19 Qualitat de govern
19.1 Introducció
El Quality of Government Institute (QoG a partir d’ara) és una institució de recerca associada a la Universitat de Göteborg (Suècia). Va ser fundada el 2004 i és famosa per haver realitzat múltiples estudis i elaborat diverses bases de dades al voltant de la qualitat de govern. Els conjunts de dades que emmagatzemen acostumen a agrupar indicadors de diverses organitzacions internacionals, de manera que són un recurs molt útil com a calaix de sastre si necessitem dades que tenen com a unitat d’observació el país-any. El conjunt de dades més ampli és l’Standard Dataset, que conté més de 2.100 (!) variables. També podem trobar bases de dades especialitzades en la sostenibilitat i el medi ambient (Environmental Indicators Dataset) i dades de nivell subnacional (EU Regional Dataset).
En aquesta activitat, tractarem amb una versió reduïda de l’Standard Dataset, la Basic Dataset (Dahlberg et al., 2020), que conté 400 variables, una quantitat suficient i prou interessant per treballar amb dades relacionades amb la governança.
19.2 Descàrrega per web o paquet
Per descarregar les dades de QoG, anirem a la seva pàgina web, on hi ha penjades totes les bases de dades en format obert. Quan entrem en aquesta pàgina web, veurem com a la part dreta de la pantalla s’ofereixen diverses possibilitats de descàrrega.
-
Cross-Section: és un conjunt de dades organitzat a nivell de país en l’últim any registrat de dades, atorgant cada observació (192 en total) a un país diferent. No la utilitzarem, però hi ha moltes formes de descàrrega:
- DTA (Stata)
- CSV (fitxer separat per comes)
- XLSX (Excel “normal”)
- SAV (pensat per a SPSS, acostuma a venir etiquetat)
Time-Series: és un conjunt de dades que té com a unitat d’observació el país-any i té un abast temporal molt ampli, que comença al final de la Segona Guerra Mundial i arriba fins a l’actualitat. En ser una base de dades molt més gran (quasi 16.000 observacions), només podem descarregar-la en tres formats diferents.
En aquesta activitat descarregarem les dades Time Series en format CSV des del marge dret de la pantalla, tal com es mostra a la part inferior de la Figura 19.1. Quan descarreguem el fitxer, el guardarem amb el nom de qog_timeseries.csv i el situarem al directori de treball. Seguidament, l’importarem a RStudio amb la funció read_csv() del paquet readr, que haurem de carregar juntament amb tots els altres paquets que farem servir en aquesta activitat (Wickham, François, et al., 2023; Wickham, Hester, et al., 2023; Wickham et al., 2024).
Una alternativa per importar la base de dades és amb el paquet d’R rqog (R-rqog?). Si voleu provar aquest mètode, opcionalment podeu seguir aquest procediment:
- Instal·lar i carregar el paquet
devtools, que ens permet obrir paquets pujats a Github. - Instal·lar i carregar el paquet
rqogamb la funcióinstall_github. - Carregar el dataset QoG basic utilitzant la funció
read_qog()i afegint-hi l’argumentwhich_data = "basic". També hi afegim la funciótibble()per convertir les dades en format tibble.
install.packages("devtools")
library(devtools)
install_github("ropengov/rqog")
library(rqog)
qog_basic <- tibble(read_qog(which_data = "basic"))És possible que aquesta segona forma doni problemes o errors en alguns ordinadors, perquè implica modificacions una mica complexes en instal·lar paquets de fora l’ambient d’Rstudio. Per tant, si no et funciona, simplement descarrega l’arxiu CSV des de la web, tal com hem fet anteriorment.
19.3 Llibre de codis
El llibre de codis és imprescindible per comprendre el contingut del conjunt de dades. El de QoG es troba a la mateixa web d’on ens hem descarregat les dades, també al marge dret, en la secció Codebook, tal com es mostra a la Figura 19.2.
Aquí ens descarregarem el llibre de codis en format PDF. Hi trobarem un fitxer d’unes 400 pàgines, on s’especifica en detall el contingut del conjunt de dades, quines variables hi trobem, què expliquen exactament, d’on han sortit i la disponibilitat, tant temporal (quins anys hi inclouen) com geogràfica (de quins països tenen dades).
Podem perdre’ns una mica i tafanejar cadascuna d’aquestes pàgines, però abans intentarem entendre com està organitzat aquest llibre de codis. Per això, mirarem de buscar si hi ha dades de la percepció de la corrupció. Això ens permetrà familiaritzar-nos amb el procés de cerca de variables en el document, que consisteix en dos passos:
- A l’apartat 2 del llibre de codis, consultarem la llista de variables. Una de les categories d’aquesta llista és Quality of Government, on veiem que ens indica la pàgina on buscar el Corruption Perceptions Index. En aquest cas és a la pàgina 82, però cal tenir en compte que els llibres de codis s’actualitzen regularment i que, per tant, pot ser que si consultes una versió més nova trobis aquest indicador en una pàgina diferent.
Veuràs com aquest llibre de codis parla d’algunes variables que no es troben en el Basic Dataset. La raó per la qual no hi són és probablement perquè aquestes variables es troben a l’Standard Dataset. També pot ser degut al fet que la base de dades s’actualitza regularment i, a vegades, poden haver-hi discrepàncies amb el llibre de codis, tenint en compte que és una base de dades tan grossa.
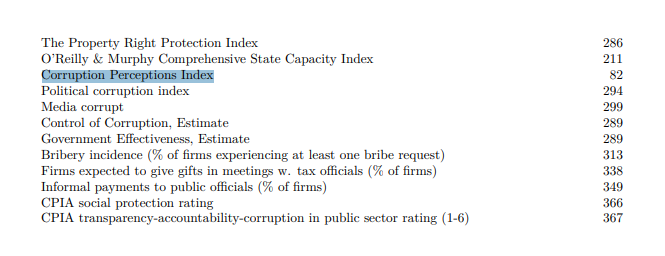
- Un cop localitzat el Corruption Perceptions Index dins del llibre de codis, anirem a la pàgina en qüestió i llegirem atentament la informació tècnica de la variable.

Fixem-nos que aquesta variable:
- Té per nom:
ti_cpi, per la qual cosa l’haurem de buscar al marc de dades com aqog_basic$ti_cpi - El valor 0 equival al valor més alt de corrupció percebuda i el valor 100 equival al nivell més baix de corrupció percebuda.
- És una variable contínua (és a dir, numèrica de ràtio) amb escala de 0 a 100.
- Té una alta disponibilitat temporal (2012-2022) i geogràfica (179 països), amb el seu corresponent mapa de disponibilitat i un gràfic on explica l’evolució dels països inclosos en aquesta variable.
Ara que saps com llegir un llibre de codis, busca si en aquesta base de dades hi ha alguna variable que parli de:
- Quin és el nombre efectiu de partits als parlaments nacionals? Hi ha diverses fórmules per calcular-ho?
- Quin percentatge de seients tenen els partits agraris als parlaments?
Recorda que has de buscar els noms en anglès!
19.4 Explorar dades
Una vegada sabem desxifrar què ens intenten explicar els indicadors, podem començar a explorar aquest conjunt de dades.
19.4.1 Exploració general
Primer de tot examinarem l’objecte qog_basic, que havíem emmagatzemat prèviament. En la versió descarregada per fer aquest tutorial, observem que el marc de dades té 15.564 observacions i 252 variables.
qog_basic
## # A tibble: 15,564 × 252
## ccode cname year ccode_qog cname_qog ccodealp ccodecow version cname_year
## <dbl> <chr> <dbl> <dbl> <chr> <chr> <dbl> <chr> <chr>
## 1 4 Afghani… 1946 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 2 4 Afghani… 1947 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 3 4 Afghani… 1948 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 4 4 Afghani… 1949 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 5 4 Afghani… 1950 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 6 4 Afghani… 1951 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 7 4 Afghani… 1952 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 8 4 Afghani… 1953 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 9 4 Afghani… 1954 4 Afghanis… AFG 700 QoGBas… Afghanist…
## 10 4 Afghani… 1955 4 Afghanis… AFG 700 QoGBas… Afghanist…
## # ℹ 15,554 more rows
## # ℹ 243 more variables: ccodealp_year <chr>, ajr_settmort <dbl>,
## # atop_ally <dbl>, atop_number <dbl>, bci_bci <dbl>, bicc_gmi <dbl>,
## # biu_offrel <dbl>, bmr_dem <dbl>, bmr_demdur <dbl>, cai_cai2 <dbl>,
## # cbi_cbiu <dbl>, cbi_cbiw <dbl>, cbie_index <dbl>, ccp_cc <dbl>,
## # ccp_childwrk <dbl>, ccp_equal <dbl>, ccp_freerel <dbl>, ccp_slave <dbl>,
## # ccp_strike <dbl>, chga_demo <dbl>, ciri_assn <dbl>, ciri_dommov <dbl>, …A la part inferior del marc de dades apareixen totes les variables que, atès l’extens nombre de columnes, no apareixen en pantalla. Hi ha dues funcions que permeten examinar més a fons totes les variables:
- Amb
glimpse(qog_basic)es despleguen totes les variables en format vertical i es visualitzen les primeres observacions de cada una d’elles. - Amb
names(qog_basic)s’obté un vector de caràcter amb els noms de totes les variables.
Utilitzant aquestes dues funcions podrem comprovar si les variables que apareixen al llibre de codis ho fan també en el marc de dades. Hem de pensar que és possible que algunes variables no apareguin a la Basic Dataset que estem treballant, però sí que hi siguin a l’Standard Dataset.
19.4.2 Exploració específica
Una vegada tenim una idea general sobre el marc de dades i les seves variables, podem fer una exploració més específica de variables concretes amb algunes funcions d’R. A continuació ens farem unes preguntes sobre algunes de les variables que apareixen en el marc de dades:
-
Quin és el rang d’anys de les dades? Per saber-ho, usarem la funció
range()i li indicarem el vector del marc de dades que ens interessa. En aquest cas només cal escriureqog_basici indicar que volem explorar la columna d’any a través d’escriure un símbol de$i el nom de la columna corresponentyear. L’operació ens retornarà el valor numèric més baix i més alt del vector.
range(qog_basic$year)
## [1] 1946 2023-
De quins anys tenim dades? Per saber-ne el resultat, haurem de preguntar quines categories úniques té la variable
yearamb la funcióunique().
unique(qog_basic$year)
## [1] 1946 1947 1948 1949 1950 1951 1952 1953 1954 1955 1956 1957 1958 1959 1960
## [16] 1961 1962 1963 1964 1965 1966 1967 1968 1969 1970 1971 1972 1973 1974 1975
## [31] 1976 1977 1978 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990
## [46] 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005
## [61] 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020
## [76] 2021 2022 2023-
De quants anys tenim dades? Per saber-ne el resultat haurem de demanar la longitud del vector anterior. Per tant, combinarem
length()iunique().
- Quin és l’interval de dades d’una determinada variable? Utilitzant una de les variables que has buscat anteriorment amb l’exercici 1, podem veure, per exemple, quin és el percentatge més alt i més baix de seients que tenen els partits agraris a través d’aquest codi.
Si t’hi fixes, la funció range() inclou un segon argument, na.rm = T, que demana a R que obviï si hi ha valors perduts. Què passaria si no la poséssim?
Doncs que simplement ens donaria com a resultat NA NA, perquè tindria en compte els valors perduts a l’hora de calcular el mínim i el màxim de les dades.
range(qog_basic$cpds_la, na.rm = T)
## [1] 0.0 40.6-
De quants països diferents tenim dades? De nou, tornem a combinar les funcions
length()iunique(), ara en el vectorqog_basic$cname, i sabrem els noms únics de països que apareixen en el marc de dades.
-
Quin és el tipus de règim autocràtic més freqüent?: La funció
count()retorna un recompte de freqüències d’una variable. Dins de la funció haurem d’indicar tres arguments, separats per comes:- El marc de dades:
qog_basic. - El vector que interessa recomptar:
gwf_regimetype. - Si s’ordena el recompte deixant els grups més nombrosos a la part superior del resultat:
sort = TRUE.
- El marc de dades:
count(qog_basic,
gwf_regimetype,
sort = TRUE)
## # A tibble: 11 × 2
## gwf_regimetype n
## <dbl> <int>
## 1 NA 11041
## 2 4 1435
## 3 2 1152
## 4 1 595
## 5 5 386
## 6 3 291
## 7 7 251
## 8 8 177
## 9 6 133
## 10 9 66
## 11 10 37
Per interpretar el resultat, haurem de seguir el llibre de codis, on s’explica el significat de cada valor numèric (Figura 19.3). Si el consultem a fons, veurem que la variable categoritza de l’1 al 10 diferents tipus de règims autocràtics i deixa com a valor perdut (NA) els règims democràtics. Per exemple, podem suposar que 11.041 observacions són règims democràtics, i que el tipus de règim autocràtic més repetit amb 1.152 observacions és l’autocràcia de partit, que correspon al número 4. Hem de pensar que la unitat d’observació del marc de dades és país-any, per la qual cosa la xifra de 1.435 indica la quantitat d’observacions país-any que, entre el 1946 i el 2023, qualifiquen com a règim d’autocràcia de partit.
19.5 Visualització
No totes les autocràcies són igual d’autocràtiques. Algunes poden tenir alguns trets més democràtics que d’altres, com, per exemple, organitzar eleccions, permetre la concurrència de vàries formacions polítiques a les eleccions o reprimir de manera moderada la seva població. Podrem veure de manera general aquestes diferències si comparem una variable categòrica com la del tipus de règim (gwf_regimetype) amb una variable numèrica com la variable de democràcia liberal de V-Dem (vdem_libdem) (Coppedge et al., 2020).
La variable vdem_libdem indica que un país és autocràtic quan s’aproxima al valor 0 i que un país s’aproxima a l’ideal d’una democràcia liberal a mesura que s’acosta al valor 1. A continuació veurem fins a quin punt alguns països autocràtics tenen certs atributs propers a la democràcia liberal. Posarem com a any de referència el 2010, per reduir les dades i emmagatzemar-les a l’objecte qog_basic10.
qog_basic10 <- qog_basic |>
filter(year == 2010)19.5.1 Visualitzar una variable
En primer lloc, examinarem més a fons la nova variable d’interès. Com que és una variable numèrica, visualitzarem la distribució de les dades amb un histograma, que serveix per recomptar el nombre d’observacions que cauen en un interval concret de les dades. Introduirem el nom de la variable a dins de la funció hist().
hist(qog_basic10$vdem_libdem)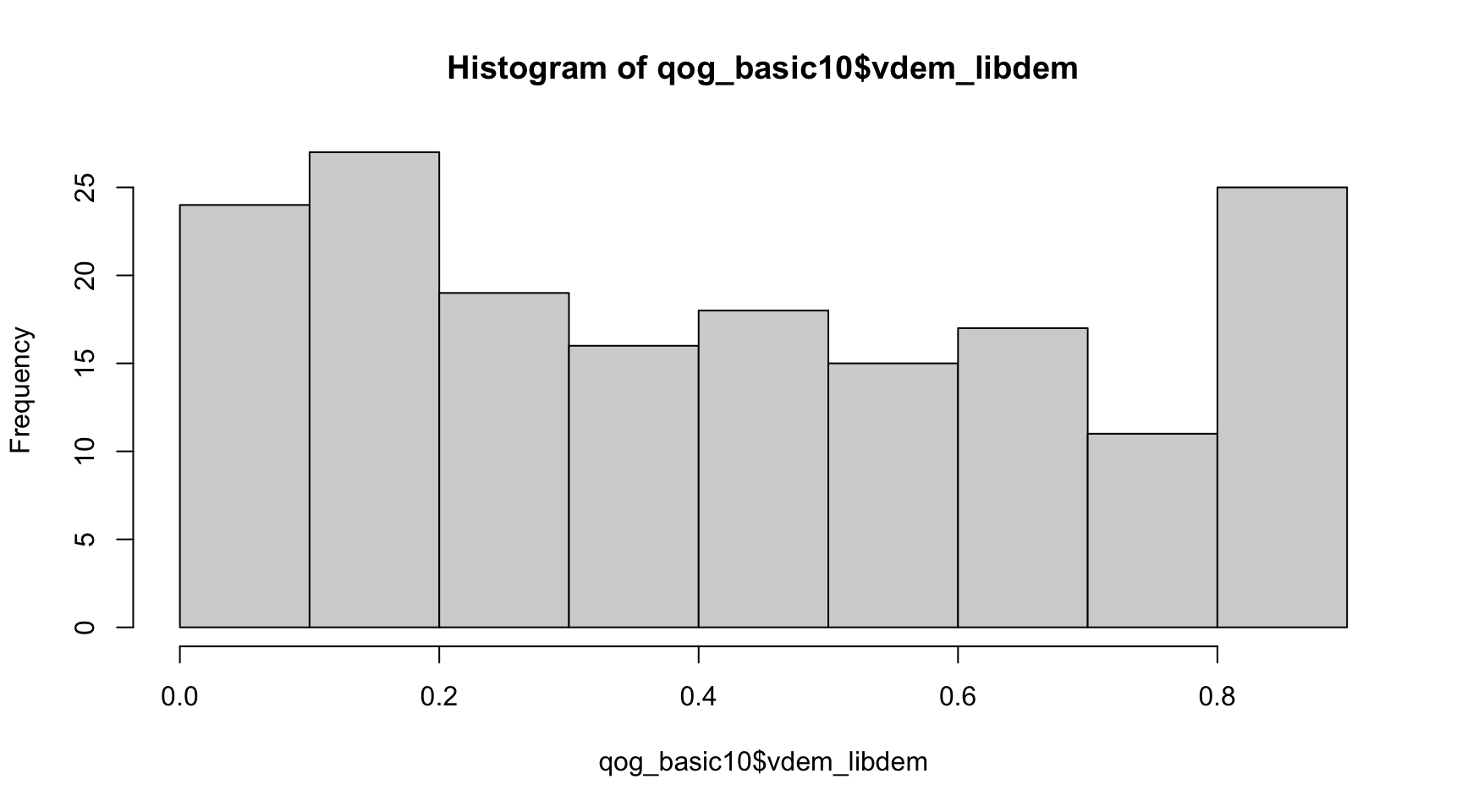
Fixem-nos que en el 2010 hi havia molta variabilitat entre règims polítics. Uns 25 règims eren molt autocràtics, molt propers al valor 0. També uns 25 règims polítics s’acostaven al valor 0,2, senyal que eren força autocràtics. Trobem una quantitat semblant de règims polítics (entre 15 i 25) en aproximadament tots els intervals de dades de l’histograma. A l’extrem superior, observem que uns 25 països tenien un valor de democràcia liberal superior a 0,8.
19.5.2 Creuament de variables
Quins nivells de qualitat democràtica tenien l’any 2010 les autocràcies personals i les partidistes? Per respondre a aquesta pregunta, utilitzarem principalment dues variables de l’objecte qog_basic10, ja filtrades per l’any 2010:
- Els nivells de democràcia liberal:
vdem_libdem. - Tipus de règim:
gwf_regimetype.
Al codi següent, hi hem realitzat les següents operacions:
- Filtrar les dades pel tipus de règim (
gwf_regimetype) 2 (autocràcies personals) i 4 (autocràcies partidistes). - Visualitzar a l’eix horitzontal de les \(x\) les dades de tipus de règim (
gwf_regimetype), transformades com a vector de caràcter, i a l’eix vertical de les \(y\) els nivells de democràcia (vdem_libdem). - Visualitzar el valor de cada observació amb un text (
geom_text()), que descrigui les inicials del país (variableccodealp). Per poder veure més clarament el text, sacsejarem la seva posició de manera aleatòria. - Demanar la mitjana per cada categoria amb
stat_summary(), en vermell.
qog_basic10 |>
filter(gwf_regimetype %in% c(2, 4)) |>
ggplot(aes(x = as.character(gwf_regimetype),
y = vdem_libdem)) +
geom_text(aes(label = ccodealp),
position = position_jitter(width = 0.2)) +
stat_summary(col = "red")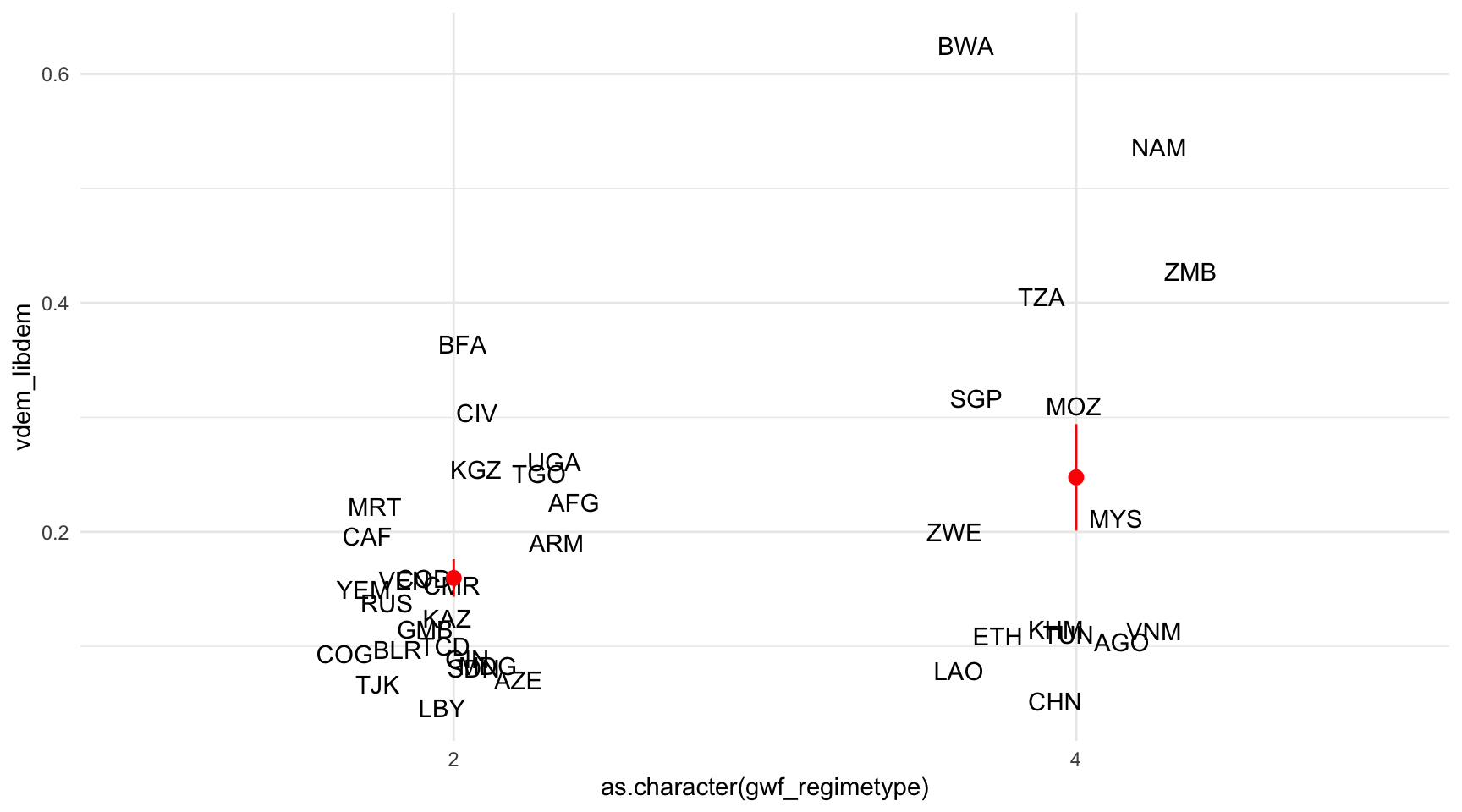
Fixa’t com hem inclòs la funció as.character() abans de la variable year i gwf_regimetype. Aquesta funció ens permet indicar a R que entengui que aquestes variables les estem tractant com a categòriques, i no com a simples variables contínues. És a dir, R entendrà que el valor 1 a la variable gwf_regimetype no és un número sol, sinó que indica una categoria diferenciada, i el tractarà de forma diferent.
Segons observem a les dades del 2010, les autocràcies partidistes són, de mitjana, més democràtiques que no pas les autocràcies personals. En el primer cas, la mitjana se situa al voltant del 0,25, mentre que, en el segon cas, la mitjana se situa al voltant del valor de 0,15. Crida l’atenció la presència d’algunes autocràcies partidistes que puntuen amb un valor relativament alt en l’índex de democràcia liberal, com són Botswana i Namíbia. En canvi, les autocràcies personals no superen el valor de 0,4, sent Burkina Faso el valor més alt.
Observa bé el gràfic anterior i compara els nivells de democràcia de les oligarquies i les monarquies l’any 2000.
19.5.3 Graficar una evolució temporal
Com evoluciona la democràcia liberal al món? En aquest apartat aprendrem a veure l’evolució temporal d’una variable en països concrets com els Estats Units i el Regne Unit. Per això, de la base de dades de QoG que tenim emmagatzemada a l’objecte qog_basic, necessitem informació diversa:
- Els nivells de democràcia liberal:
vdem_libdem. - Any:
year.
Al codi hi farem les operacions següents:
- Filtrar les dades del vector
cname_qogper als països que ens interessen: els Estats Units i el Regne Unit. - Visualitzar a l’eix horitzontal de les \(x\) els anys (
year) i a l’eix vertical de les \(y\) els nivells de democràcia (vdem_libdem). - Distingir les dades de cada país (
cname_qog) amb un color diferent. - Visualitzar les dades amb la geometria del diagrama de línies (
geom_line()).
qog_basic |>
filter(cname_qog %in% c("United States", "United Kingdom")) |>
ggplot(aes(x = year, y = vdem_libdem, col = cname_qog)) +
geom_line()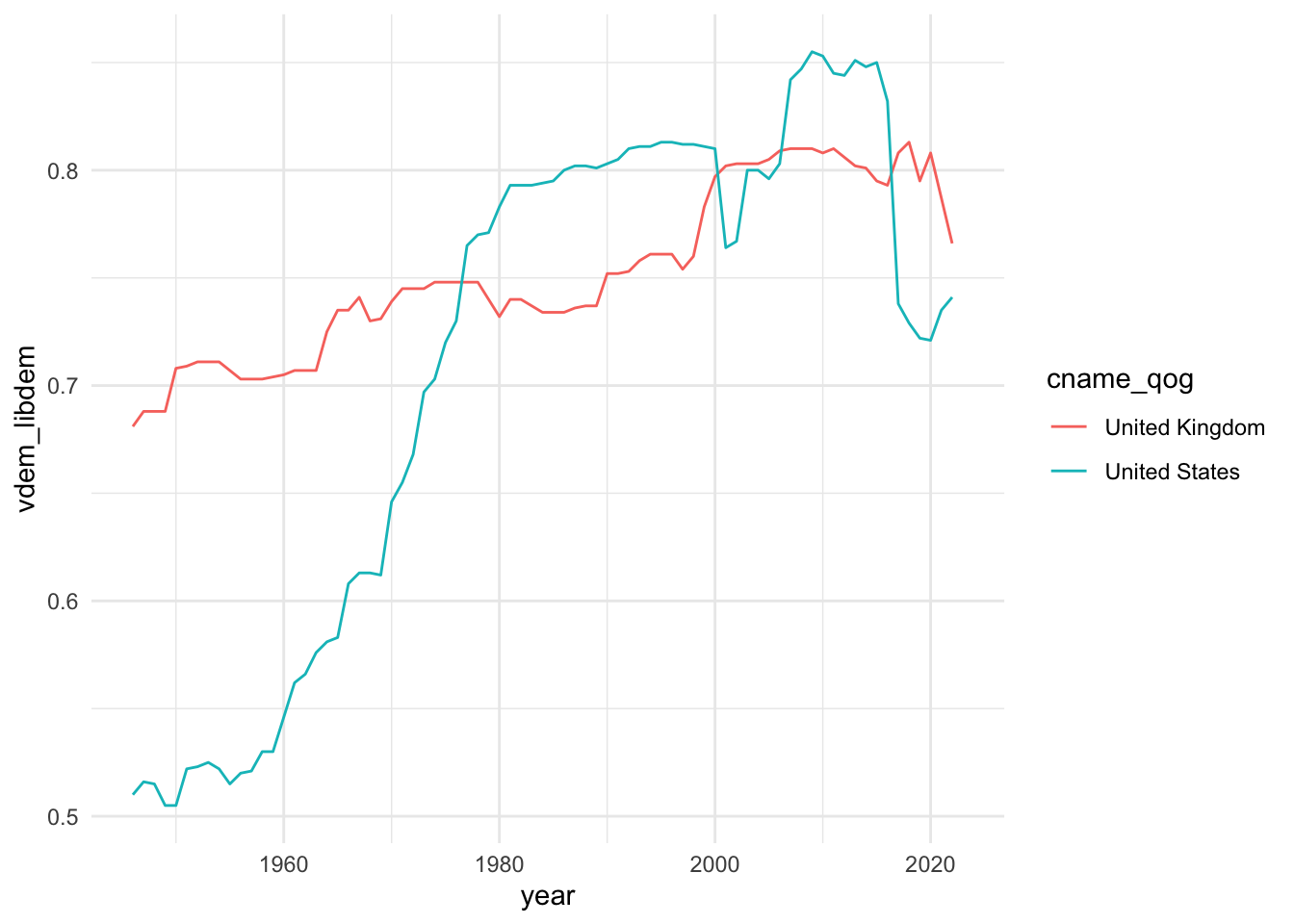
Ara que saps com graficar evolucions temporals amb variables contínues, i sense marxar dels índexs que crea VDem, busca al llibre de codis com es diu la variable que avalua com de políticament empoderades estan les dones, i fes-ne un gràfic amb els mateixos països. Canvia els ?que pertoquin al codi següent per aconseguir-ho. Si vols provar alguna cosa una mica més complicada, intenta afegir també els resultats provinents d’Espanya.
qog_basic |>
filter(cname_qog %in% c("United States", "United Kingdom")) |>
ggplot(aes(x = year, y = ?, col = cname_qog)) +
geom_line()