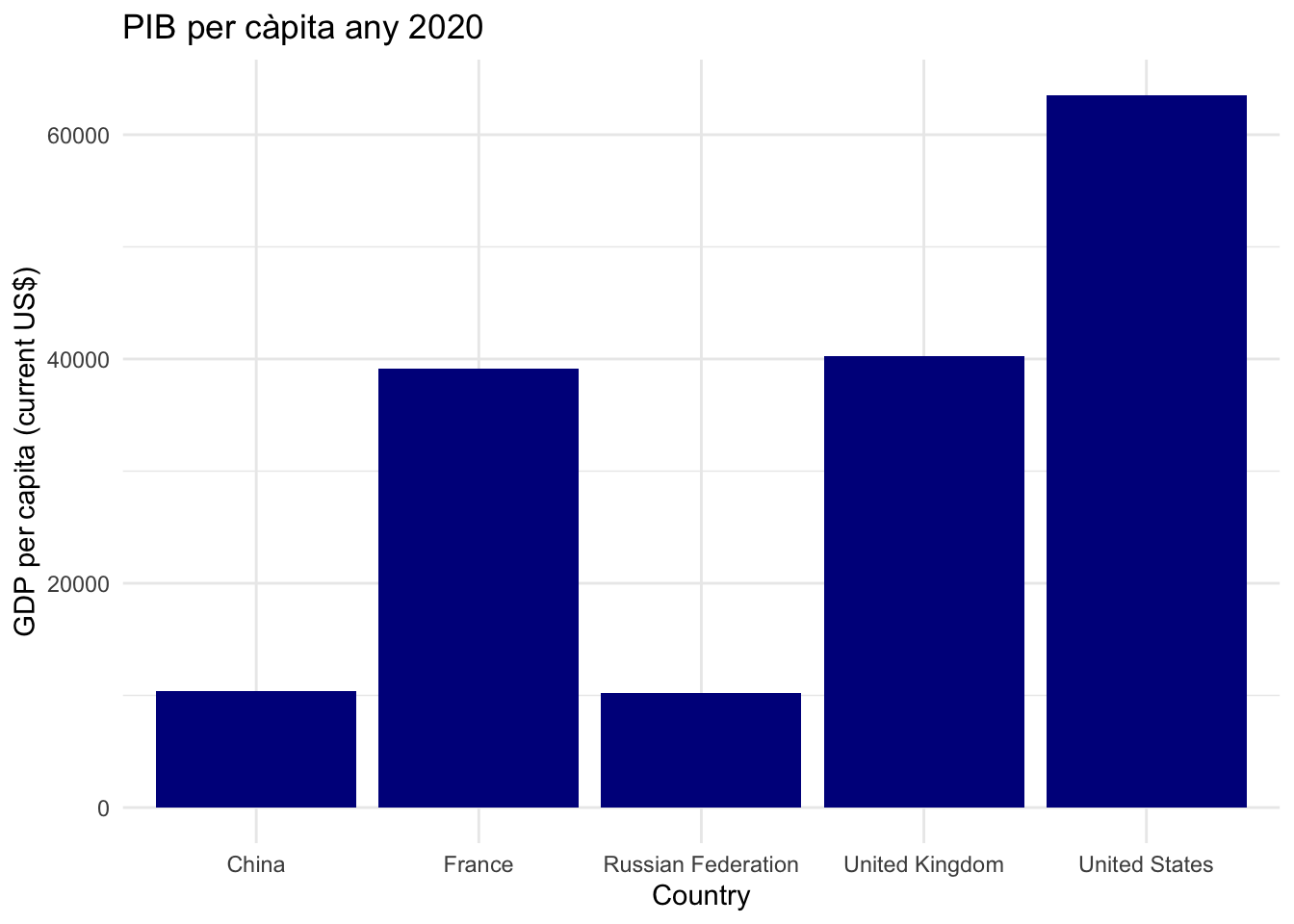
En aquest primer gràfic observarem unes dades concretes de diferents països en un any determinat. En el cas que ens ocupa, hem decidit observar el PIB per càpita de cinc països (Estats Units, la Xina, Rússia, el Regne Unit i França) el 2020. Per fer-ho correctament seguirem aquests passos:
En primer lloc, reduirem les dades per tal que mostrin només les observacions que ens interessen.
- Dins de la funció
filter(), indicarem l’any (date) que ens interessa examinar i els països (country) en qüestió, dins d’un vector de caràcter. - Fixem-nos que això ens produeix un marc de dades de cinc observacions.
gdp |>
filter(date == 2020,
country %in% c("United States", "China", "Russian Federation",
"United Kingdom", "France"))
## # A tibble: 5 × 9
## iso2c iso3c country date NY.GDP.PCAP.CD unit obs_status footnote
## <chr> <chr> <chr> <dbl> <dbl> <lgl> <lgl> <lgl>
## 1 CN CHN China 2020 10409. NA NA NA
## 2 FR FRA France 2020 39180. NA NA NA
## 3 GB GBR United Kingdom 2020 40217. NA NA NA
## 4 RU RUS Russian Federation 2020 10194. NA NA NA
## 5 US USA United States 2020 63529. NA NA NA
## # ℹ 1 more variable: last_updated <date>El proper pas serà ubicar els vectors en qüestió en un gràfic, pel qual haurem de tenir carregat el paquet ggplot2.
- A dins de les funcions
ggplot(aes()), especificarem que a l’eix de les \(x\) (horitzontal) hi posarem els països i a l’eix de les \(y\) (vertical) les dades de PIB per càpita. - Fixem-nos com ggplot2 ens ubica aquestes dues variables en el gràfic.
Finalment, indicarem la geometria i el títol del gràfic i dels eixos:
- La geometria serà un diagrama de barres (
geom_col()). Amb l’argumentfillpersonalitzarem el color de les barres del gràfic ("darkblue"). - Especificarem els títols del gràfic, indicant a dins de la funció
labs()un valor de caràcter per cada argument:x,yititle.
Ara que has vist com de senzill és fer un gràfic comparant dades d’un any de diversos països, intenta comparar les dades de PIB per càpita de tres països diferents, però de l’any 2015:
- Afegeix el valor de l’any en qüestió.
- Canvia els
?per països que vulguis examinar. Com saps, pots demanar la llista de països amb la funcióunique(). - Canvia el color de les barres, consultant aquesta web.
- Canvia els títols del gràfic.
gdp |>
filter(date == ?,
country %in% c("?", "?", "?")) |>
ggplot(aes(x = country, y = NY.GDP.PCAP.CD)) +
geom_col(fill = "darkblue") +
labs(title = "Títol del gràfic", x = "Títol d'x", y = "Títol d'x")- Recorda que els països han d’estar escrits en anglès i anar “entre cometes”. En canvi, els números no cal que vagin entre cometes.
- A més, l’última línia de codi del gràfic no ha de tenir el símbol
+al final, perquè sinó ggplot2 no entendrà que el gràfic ja està acabat.
16.6.2 A través del temps
El fet que el Banc Mundial proveeixi dades de varis anys ens permet veure l’evolució d’alguns indicadors al llarg del temps. Per exemple, ens pot interessar veure com evolucionen les dades del PIB per càpita dels Estats Units i la Xina. Per aconseguir-ho, farem les següents operacions a l’objecte gdp:
- Amb
filter(), filtrem les dades del vectorcountryper als països que ens interessen, de manera que conservarem només les observacions que formen part dels Estats Units o de la Xina. - Indiquem amb les funcions
ggplot(aes())les variables del gràfic: a l’eix horitzonal hi posarem l’any (x = date); a l’eix vertical, l’indicador de PIB per càpita (y = NY.GDP.PCAP.CD) i també especificarem que el color serveixi per diferenciar les dades dels països (col = country) - Per veure l’evolució d’una variable en el temps, la geometria més apropiada és el diagrama de línies
geom_line(). - Finalment, a l’última capa definirem els títols del gràfic amb la funció
labs().
gdp |>
filter(country %in% c("United States", "China")) |>
ggplot(aes(x = date, y = NY.GDP.PCAP.CD, colour = country)) +
geom_line() +
labs(title = "Evolució PIB per càpita (1990-2022)",
x = "Year", y = "GDP per capita (current US$)", col = "País")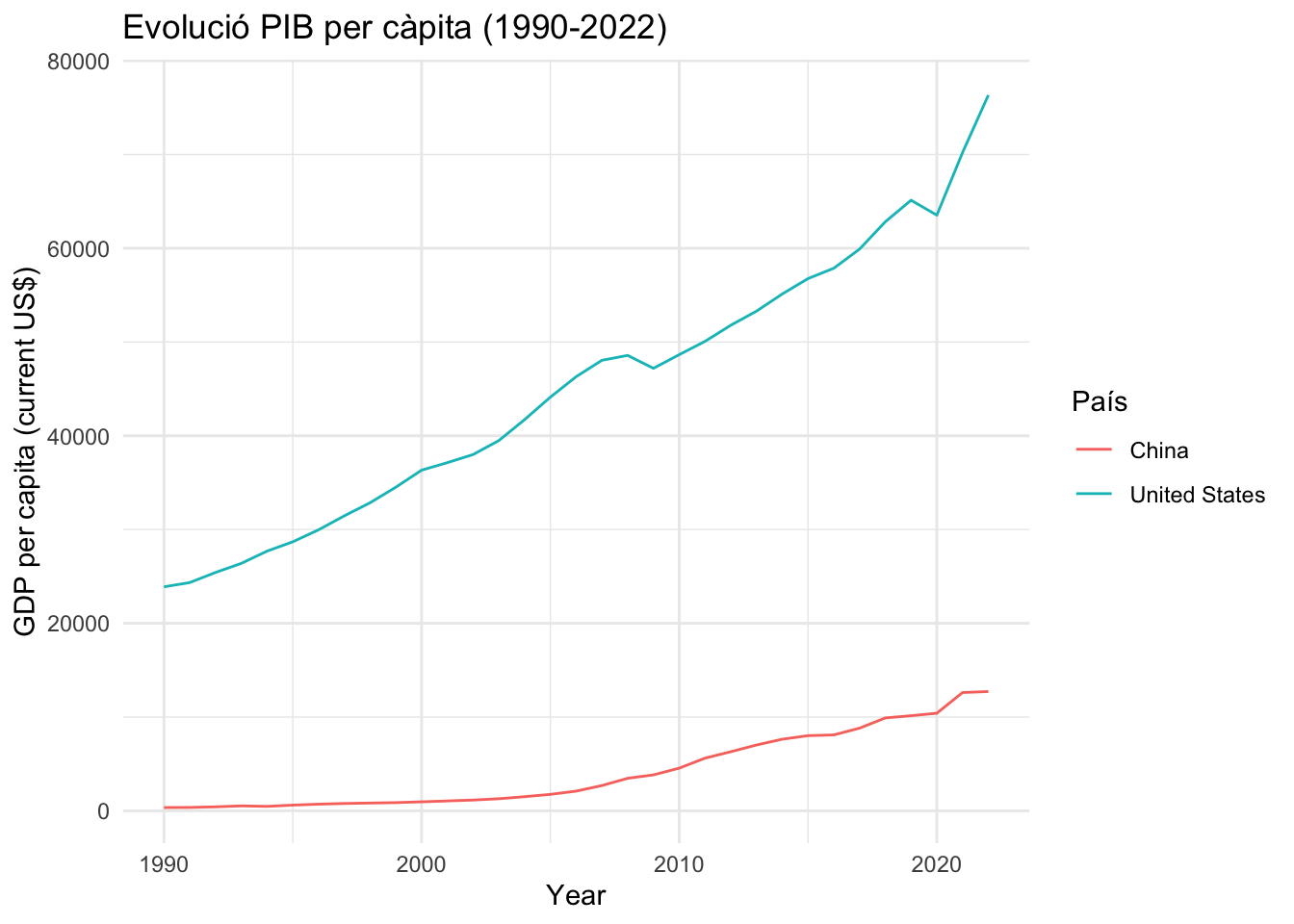
Una vegada vist com es pot fer un gràfic senzill amb ggplot, i fixant-te en el codi que es mostra, prova de fer un gràfic comparatiu amb dos països europeus diferents. Fes les següents modificacions al codi:
- Filtra les dades per uns altres valors del vector
country. - Canvia el títol del gràfic.
- Opcionalment, afegeix l’argument
linetype = countrya dins de la capa deggplot(aes())i observa’n els resultats.