La estructura de datos de R
La estructura de datos de R acaba siendo extremadamente sencilla para cualquier usuario que haya dedicado unas horas al aprendizaje de este lenguaje de programación. Pero para llegar a este punto es necesario tener muy claras algunas reglas muy básicas de su funcionamiento. Si entendemos estas reglas sencillas, nos será muy fácil e intuitivo trabajar con R. Es por esta razón por la que hay que seguir este módulo con muchísima atención. El día a día con R se basa en dos acciones clave: crear objetos y aplicar funciones a estos objetos. En primer lugar, en este módulo aprenderemos a crear objetos (1), que nos sirven para almacenar información. Principalmente, conoceremos tres formas diferentes de almacenarla:
- A. Los valores, que son la unidad más pequeña de R.
- B. Los vectores, que están formados per una cadena de valores.
- C. Y los marcos de datos, formados por varios vectores de igual longitud.
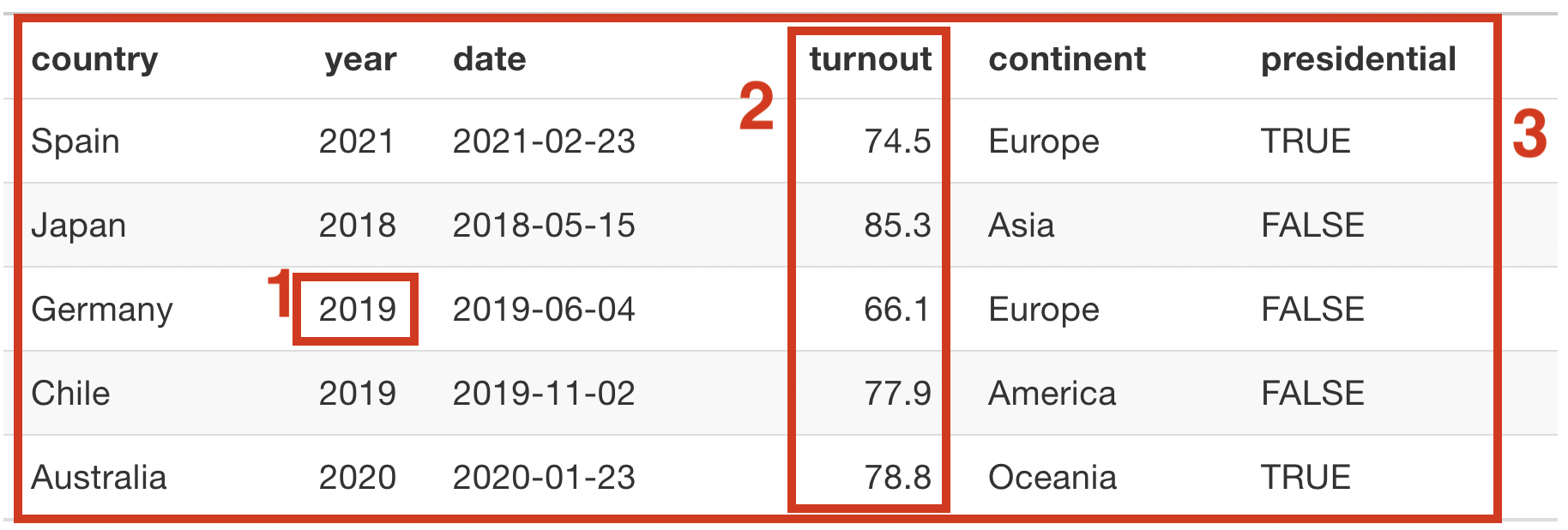
Fijémonos en el marco de datos que vemos en figura 1, que representa los datos de participación en las últimas elecciones de varios países. El marco de datos (C) está formado por varios vectores (B). Cada vector está representado en una columna distinta del marco de datos. Todos los vectores de un marco de datos tienen igual longitud. En ese ejemplo, todos los vectores son de longitud cinco. Esto significa que cada vector está formado por cinco valores (A). Cada valor es una casilla del marco de datos y es la unidad más pequeña de R que vamos a estudiar.
Para crear este marco de datos hemos utilizado el siguiente código. Como ves, lo hemos almacenado en el objeto elections. Necesitaremos tener cargado el paquete dplyr, necesario para ejecutar la función tibble():
elections <- tibble(country = c("Colombia", "Japan", "Germany", "Chile", "New Zealand"),
year = as.integer(c(2022, 2021, 2021, 2021, 2020)),
date = as.Date(c("2022/05/29", "2021/10/31", "2021/09/26", "2021/11/21", "2020/10/17")),
turnout = c(54.98, 55.97, 76.58, 47.33, 82.24),
continent = factor(c("America", "Asia", "Europe", "America", "Oceania")),
presidential = c(TRUE, FALSE, FALSE, TRUE, FALSE))Como hemos avanzado anteriormente, la segunda acción clave del trabajo con R es aplicar funciones (2) a objetos de R. A lo largo de este módulo iremos conociendo diversas funciones, aunque a continuación veremos unos ejemplos. En cada pestaña aplicamos una función diferente al objeto elections.
Cuando aplicamos la función dim() a un marco de datos, nos devuelve un vector con dos valores. El primer valor representa la cantidad de filas y el segundo valor, la cantidad de columnas del marco de datos.
Si aplicamos la función dim() al marco de datos elections, observamos que el marco de datos tiene cinco filas y seis columnas.
dim(elections)
## [1] 5 6La función unique() nos devuelve los valores únicos de un vector. Esto nos permite saber cuántas categorías distintas tiene un vector.
Si aplicamos la función unique() al vector year del marco de datos elections, observamos cómo nos devuelve tres valores, porque el 2021 está repetido y solo nos devuelve los valores ‘únicos’.
unique(elections$year)
## [1] 2022 2021 2020También podemos saber rápidamente cuál es la media de los valores de un vector con la función mean().
Si aplicamos la función mean() en el marco de datos elections, nos permite averiguar la media de participación (turnout) de los cinco países de los que tenemos datos.
mean(elections$turnout)
## [1] 63.42El principal objetivo de este módulo es conocer la estructura de los marcos de datos y de las funciones de R. Por eso aprenderemos a crear marcos de datos y aplicaremos funciones. Debemos confesar, sin embargo, que un analista de datos raramente crea marcos de datos desde cero con R. Esto suele dejarse para otros programas como, por ejemplo, Microsoft Excel. En R normalmente se empieza a partir de la importación de datos, creados previamente, para poder trabajar con el programa. Aún así, es importante aprender a crear marcos de datos porque así podemos familiarizarnos con su estructura, lo que nos será imprescindible para hacer funcionar R con agilidad y explotar las ventajas que nos ofrece el programa.
Antes de empezar, recapitularemos algunas ideas clave.
Idea clave
Trabajar con R consiste más o menos en hacer lo siguiente:
- Cargar los paquetes que necesitamos.
- Crear objetos, que encontraremos en los paquetes o que crearemos a partir de importar alguna base de datos.
- Aplicar funciones a los objetos, que nos permitirá transformar, analizar y visualizar los datos que tienen almacenados.
Vamos a ver detalladamente, en los próximos apartados, qué son los objetos y las funciones.