Conjuntos de datos
Cuando utilizamos el análisis cuantitativo en Ciencias Sociales, una de las primeras cosas que realizamos –explícita o implícitamente– es definir el contenido del mundo social, convertirlo en fenómenos medibles y recopilarlo y sistematizarlo en conjuntos de datos que nos permitan estudiar estos fenómenos. Esta es una tarea que muchas veces nos puede parecer que «viene dada», porque habitualmente otra persona habrá recogido los datos por nosotros, los habrá sistematizado y ubicado en una base de datos para que los podamos utilizar. Pero quien se dedique al análisis de datos no tiene que olvidar que antes del análisis debe realizarse un paso previo que consiste en observar el mundo, describir los elementos que existen y cuantificarlos de una forma que los podamos estudiar.
De manera muy resumida, el proceso de cuantificación funciona como vemos en la figura 1. Tanto en el mundo físico como en el mundo social, los datos no existen. La humanidad, a lo largo de la historia, ha ido estructurando su forma de pensar de acuerdo con ideas y ha ido definiendo de una manera más o menos clara los objetos que conocemos. Así, hemos cuantificado el paso del tiempo en años, tomando como unidad la rotación entera de la Tierra alrededor del Sol y, en las culturas de tradición cristiana, como valor cero el nacimiento de Cristo. Lo mismo hemos hecho para construir otras unidades de medida o para clasificar toda clase de objetos. Primero los hemos tenido que delimitar a partir de definiciones precisas. Por ejemplo, hemos construido la categoría ‘árbol’ y a partir de una definición clara hemos distinguido los árboles de otros objetos similares como ‘arbustos’ o ‘plantas’. Así, hemos podido estudiar los árboles, con sus características, como la anchura del tronco o la longitud, el color y la perennidad de sus hojas, y estudiar su relación con otros fenómenos como el clima, la altitud o la irregularidad del terreno.
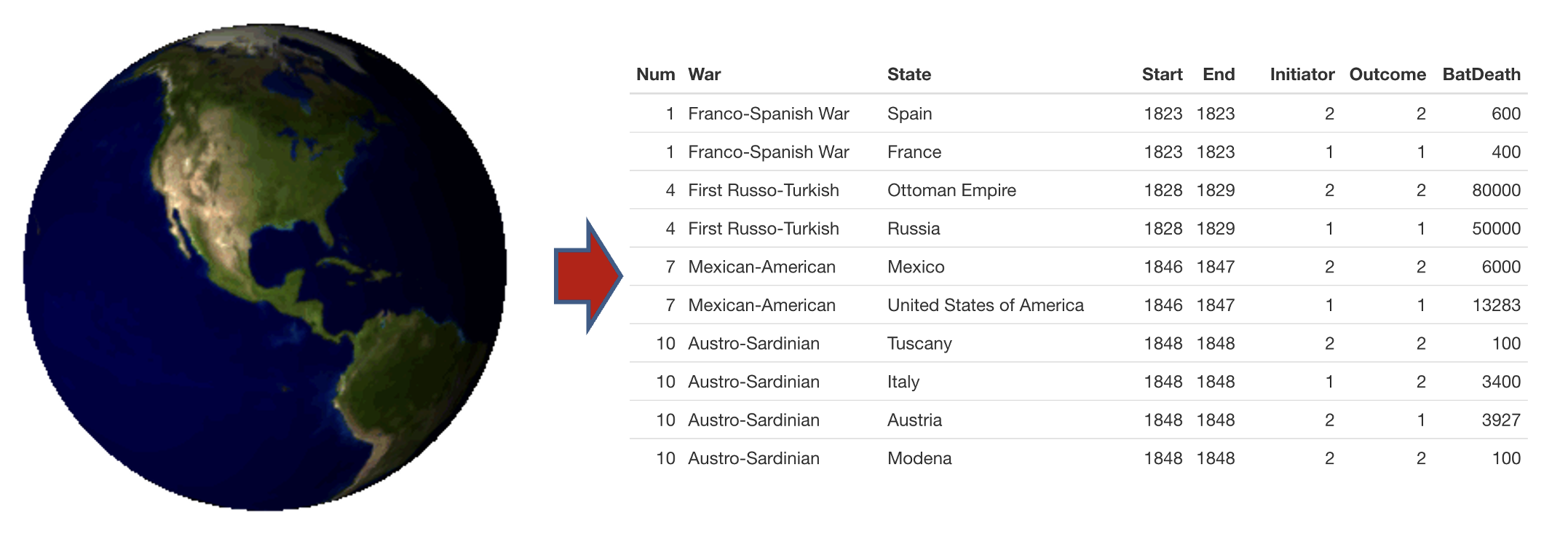
Los datos de la imagen se han obtenido de Intra-State War Data (v5.1) (Sarkees & Wayman, 2010). 
En el mundo social, el proceso de cuantificación ha funcionado de forma muy parecida al del mundo natural. Hemos construido fenómenos sociales como el suicidio, la democracia, la desigualdad, los estados o las guerras. Y para hacerlo siempre nos ha sido útil establecer definiciones precisas. Gracias a esto hemos podido capturar estos fenómenos, los hemos distinguido de otros fenómenos parecidos y hemos establecido medidas, siempre imperfectas, para analizarlos con el propósito de crear conocimiento sobre su comportamiento y su relación con otros fenómenos. Así, siguiendo los elementos que se muestran en la figura 1, en el ámbito académico se ha acabado determinando qué significa «iniciar una guerra», cuándo podemos considerar que termina una guerra o qué diferentes tipos de resultados puede haber. A pesar de que todas las medidas puedan tener cierta controversia, tener definido nuestro propósito –qué queremos investigar, qué preguntas queremos contestar– será siempre fundamental para una buena investigación (Anduiza et al., 2009).
A lo largo de este módulo, deberíamos ir familiarizándonos con algunas funciones de R que nos permitan explorar el marco de datos. Las más habituales, aplicadas a marcos de datos, son:
Y, aplicadas a vectores, son:
Una vez realizado este proceso conceptual, el siguiente paso para analizar cuantitativamente el mundo social es agrupar los datos sobre el fenómeno social que queremos estudiar en un dataset o conjunto de datos. Un conjunto de datos es una colección de valores que tiene las características siguientes (Wickham, 2014):
- Cada valor pertenece a una observación y una variable.
- Una observación contiene todos los valores medidos en la misma unidad (como una persona, un país, un partido político) entre atributos.
- Una variable contiene todos los valores que miden el mismo atributo subyacente (la ubicación ideológica, la riqueza o el grado de polarización) entre unidades.
En este módulo desglosaremos estos tres conceptos y veremos varios ejemplos de bases de datos relacionadas con las Ciencias Sociales, en especial de Ciencia Política, Sociología y Relaciones Internacionales. En el primer capítulo veremos las observaciones, en el segundo las variables y en el tercero cómo modificar las variables. A lo largo de estos capítulos nos referiremos a menudo a términos muy similares: bases de datos, conjuntos de datos, marcos de datos o, simplemente, datos. En la práctica son conceptos casi intercambiables, pero merece la pena tener en cuenta las diferencias terminológicas entre ellos.
Hay conceptos muy parecidos, casi intercambiables, que merece la pena definir:
- Tabla (table): conjunto de elementos o figuras mostradas de manera sistemática, normalmente en columnas. Casi cualquier cosa puede ser una tabla, por ejemplo, la tabla periódica, la tabla de multiplicar, la tabla fonética, etc.
- Base de datos (database): agrupación almacenada de datos a la que se puede acceder electrónicamente. Es el término más común y genérico. Se puede referir a varios conjuntos de datos, como el catálogo de una biblioteca o cualquier buscador de internet.
- Conjunto de datos (dataset): colección estructurada de datos, generalmente asociada a un conjunto único de trabajo. Suele ser más concreto que una base de datos.
- Hoja de cálculo (spreadsheet): documento electrónico en el cual los datos se ordenan en filas y columnas. El ejemplo más claro es el que utiliza Microsoft Excel.
- Marco de datos (dataframe): tipo de objeto de R que permite almacenar datos en dos dimensiones: filas y columnas. Todo marco de datos es un conjunto de datos o una base de datos, pero no todos los conjuntos y las bases de datos son marcos de datos.