12 Recodificaciones
12.1 Introducción
A menudo nos encontraremos con que queremos observar o representar los datos de una forma diferente a como nos vienen codificadas. Por ejemplo, tal como veíamos en la tabla 10.8, es posible que no nos interese saber la edad exacta de cada líder político, sino simplemente saber si tienen «65 años o más», o bien «Menos de 65 años». Del mismo modo, nos puede interesar observar los datos de año por décadas («1990», «2000»…) o ver si los países son «Ricos» o «Pobres», en lugar de saber el valor exacto de su PIB per cápita. A estas operaciones las denominamos recodificar los valores de una variable.
Recodificar una variable significa modificar sus valores de forma parcial o total, a veces hasta el punto de llegar a cambiar el tipo de vector o de variable. Estas transformaciones suelen ir en sentido inverso al orden que hemos usado para estudiar hasta ahora las variables. Es decir, recodificaremos una variable de ratio para convertirla en una variable nominal u ordinal, pero difícilmente podremos recodificar una variable nominal u ordinal en una de ratio. Esto se debe a que las variables categóricas tienen información menos precisa que las numéricas, de forma que con esta información nos resulta imposible transformar estos valores en una cifra numérica concreta. Por ejemplo, si un país es «Rico», no sabemos qué valor numérico exacto adoptará. En cambio, si sabemos que tiene 63.000 dólares per cápita, fácilmente lo podamos recodificar como «Rico».
Un resumen del tipo de recodificaciones que podemos realizar lo encontramos en la tabla 12.1. En la primera columna vemos la variable de destino a la que lo queremos recodificar y en la segunda columna la función que utilizaremos para hacer la recodificación.
| Destino | Función |
|---|---|
| Binaria | if_else() |
| Categórica |
case_when(), case_match()
|
| Ordinal | factor() |
| Otros |
as.numeric(), as.character(), as.Date(), etc. |
A la hora de recodificar variables, los vectores lógicos tienen una relevancia capital. Anteriormente ya habíamos comentado que los vectores lógicos eran muy importantes, pero en el último apartado hemos podido comprobar que no están explícitamente asociados a ninguna variable. Así pues, ¿de qué nos sirve un vector lógico? Los vectores lógicos son principalmente herramientas operacionales. Esto significa que nos servirán para establecer las condiciones que nos permitan transformar los valores de una variable a otra. Dicho de otro modo, los vectores lógicos se sitúan en medio de una transformación. Y para explotar las potencialidades de los vectores lógicos necesitaremos conocer los operadores booleanos.
Los operadores booleanos o lógicos nos permiten hacer combinaciones de valores de forma lógica. Para comprender su funcionamiento, se recomienda ver primero el vídeo de la derecha. En segundo lugar, aplicaremos los tres operadores booleanos (AND, OR y NOT) al marco de datos ctr_pov, que vemos entero en la tabla 12.2 del margen lateral.
- El operador AND (
&) devuelve TRUE solo si se cumplen todas las condiciones. - El operador OR (
|) devuelve TRUE si se cumple una de las condiciones. - El operador NOT (
!) devuelve lo contrario de la condición.
| country | continent | poverty |
|---|---|---|
| Armenia | ASI | 1.9 |
| Austria | EUR | 0.7 |
| Benin | AFR | 49.6 |
| Bolivia | AME | 6.4 |
| Brazil | AME | 3.4 |
| Colombia | AME | 4.5 |
| El Salvador | AME | 1.9 |
| Ethiopia | AFR | 26.7 |
| Honduras | AME | 16.2 |
| Indonesia | ASI | 7.2 |
Combinando los operadores AND, OR y NOT podemos conseguir que R nos devuelva como TRUE y como FALSE una combinación de diversas variables. En la figura 12.1 del lateral vemos algunas de las posibles combinaciones, tomando como variable x la redonda de la izquierda y como variable y la de la derecha. A continuación, ponemos algunos ejemplos de combinaciones. Fijaos en que estas operaciones booleanas nos devuelven un vector lógico indicando qué valores cumplen (TRUE) las condiciones que hemos establecido y qué valores no las cumplen (FALSE). Como veremos, podemos aprovechar los TRUE para crear nuevas variables. Es importante comentar que se pueden encadenar combinaciones de tantas variables como se desee.
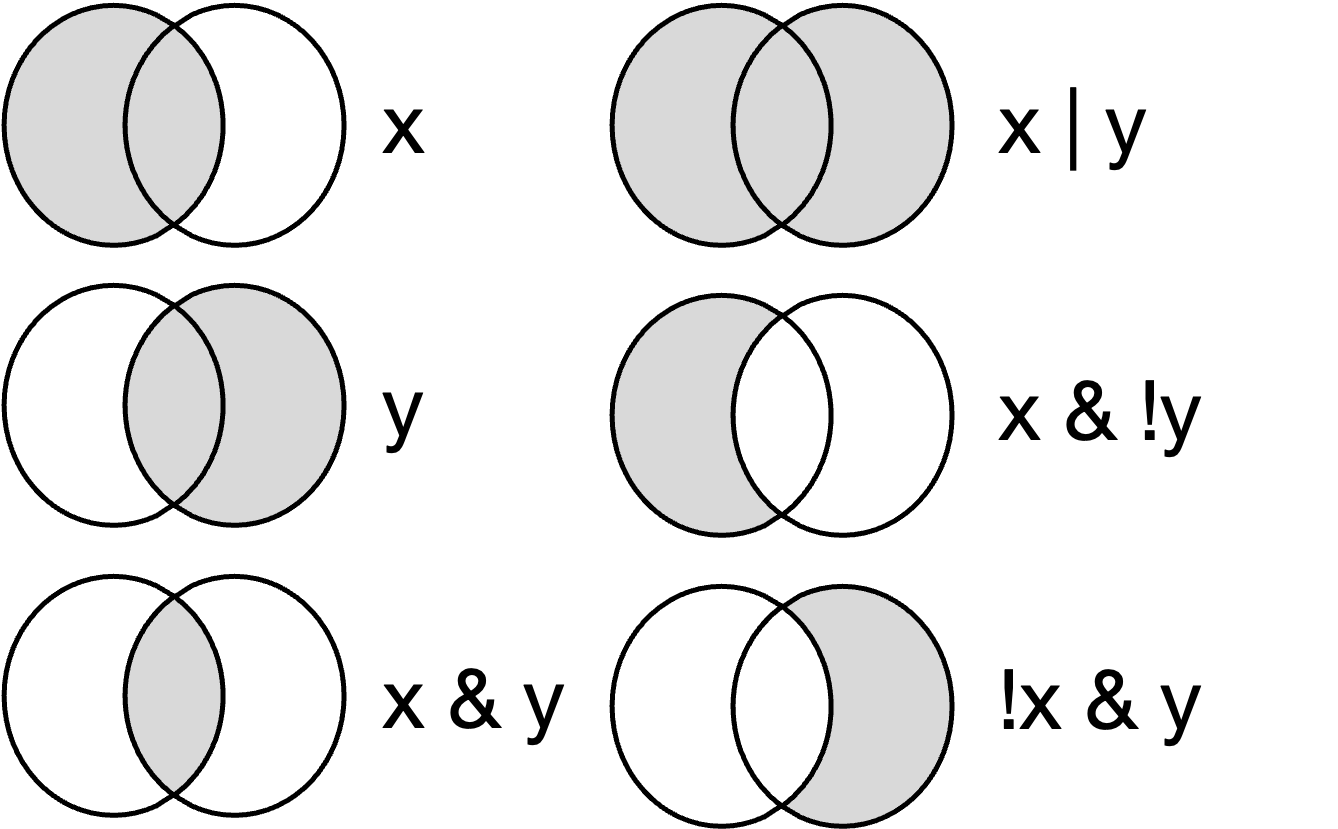
A continuación, pedimos cuáles son las observaciones que son del continente africano y (AND) que tienen el umbral de pobreza por encima de los diez dólares.
ctr_pov$continent == "AFR" & ctr_pov$poverty > 10
## [1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSEComo vemos, la operación nos dice que el tercero (Benin) y el octavo país (Ethiopia) cumplen los requisitos.
Podríamos quedarnos con las observaciones que cumplen los requisitos si utilizamos los corchetes:
ctr_pov[ctr_pov$continent == "AFR" & ctr_pov$poverty > 10, ]
## # A tibble: 2 × 3
## country continent poverty
## <chr> <chr> <dbl>
## 1 Benin AFR 49.6
## 2 Ethiopia AFR 26.7Observamos, en cambio, qué pasa cuando preguntamos cuáles son las observaciones que son del continente africano u (OR) que tienen el umbral de pobreza por encima de los diez dólares.
ctr_pov$continent == "AFR" | ctr_pov$poverty > 10
## [1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE TRUE FALSEEn este caso, también la novena observación (Honduras) cumple los requisitos porque, si bien no está en África, sí que tiene un umbral de pobreza por encima de los diez dólares.
Podríamos quedarnos con las observaciones que cumplen los requisitos si utilizamos los corchetes:
ctr_pov[ctr_pov$continent == "AFR" | ctr_pov$poverty > 10, ]
## # A tibble: 3 × 3
## country continent poverty
## <chr> <chr> <dbl>
## 1 Benin AFR 49.6
## 2 Ethiopia AFR 26.7
## 3 Honduras AME 16.2A continuación, pedimos cuáles son las observaciones que no (NOT) son del continente africano y (AND) que tienen el umbral de pobreza por encima de los diez dólares. Tendremos que poner un signo de exclamación (!) delante del vector que niega.
!ctr_pov$continent == "AFR" & ctr_pov$poverty > 10
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSEComo vemos, solo un país, Honduras, cumple los requisitos. También habréis observado que podríamos hacer la misma operación poniendo la negación (!=) en lugar del doble igual.
Podríamos quedarnos con las observaciones que cumplen los requisitos si utilizamos los corchetes:
ctr_pov[!ctr_pov$continent == "AFR" & ctr_pov$poverty > 10, ]
## # A tibble: 1 × 3
## country continent poverty
## <chr> <chr> <dbl>
## 1 Honduras AME 16.212.2 Recodificar a variable binaria
Cualquier variable se puede recodificar en binaria. Una variable numérica que incluya, por ejemplo, la altura de diferentes personas, se podría recodificar en «Alto» y «Bajo» si establecemos un umbral determinado que separe las dos categorías. También se podría hacer lo mismo con una variable nominal que describiera el color del cabello de varios individuos. Podríamos crear una nueva variable binaria que tuviera solo dos categorías: «Rojo» y «Otros».
Para dicotomizar cualquier variable, la función más adecuada es if_else() del paquete dplyr. En esta función, situaremos como primer argumento el resultado de una operación lógica, como segundo argumento el valor que tomará la nueva variable si el resultado de la operación es cierto, y como tercer argumento el valor que tomará la nueva variable si el resultado de la operación es falso.
if_else(operación lógica, TRUE, FALSE)Pondremos tres ejemplos para ver la función if_else() en acción:
El marco de datos strings contiene la variable continent, que es categórica. Para dicotomizarla crearemos una condición lógica que identifique las observaciones que son del continente americano. Cuando es cierto, lo llamaremos «Americas» y, cuando es falso, lo llamaremos «Others».
strings$continent <- if_else(strings$continent == "Americas", "Americas", "Others")
strings# A tibble: 8 × 5
iso3c country currency continent region
<chr> <chr> <chr> <chr> <chr>
1 CMR Cameroon CFA Franc BEAC Others Sub-Saharan Africa
2 COL Colombia Colombian Peso Americas Latin America & Ca…
3 CUB Cuba Cuban Peso Americas Latin America & Ca…
4 FRA France Euro Others Europe & Central A…
5 LSO Lesotho Loti Others Sub-Saharan Africa
6 QAT Qatar Qatari Rial Others Middle East & Nort…
7 TWN Taiwan New Taiwan Dollar Others East Asia & Pacific
8 TTO Trinidad & Tobago Trinidad & Tobago Dollar Americas Latin America & Ca…El resultado de la binarización también puede ser numérico. A continuación, recodificamos la escala ordinal del índice de democracia de The Economist en 1 si es democracia y en 0 si no lo es. En el primer argumento de if_else() hemos utilizado la función str_detect() del paquete stringr para que marque como TRUE todos aquellos valores del vector ords$regime_type que contengan "Democracy" (esto incluye tanto Full Democracy como Flawed Democracy). Con esto creamos la nueva variable dem.
ords$dem <- if_else(str_detect(ords$regime_type, "Democracy"), 1, 0)
ords
## # A tibble: 10 × 4
## donor ati regime_type dem
## <chr> <ord> <ord> <dbl>
## 1 US-MCC Very Good Flawed Democracy 1
## 2 Canada-GAC Good Full Democracy 1
## 3 Germany-BMZ-GIZ Good Full Democracy 1
## 4 Korea-KOICA Good Full Democracy 1
## 5 Australia-DFAT Good Full Democracy 1
## 6 Spain-AECID Fair Flawed Democracy 1
## 7 Saudi Arabia-KSRelief Poor Authoritarian 0
## 8 Norway-MFA Poor Full Democracy 1
## 9 China-MOFCOM Very Poor Authoritarian 0
## 10 Turkey-TIKA Very Poor Hybrid Regime 0Con los operadores booleanos podemos crear una clasificación que nos marque los países con más potencial militar del marco de datos ratio a partir de establecer una serie de condiciones lógicas en varias variables. Indicaremos que un país es "Powerful" si tiene un gasto militar superior al millón de dólares, un personal militar superior a 500.000 y una población superior a los setenta millones de habitantes. Para introducir correctamente las magnitudes, debe consultarse el libro de códigos de NMC.
ratio$power <- if_else(ratio$milex > 1000000 & ratio$milper > 500 &
ratio$tpop > 70000,
"Powerful", "Powerless")
ratio
## # A tibble: 7 × 6
## country milex milper tpop cinc power
## <chr> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 USA 980000 334 131028 0.182 Powerless
## 2 UKG 7895671 394 47762 0.0997 Powerless
## 3 FRN 1023651 581 41900 0.0396 Powerless
## 4 GMY 12000000 2750 79798 0.178 Powerful
## 5 ITA 669412 581 44020 0.027 Powerless
## 6 RUS 5984123 1789 170317 0.138 Powerful
## 7 JPN 1699970 957 71380 0.0591 Powerful12.3 Recodificar a variable categórica
Existen principalmente dos motivos por los que querremos recodificar una variable a categórica. Volviendo al ejemplo de la altura, podríamos convertir diferentes valores numéricos en tres categorías: «Alto», «Mediano», «Bajo». O podríamos recodificar una variable categórica de forma que tenga menos categorías. Por ejemplo, si tenemos cinco religiones («Cristiana», «Protestante», «Islámica», «Budista» e «Hindú»), podemos querer recodificar las categorías de forma que las dos primeras pasen a llamarse «Católica».
Para cada caso, utilizaremos dos funciones diferentes: case_when() y case_match().
12.3.1 De vector numérico a categórico
La función adecuada para recodificar una variable numérica a categórica es case_when(). La función consta de tantos argumentos como categorías queramos crear y todos los argumentos tienen la misma estructura, excepto el último. A cada argumento situaremos primero la condición lógica, seguido del símbolo ~ y del nombre que tomarán todos los valores que cumplan esta condición. En el último argumento indicaremos .default = en lugar de una condición lógica y el nombre de la categoría que recogerán el resto de las observaciones que queden por clasificar.
case_when(condición lógica ~ "C1"
condición lógica ~ "C2",
condición lógica ~ "C3",
...,
.default = "CN")Es importante tener en cuenta que, en cada argumento, case_when() va retirando los valores que ha marcado como TRUE en los argumentos anteriores. Es decir, si en el primer argumento una observación ha sido marcada como TRUE y, por lo tanto, codificada de una determinada manera, esta observación ya no se tendrá en cuenta en argumentos posteriores aunque cumpla la condición lógica.
Para ver en funcionamiento case_when(), utilizaremos la MID dataset (Palmer et al., 2020), que almacena disputas militarizadas entre estados desde 1816 hasta la actualidad. Muchas de sus variables vienen codificadas numéricamente, por lo que tendremos que consultar el libro de códigos para poderlas convertir a su valor categórico correspondiente.
En la versión reducida de la MID dataset observamos una selección de disputas militarizadas entre díadas de países. Por ejemplo, en la primera observación vemos la disputa entre Francia y Rusia que tuvo lugar en 1849.
mid_recod# A tibble: 330 × 9
disno namea nameb year outcome settlmnt fatlev hihost duration
<dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 4586 MAL INS 2008 5 3 0 3 1
2 180 RUS KOR 1905 2 1 0 4 32
3 4004 DRV CAM 1996 1 2 0 4 7
4 51 CHN PHI 1952 0 0 0 5 366
5 3448 SYR ISR 1981 5 1 1 4 207
6 1202 NIC HON 1907 1 1 6 5 313
7 4319 AZE ARM 1997 5 3 0 4 135
8 208 UKG RUS 1953 5 3 1 4 20
9 1129 SAU UKG 1934 8 4 0 4 54
10 1580 MOR SPN 1859 0 0 0 5 77
# ℹ 320 more rowsUna recodificación muy habitual es recodificar una variable temporal en décadas o en periodos históricos. Con el código siguiente, hemos creado la variable period, que contiene cinco categorías.
mid_recod$period <- case_when(mid_recod$year < 1914 ~ "Pax Britannica",
mid_recod$year < 1946 ~ "The Thirty Years' Crisis",
mid_recod$year < 1989 ~ "Cold War",
mid_recod$year < 2003 ~ "Post-Cold War",
.default = "Present")
mid_recod# A tibble: 330 × 10
disno namea nameb year outcome settlmnt fatlev hihost duration period
<dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
1 4586 MAL INS 2008 5 3 0 3 1 Present
2 180 RUS KOR 1905 2 1 0 4 32 Pax Britanni…
3 4004 DRV CAM 1996 1 2 0 4 7 Post-Cold War
4 51 CHN PHI 1952 0 0 0 5 366 Cold War
5 3448 SYR ISR 1981 5 1 1 4 207 Cold War
6 1202 NIC HON 1907 1 1 6 5 313 Pax Britanni…
7 4319 AZE ARM 1997 5 3 0 4 135 Post-Cold War
8 208 UKG RUS 1953 5 3 1 4 20 Cold War
9 1129 SAU UKG 1934 8 4 0 4 54 The Thirty Y…
10 1580 MOR SPN 1859 0 0 0 5 77 Pax Britanni…
# ℹ 320 more rowsAlgunas variables nos llegan codificadas numéricamente, pero en realidad son categóricas. Si consultamos el libro de códigos de la base de datos (Dyadic MID 4.02), veremos que los valores numéricos de settlmnt tienen un equivalente categórico.
mid_recod$settlmnt <- case_when(mid_recod$settlmnt == 0 ~ "Missing",
mid_recod$settlmnt == 1 ~ "Negotiated",
mid_recod$settlmnt == 2 ~ "Imposed",
mid_recod$settlmnt == 3 ~ "None",
mid_recod$settlmnt == 4 ~ "Unclear",
.default = NA_character_)
mid_recod# A tibble: 330 × 10
disno namea nameb year outcome settlmnt fatlev hihost duration period
<dbl> <chr> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <chr>
1 4586 MAL INS 2008 5 None 0 3 1 Present
2 180 RUS KOR 1905 2 Negotiated 0 4 32 Pax Britan…
3 4004 DRV CAM 1996 1 Imposed 0 4 7 Post-Cold …
4 51 CHN PHI 1952 0 Missing 0 5 366 Cold War
5 3448 SYR ISR 1981 5 Negotiated 1 4 207 Cold War
6 1202 NIC HON 1907 1 Negotiated 6 5 313 Pax Britan…
7 4319 AZE ARM 1997 5 None 0 4 135 Post-Cold …
8 208 UKG RUS 1953 5 None 1 4 20 Cold War
9 1129 SAU UKG 1934 8 Unclear 0 4 54 The Thirty…
10 1580 MOR SPN 1859 0 Missing 0 5 77 Pax Britan…
# ℹ 320 more rows12.3.2 Recodificar valores categóricos
Para recodificar los valores de una variable categórica, la función más adecuada suele ser case_match(), donde podemos decidir qué valores recodificaremos y cuáles conservarán su nombre original. Su funcionamiento es el siguiente:
case_match(variable,
"Valor Antiguo1" ~ "Valor Nuevo1",
"Valor Antiguo2" ~ "Valor Nuevo2",
...,
.default = "Otros")A diferencia de case_when(), case_match() no permite utilizar más de una variable para hacer las recodificaciones ni realizar operaciones lógicas. Solo podemos indicar cuál será el nuevo valor que tomará una categoría concreta.
Veremos en funcionamiento case_match() con los datos de la WRD (Maoz & Henderson, 2013), que contiene varios conjuntos de datos sobre la adherencia religiosa en el mundo desde 1945. Cada conjunto de datos describe la población que practica cada religión en un nivel diferente: global, regional o estatal. A continuación veremos los datos a escala global.
En la versión reducida de la WRD dataset observamos un marco de datos con algunas de las principales religiones del mundo. Por ejemplo, en la primera observación vemos que la religión Cristianismo protestante (chrstprot) tenía 160.887.585 fieles en 1945.
relig_recod# A tibble: 32 × 3
year religion value
<dbl> <chr> <dbl>
1 1945 chrstprot 160887585
2 1945 chrstcat 391332035
3 1945 chrstang 36955033
4 1945 jdcons 1426350
5 1945 judref 1929388
6 1945 islmsun 49050320
7 1945 islmshi 19436742
8 1945 islmibd 0
9 1945 islmnat 0
10 1945 islmalw 0
# ℹ 22 more rowsPodemos recodificar las religiones para crear una nueva categoría que englobe las religiones mayores. Así, las tres religiones cristianas que aparecen en la base de datos las podríamos codificar como «Christianism». En primer lugar, miraremos cuántas categorías tenemos.
unique(relig_recod$religion) [1] "chrstprot" "chrstcat" "chrstang" "jdcons" "judref"
[6] "islmsun" "islmshi" "islmibd" "islmnat" "islmalw"
[11] "islmahm" "budmah" "nonrelig" "sumrelig" "pop"
[16] "worldpop" "chrstprotpct" "chrstcatpct" "chrstangpct" "judconspct"
[21] "judrefpct" "islmsunpct" "islmshipct" "islmibdpct" "islmnatpct"
[26] "islmalwpct" "islmahmpct" "budmahpct" "nonreligpct" "sumreligpct"
[31] "ptctotal" "version" La función case_match() es efectiva cuando queremos recodificar algunos valores. Por ejemplo, si queremos cambiar a Christianism las categorías chrstprot, chrstcat y chrstang, esta función nos lo permite hacer con poco código. Primero indicamos el vector que queremos transformar y seguido de cada una de las transformaciones. Si en el argumento .default indicamos el nombre propio de la variable, nos mantendrá los valores que no hayamos recodificado:
relig_recod$mr <- case_match(relig_recod$religion,
"chrstprot" ~ "Christianism",
"chrstcat" ~ "Christianism",
"chrstang" ~ "Christianism",
.default = relig_recod$religion)
relig_recod# A tibble: 32 × 4
year religion value mr
<dbl> <chr> <dbl> <chr>
1 1945 chrstprot 160887585 Christianism
2 1945 chrstcat 391332035 Christianism
3 1945 chrstang 36955033 Christianism
4 1945 jdcons 1426350 jdcons
5 1945 judref 1929388 judref
6 1945 islmsun 49050320 islmsun
7 1945 islmshi 19436742 islmshi
8 1945 islmibd 0 islmibd
9 1945 islmnat 0 islmnat
10 1945 islmalw 0 islmalw
# ℹ 22 more rowsEl problema de case_match() es que tenemos que recodificar los valores uno por uno. Para ello, a menudo, case_when() nos permite encontrar atajos cuando tenemos que recodificar muchos valores, como en el supuesto que indicamos a continuación. Aquí hemos combinado las condiciones lógicas con str_detect(). Puesto que judaísmo será difícil de especificar, hemos utilizado la expresión regular ^j, que indica que debe localizar la letra «j» a principio de palabra.
relig_recod$mr <- case_when(str_detect(relig_recod$religion, "chrst") ~ "Christianism",
str_detect(relig_recod$religion, "islm") ~ "Islamism",
str_detect(relig_recod$religion, "bud") ~ "Buddism",
str_detect(relig_recod$religion, "^j") ~ "Judaism",
.default = "Other/NA")
relig_recod# A tibble: 32 × 4
year religion value mr
<dbl> <chr> <dbl> <chr>
1 1945 chrstprot 160887585 Christianism
2 1945 chrstcat 391332035 Christianism
3 1945 chrstang 36955033 Christianism
4 1945 jdcons 1426350 Judaism
5 1945 judref 1929388 Judaism
6 1945 islmsun 49050320 Islamism
7 1945 islmshi 19436742 Islamism
8 1945 islmibd 0 Islamism
9 1945 islmnat 0 Islamism
10 1945 islmalw 0 Islamism
# ℹ 22 more rows12.4 A variable ordinal
Como se ha explicado anteriormente, las variables ordinales raramente nos vendrán directamente codificadas como factor ordinal. Lo más habitual será que estén codificadas como vector de carácter o como vector numérico y que las tengamos que recodificar. En este apartado veremos cómo recodificarlas con la función factor() con un ejemplo de cada caso.
factor(wb$income_group,
ordered = TRUE,
[levels o labels = ...])Como se puede observar, en el tercer argumento se ha marcado entre corchetes levels o labels. Esto significa que en función de la recodificación que busquemos usaremos levels, labels o ambos argumentos. El argumento levels está pensado para definir el orden de los niveles, de menor a mayor, mientras que el argumento labels está pensado para definir las etiquetas de cada nivel.
12.4.1 De vector de carácter a ordinal
Una de las variables ordinales más empleadas en el ámbito internacional es la clasificación del Banco Mundial según grupo de renta de los países. Esta clasificación está formada por cuatro categorías (ingreso bajo, medio-bajo, medio-alto, alto), que observamos en la variable income_group. Las categorías son de gran importancia para muchas economías en desarrollo, puesto que solo las de ingresos más bajos podrán acceder a determinados préstamos del banco. Otras organizaciones internacionales también usan estas categorías. El Sistema Generalizado de Preferencias de la Unión Europea se basa en la clasificación del Banco Mundial para determinar qué países podrán vender sus productos al mercado europeo sin tener que pagar aranceles.
En la versión reducida de la base de datos del Banco Mundial, observamos que los países están clasificados por región, grupo de renta y tipo de financiación (lending_category). Observamos como la variable income_group está codificada como vector de carácter.
wb_recod# A tibble: 30 × 5
economy code region income_group lending_category
<chr> <chr> <chr> <chr> <chr>
1 Bahamas, The BHS Latin America & Carib… High income ..
2 Lithuania LTU Europe & Central Asia High income ..
3 Samoa WSM East Asia & Pacific Upper middl… IDA
4 Thailand THA East Asia & Pacific Upper middl… IBRD
5 Pakistan PAK South Asia Lower middl… Blend
6 Nepal NPL South Asia Low income IDA
7 Iran, Islamic Rep. IRN Middle East & North A… Upper middl… IBRD
8 Australia AUS East Asia & Pacific High income ..
9 Bolivia BOL Latin America & Carib… Lower middl… IBRD
10 Albania ALB Europe & Central Asia Upper middl… IBRD
# ℹ 20 more rowsPara recodificar el vector como factor ordinal, primero tendremos que saber cuáles son las categorías de la variable. Observamos que, efectivamente, income_group es una variable con cuatro categorías.
unique(wb_recod$income_group)[1] "High income" "Upper middle income" "Lower middle income"
[4] "Low income" Con la función factor() pasamos la variable a factor. En el primer argumento indicamos el nombre del vector, en el segundo argumento ordered = TRUE indicamos que queremos ordenar sus categorías y en el argumento levels indicamos, de menor a mayor, el orden de las categorías.
Podemos comprobar que R ha codificado la variable correctamente de varias maneras:
- Con la función
class()nos aparecerá «ordered» «factor». - Imprimiendo el marco de datos nos aparecerá
<ord>encima de la columna en cuestión. - Con la función
unique()veremos el orden de los niveles. - Imprimiendo el vector también veremos el orden de los niveles.
wb_recod$income_group[1:2][1] High income High income
4 Levels: Low income < Lower middle income < ... < High income12.5 De vector numérico a ordinal
La mayoría de las variables ordinales de encuesta nos llegarán codificadas en vectores numéricos, como es el caso de la mayoría de las variables de la encuesta WVS. Puesto que las categorías ordinales están codificadas numéricamente, para recodificar la variable con sus valores categóricos tendremos que consultar necesariamente el libro de códigos de la base de datos.
En la versión reducida de la séptima oleada de la WVS, observamos que los entrevistados, de varios países, responden a varias preguntas que son codificadas numéricamente. Si nos fijamos en el libro de códigos de la base de datos, veremos que la variable Q4 pregunta por la importancia que tiene la política para la persona encuestada. Esta pregunta se mide con una escala ordinal de cuatro valores: ‘Muy importante’ corresponde al valor numérico 1, ‘Más bien importante’ al valor 2, ‘No muy importante’ al 3 y ‘Nada importante’ al 4.
wvs_recod# A tibble: 1,000 × 12
A_WAVE C_COW_ALPHA C_COW_NUM A_YEAR Q1 Q2 Q3 Q4 Q5 Q6 Q7
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 7 MAL 820 2018 1 2 1 1 4 2 1
2 7 GMY 255 2018 2 1 2 3 1 4 1
3 7 KZK 705 2018 2 2 2 4 2 4 1
4 7 RUS 365 2017 1 1 2 3 1 3 1
5 7 KZK 705 2018 1 2 2 4 1 1 2
6 7 SRB 345 2017 1 1 1 1 1 1 1
7 7 AUL 900 2018 1 1 1 1 1 4 1
8 7 MEX 70 2018 1 2 1 4 1 1 1
9 7 DRV 816 2020 1 2 2 2 1 1 1
10 7 GRC 350 2017 1 1 1 4 1 1 1
# ℹ 990 more rows
# ℹ 1 more variable: Q8 <dbl>Antes de realizar la conversión, tendremos que asegurarnos de que estas cuatro categorías estén presentes en la variable.
unique(wvs_recod$Q4)[1] 1 3 4 2 NAVemos que los cuatro valores están presentes, como también el valor NA. El valor NA responde a las siglas en inglés Not Available (no disponible).
Recodificar esta variable concreta es un poco contraintuitivo, puesto que el número 4 corresponde al valor más bajo de la escala ordinal (Nada importante), mientras que el valor 1 corresponde al valor más alto (Muy importante). Esto quiere decir que deberemos indicar en algún momento el orden correcto de los valores de la escala. Dado que inicialmente estamos tratando con un vector numérico, el procedimiento más sencillo será cambiar la escala con una simple resta en el primer argumento. En el segundo argumento indicaremos cuáles son las etiquetas correctas con labels y finalmente indicaremos que es un factor ordinal en el tercer argumento.
Una segunda opción, que da el mismo resultado que el anterior, es la siguiente. En el primer argumento indicamos el vector numérico en cuestión. En el segundo argumento levels indicamos el orden correcto de los niveles, de menor a mayor. Con labels indicamos en el tercer argumento el nombre de los hashtags que corresponderá a cada nivel y finalmente en el cuarto argumento indicaremos que es un factor ordinal.
factor(wvs_recod$Q4,
levels = c("4", "3", "2", "1"),
labels = c("Not at all important", "Not very important",
"Rather important", "Very important"),
ordered = T) [1] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[15] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[29] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[43] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[57] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[71] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[85] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[99] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[113] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[127] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[141] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[155] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[169] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[183] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[197] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[211] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[225] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[239] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[253] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[267] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[281] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[295] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[309] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[323] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[337] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[351] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[365] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[379] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[393] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[407] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[421] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[435] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[449] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[463] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[477] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[491] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[505] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[519] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[533] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[547] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[561] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[575] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[589] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[603] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[617] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[631] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[645] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[659] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[673] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[687] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[701] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[715] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[729] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[743] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[757] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[771] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[785] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[799] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[813] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[827] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[841] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[855] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[869] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[883] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[897] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[911] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[925] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[939] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[953] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[967] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[981] <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[995] <NA> <NA> <NA> <NA> <NA> <NA>
4 Levels: Not at all important < Not very important < ... < Very importantEl argumento levels está pensado para definir el orden de los niveles, de menor a mayor, mientras que el argumento labels está pensado para definir las etiquetas de cada nivel.
Podemos comprobar que R ha codificado la variable correctamente de varias maneras:
- Con la función
class()nos aparecerá «ordered» «factor». - Imprimiendo el marco de datos nos aparecerá
<ord>encima de la columna en cuestión. - Con la función
unique()veremos el orden de los niveles. - Imprimiendo el vector también veremos el orden de los niveles.
wvs_recod$Q4[1:3][1] Very important Not very important Not at all important
4 Levels: Not at all important < Not very important < ... < Very importantSi nos fijamos en el libro de códigos de la WVS, veremos que muchísimas variables siguen la misma escala ordinal; sin ir más lejos, las variables de la Q1 a la Q6. Recodificarlas una por una puede ser muy laborioso. Por suerte, más adelante veremos que no es necesario realizar este procedimiento, sino que con varias funciones del paquete dplyr podemos recodificar todas las variables de una vez con el mismo código. En la tabla 12.3 vemos el ejemplo y el resultado:
| A_WAVE | C_COW_ALPHA | C_COW_NUM | A_YEAR | Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 7 | MAL | 820 | 2018 | Very important | Rather important | Very important | Very important | Not at all important | Rather important | 1 | 1 |
| 7 | GMY | 255 | 2018 | Rather important | Very important | Rather important | Not very important | Very important | Not at all important | 1 | 1 |
| 7 | KZK | 705 | 2018 | Rather important | Rather important | Rather important | Not at all important | Rather important | Not at all important | 1 | 1 |
| 7 | RUS | 365 | 2017 | Very important | Very important | Rather important | Not very important | Very important | Not very important | 1 | 2 |
| 7 | KZK | 705 | 2018 | Very important | Rather important | Rather important | Not at all important | Very important | Very important | 2 | 2 |
| 7 | SRB | 345 | 2017 | Very important | Very important | Very important | Very important | Very important | Very important | 1 | 2 |
| 7 | AUL | 900 | 2018 | Very important | Very important | Very important | Very important | Very important | Not at all important | 1 | 1 |
| 7 | MEX | 70 | 2018 | Very important | Rather important | Very important | Not at all important | Very important | Very important | 1 | 2 |
12.6 Funciones genéricas
También tenemos funciones de recodificación genéricas que permiten cambiar la clase de vector.
Normalmente, utilizaremos estas funciones cuando observemos que alguna variable no tiene la clase de vector que le correspondería. Por ejemplo, supongamos que cuando exploramos el marco de datos polity nos damos cuenta de que todos los vectores son de carácter.
# A tibble: 9 × 3
country year polity2
<chr> <chr> <chr>
1 United States 1776 0
2 Bolivia 1825 -3
3 Australia 1901 10
4 Azerbaijan 1991 -3
5 USSR 1922 -7
6 Timor Leste 2002 6
7 Eritrea 1993 -6
8 Qatar 1971 -10
9 Gambia 1965 8 En este caso, tendremos que recodificar las dos últimas variables para que tengan el vector numérico.
polity$year <- as.numeric(polity$year)
polity$polity2 <- as.numeric(polity$polity2)