12 Otras capas
12.1 Introducción
Ya se ha visto cómo, con la explotación de las tres capas básicas de ggplot2, se pueden generar gráficas de todo tipo. Hasta ahora se ha mostrado cómo, a partir de las tres capas esenciales (marco de datos, proyección estética y geometría), se pueden comunicar los resultados de la información disponible de muchas maneras diferentes. Solo con tres capas hay bastante, ya sea combinando diferentes variables a partir de proyecciones estéticas o usando una gran variedad de geometrías —siempre adecuadas a la tipología de los datos en cuestión.
Ahora bien, al principio de este capítulo se ha indicado que las gráficas de ggplot2 admiten más de tres capas. Y, a pesar de que con tres capas ya se puede resumir adecuadamente la información, es importante introducir el resto de capas, que, si bien no son imprescindibles, suelen ser muy útiles para comunicar de manera efectiva la información. Estas capas permiten modificar la presentación de la gráfica —no sus contenidos— para que una gráfica pueda ser autoexplicativa. Para explicar las capas adicionales de una gráfica, se partirá del diagrama de dispersión básico con el que se ha iniciado el capítulo y que pone en relación los niveles de innovación de las regiones y la satisfacción con el gobierno.
12.2 Escalas
La primera de las capas adicionales es la que hace referencia a las escalas de la gráfica. Por escala se debe entender la manera de representar la información de los diferentes estéticos de la gráfica. Podemos distinguir entre dos tipos de escala:
- Las escalas de eje, que sirven para modificar el contenido de los ejes
xey. - Las escalas de colores, que sirven para modificar el contenido de la mayoría de las geometrías, marcadas principalmente por los estéticos
colorofill.
En ambos casos, todas las funciones que modifican la escala empiezan con scale_, seguido del eje o estético que se quiere modificar, una barra baja y, finalmente, el tipo de escala.
12.2.1 Escalas de eje
En las funciones que modifican la escala de eje se especifica scale_, seguido del eje que se quiere modificar (x o y), una barra baja y, finalmente, el tipo de variable (continuous si es numérica y discrete si es categórica). Así, utilizaremos1:
1 Con las funciones de escala, también se puede modular la escala de unidades de visualización de los ejes. Esto puede ser útil en el caso de tener variables numéricas con casos extremos o valores sesgados hacia un lado de la distribución. Una deformación típica de los datos es la escala logarítmica; añadiendo la función scale_x_log10() a ggplot2 se podría mostrar una variable en su transformación logarítmica.
-
scale_x_continuous(): si en el eje \(x\) tenemos una variable numérica. -
scale_x_discrete(): si en el eje \(x\) tenemos una variable categórica. -
scale_y_continuous(): si en el eje \(y\) tenemos una variable numérica. -
scale_y_discrete(): si en el eje \(y\) tenemos una variable categórica.
Una vez definida la función, hay varios argumentos para introducir información o modular la gráfica. Los más importantes son los siguientes2:
2 Los argumentos breaks y limits se usan en variables de tipo cuantitativo.
-
name: define, entre comillas, el título del eje. -
breaks: define las marcas de valores principales que aparecen en la gráfica. -
minor_breaks: funciona igual que el anterior pero para definir las marcas secundarias de las gráficas. -
labels: indica las etiquetas de texto para cada una de las rupturas (breaks) del eje. -
limits: establece los límites del eje, definidos por un valor mínimo y un valor máximo3.
3 Es importante vigilar a la hora de definir estos valores porque esto puede dejar fuera observaciones existentes en el marco de datos. Si no se indica, por defecto comprende desde el valor mínimo hasta el valor máximo de la variable. Otra manera de definir los límites de las gráficas sin recurrir a las escalas es a través de las funciones xlim() o ylim(), indicando simplemente los valores mínimo y máximo para cada eje. Estas dos funciones son una manera más rápida de marcar los límites de la gráfica, pero solo funcionan cuando no se utilizan las funciones de tipo scale_.
Dada la gran cantidad de argumentos, familiarizarse con las escalas es un proceso lento. Es por eso que una manera de aprender su uso es comparando diferentes ejemplos. A continuación se muestra la relación entre grado de innovación regional y satisfacción con el gobierno en una gráfica ggplot2 sin escalas. En las otras pestañas se muestra la misma gráfica pero con modificaciones en las escalas de eje a partir de los argumentos que se acaban de exponer.
nuts |>
ggplot(mapping = aes(x = innov, y = stfgov)) +
geom_point()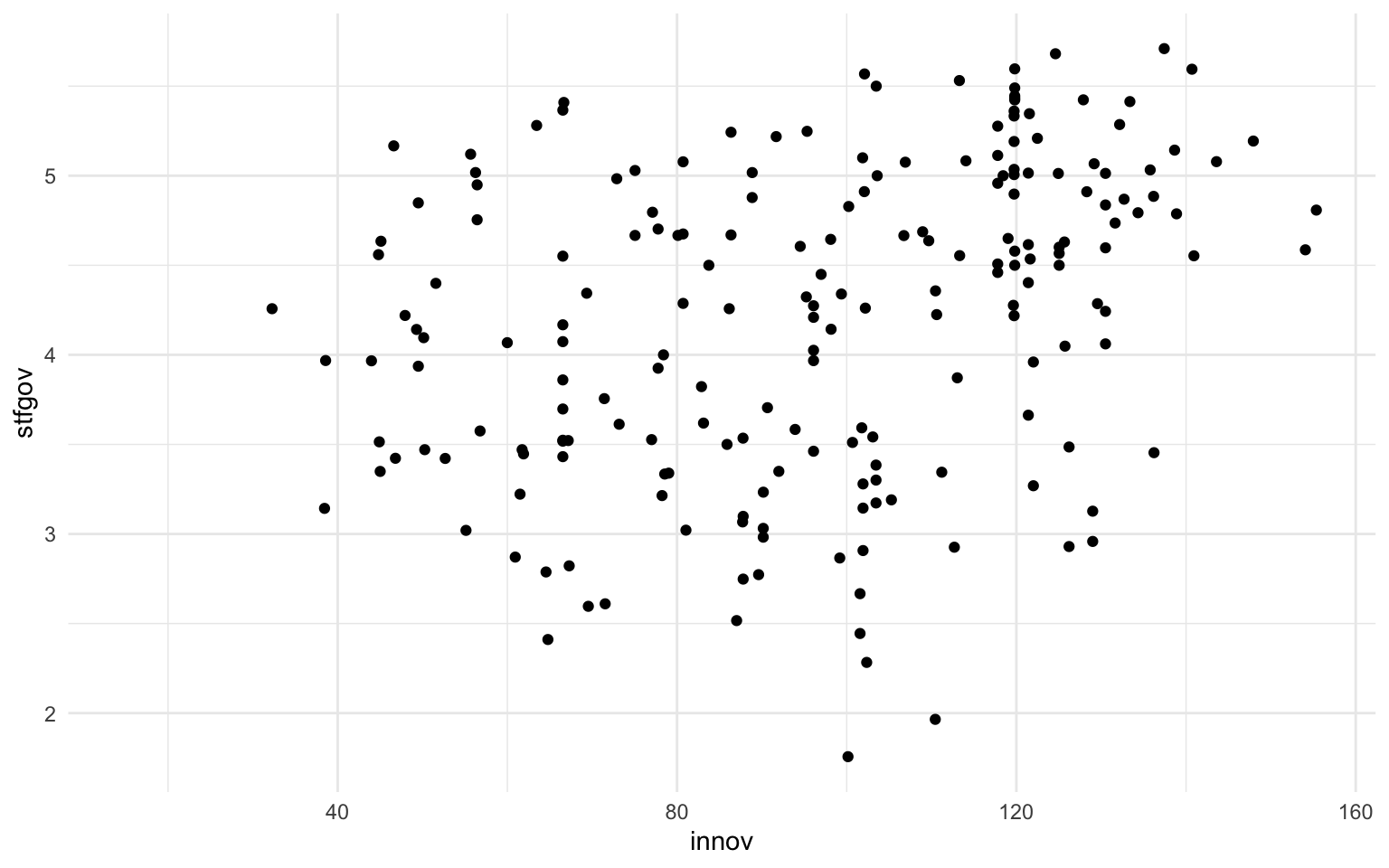
nuts |>
ggplot(mapping = aes(x = innov,y = stfgov)) +
geom_point() +
scale_x_continuous(name = "Grado de innovación regional") +
scale_y_continuous(name = "Satisfacción con el gobierno")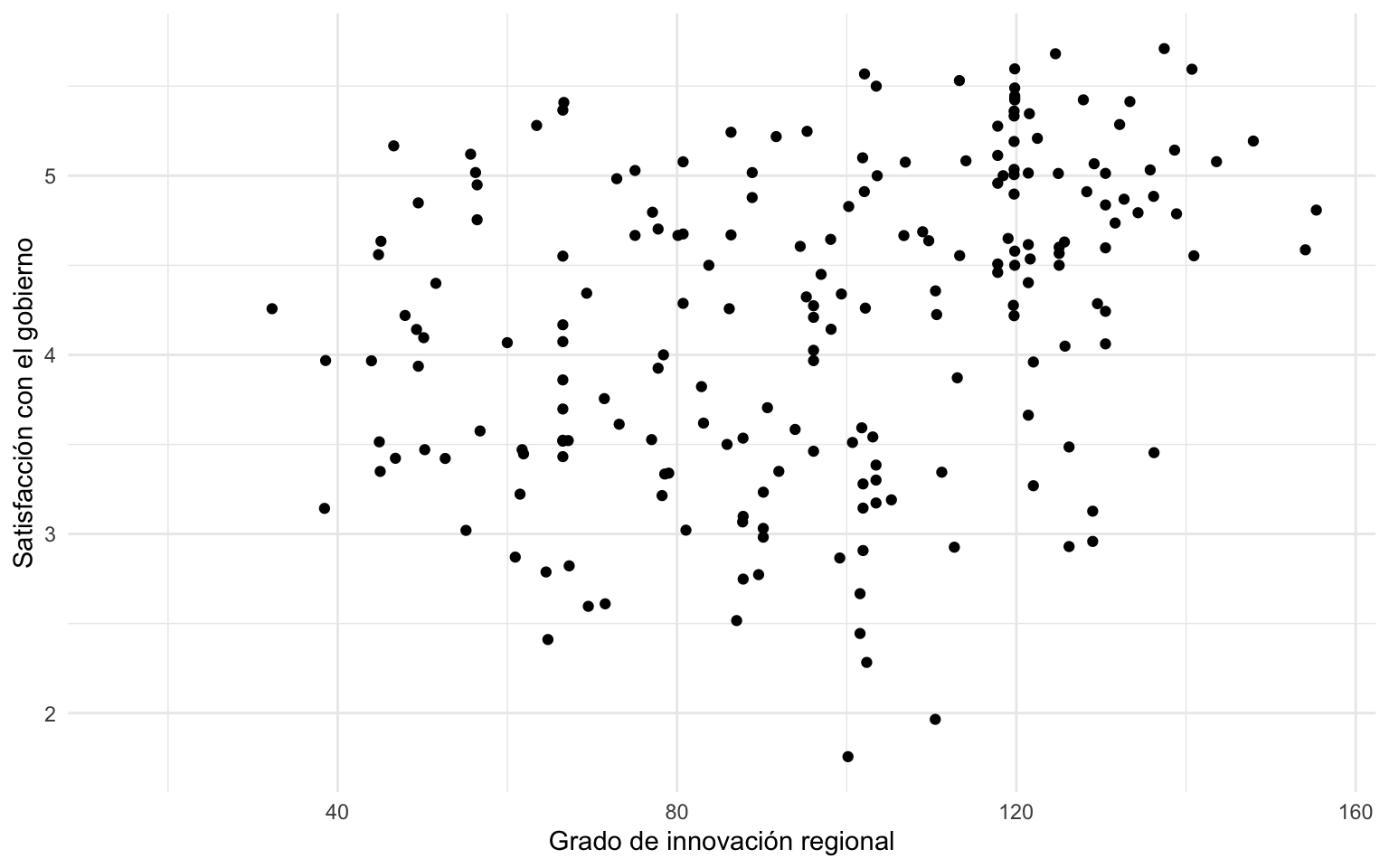
nuts |>
ggplot(mapping = aes(x = innov,y = stfgov)) +
geom_point() +
scale_x_continuous(name = "Grado de innovación regional",
limits = c(10, 170)) +
scale_y_continuous(name = "Satisfacción con el gobierno")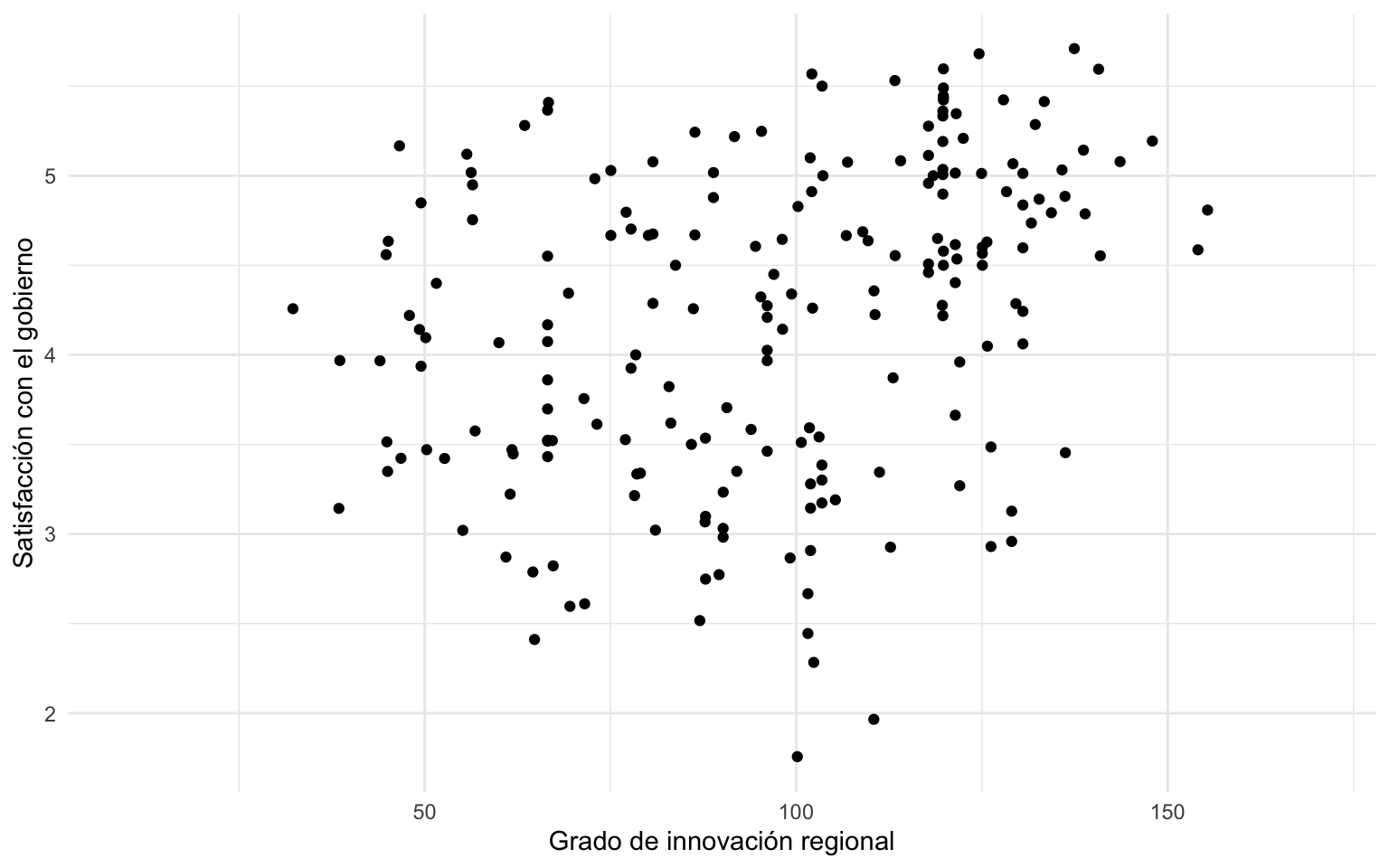
nuts |>
ggplot(mapping = aes(x = innov,y = stfgov)) +
geom_point() +
scale_x_continuous(name = "Grado de innovación regional",
limits = c(10, 170)) +
scale_y_continuous(name = "Satisfacción con el gobierno",
n.breaks = 4,
labels = c("Muy baja", "Baja", "Media", "Alta", "Muy alta"))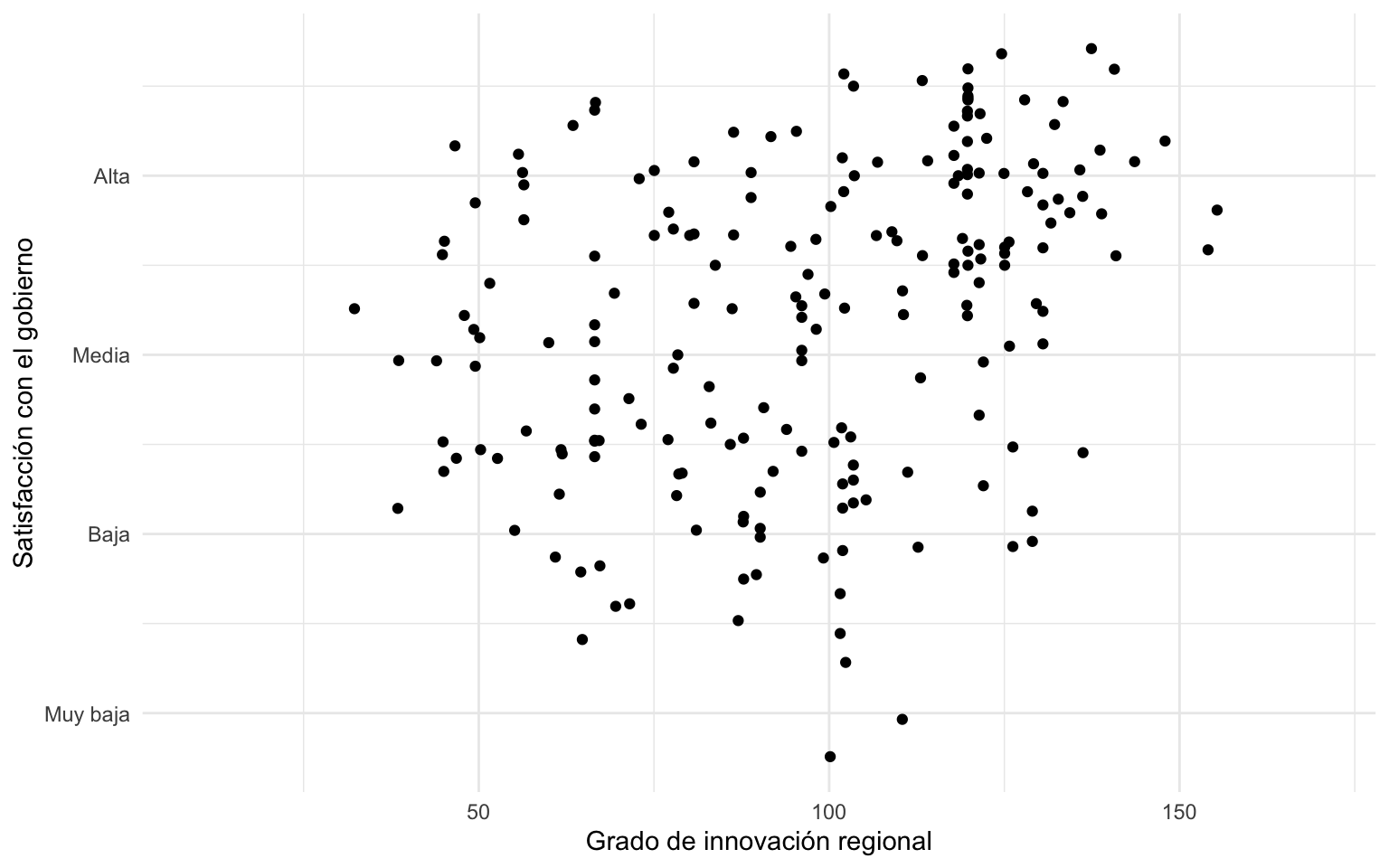
nuts |>
ggplot(mapping = aes(x = innov,y = stfgov)) +
geom_point() +
scale_x_continuous(name = "Grado de innovación regional",
limits = c(10, 170),
breaks = c(50, 100, 110, 120, 130, 140, 150)) +
scale_y_continuous(name = "Satisfacción con el gobierno",
n.breaks = 4,
labels = c("Muy baja", "Baja", "Media", "Alta", "Muy alta"))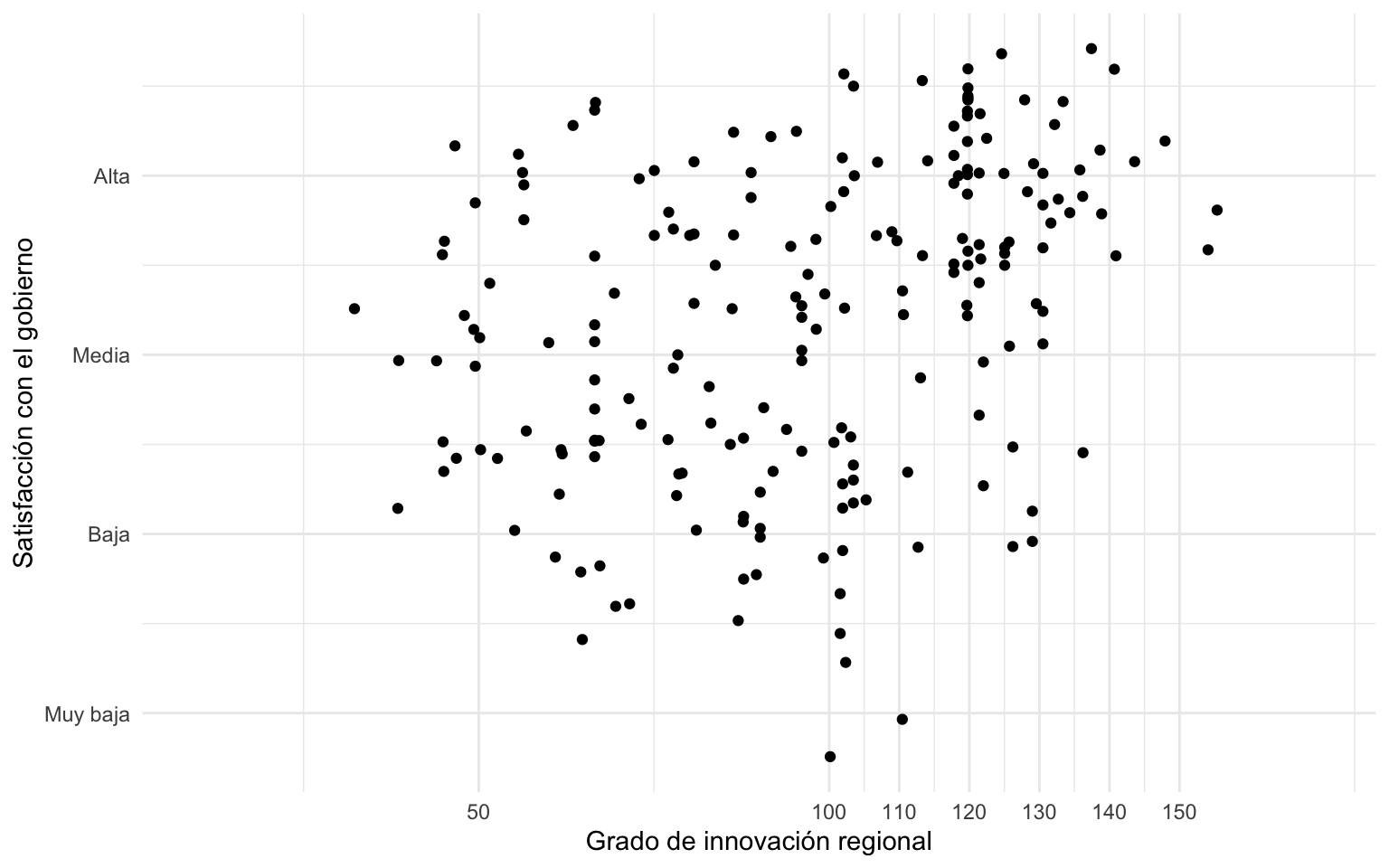
nuts |>
ggplot(mapping = aes(x = innov, y = stfgov)) +
geom_point() +
scale_x_continuous(name = "Grado de innovación regional",
breaks = seq(0, 160, by = 20),
limits = c(10, 160)) +
scale_y_continuous(name = "Satisfacción con el gobierno",
breaks = seq(0, 10, by = 1),
minor_breaks = seq(0, 10, by = .25))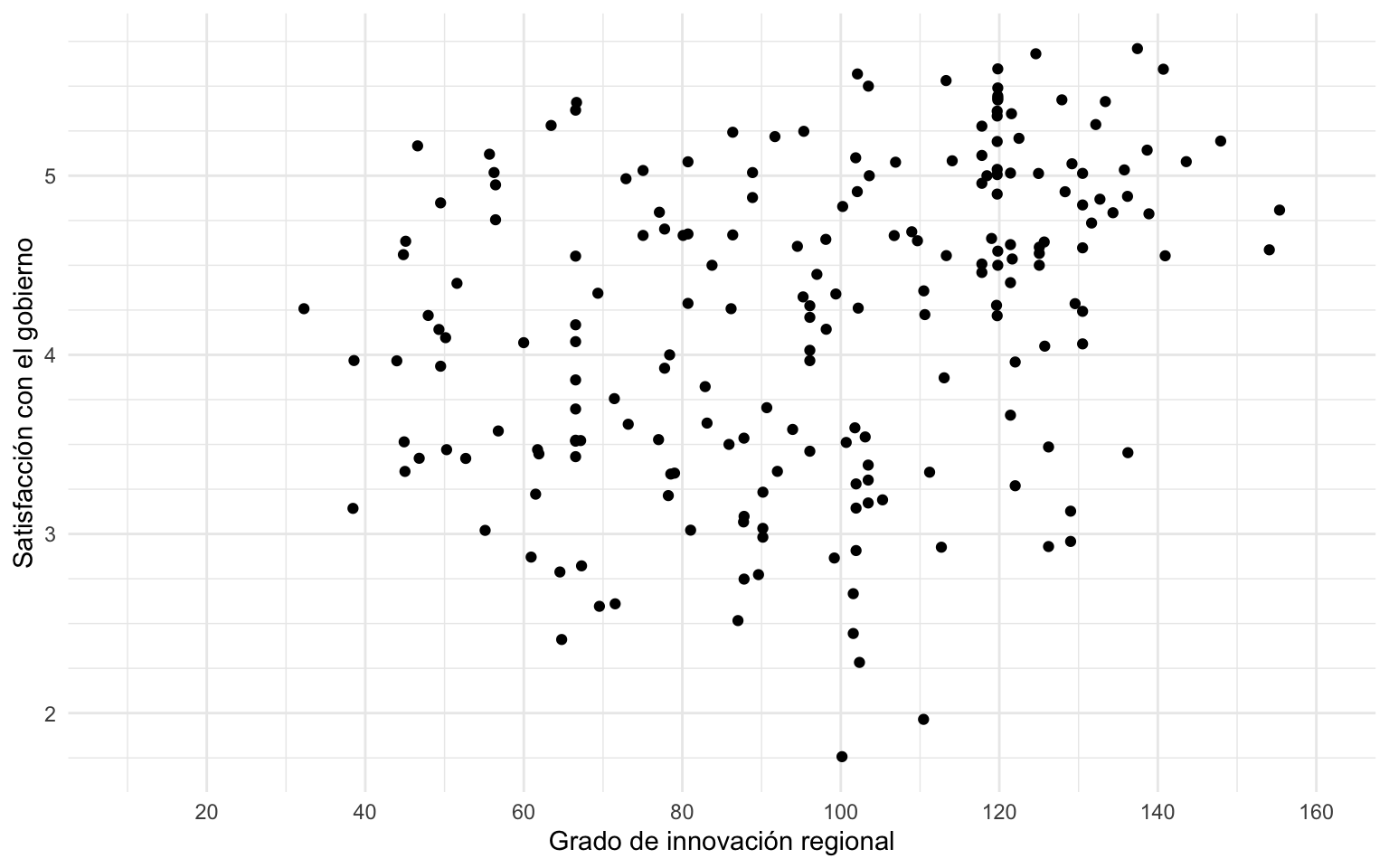
12.2.2 Escalas de colores
Con las funciones de tipo scale_, también se puede controlar la escala de los colores que aparecen en color y en fill. En este caso, la función empieza por scale_, seguido del tipo de estético (color o fill), una barra baja y la palabra brewer, gradient o manual, entre otros. Así, por ejemplo, para modificar el estético de color tendríamos las funciones siguientes:
-
scale_color_brewer(): en el caso de paletas de color cualitativas predefinidas. -
scale_color_manual(): en el supuesto de que queramos marcar colores cualitativos manualmente. -
scale_color_gradient(): en el caso de variables cuantitativas.
Podéis encontrar más información sobre las escalas de colores en esta web.
Por ejemplo, brewer es una opción que tiene paletas de colores preestablecidas por variables categóricas. Los diferentes argumentos de la función son los siguientes:
-
name. Define el nombre de la leyenda de colores. -
palette. Permite definir la paleta de color específica. ggplot2 tiene varias paletas de colores predefinidas —se puede consultar una lista aquí. Se pueden indicar con números o entre comillas especificando el nombre de la paleta de colores. -
type. Tiene tres posibilidades:"seq"establece colores secuenciales —recomendado para variables cuantitativas—,"div"establece colores divergentes y"qual"es para variables cualitativas. -
direction. Si se indica con el valor 1, el orden de los colores es el predefinido por la paleta; si se especifica con el valor –1, los colores se asignan en el orden inverso.
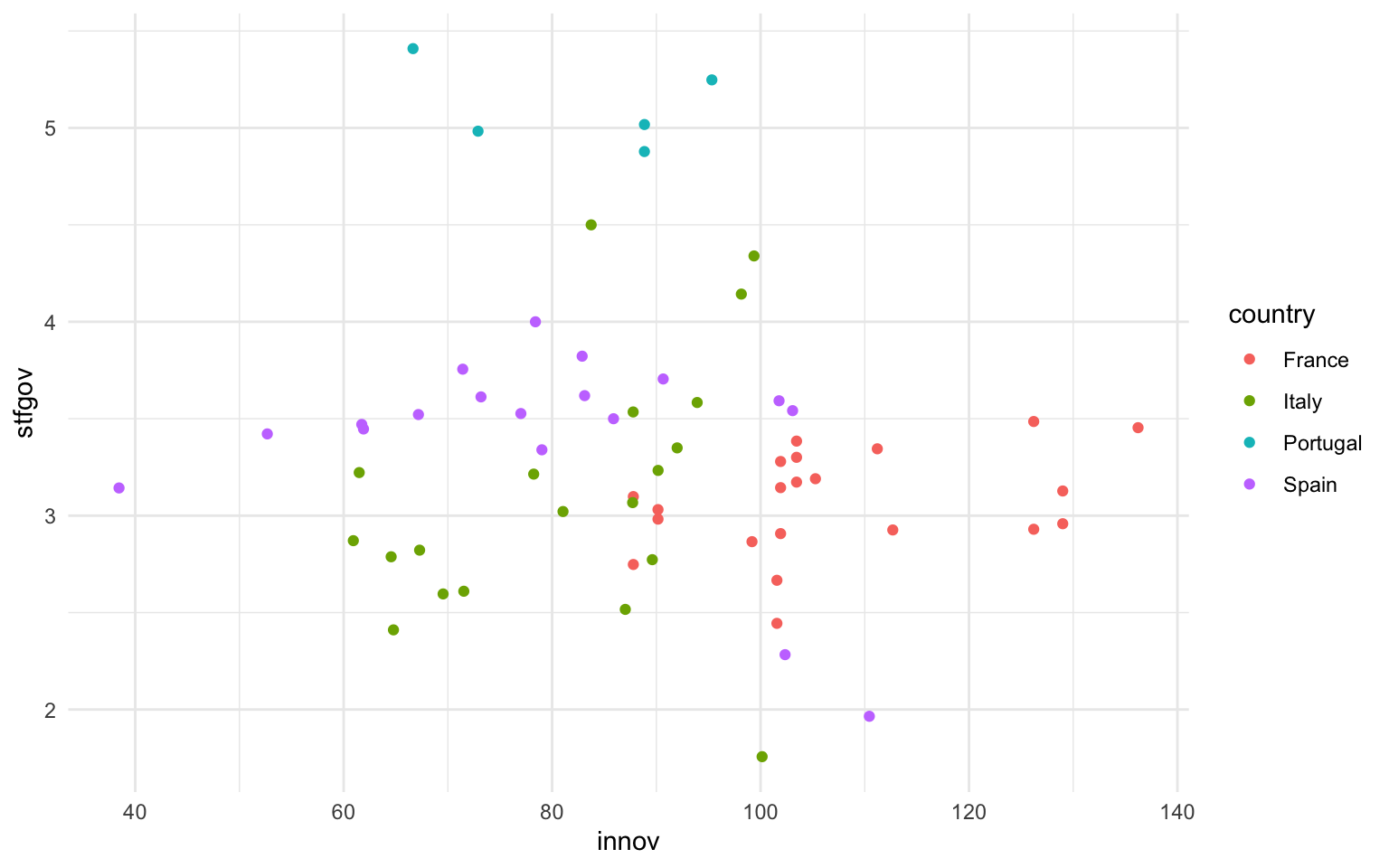
Siguiendo el mismo procedimiento que en el subapartado anterior, a continuación se muestran varias gráficas. En la figura 12.7 se muestra, en una gráfica ggplot2 sin escalas, la relación entre grado de innovación regional y satisfacción con el gobierno en España, Francia, Italia y Portugal. Y en las otras pestañas se muestra la misma gráfica pero con modificaciones en las escalas de colores a partir de los argumentos que se acaban de exponer. Fijaos que en manual simplemente se indican los colores manualmente y que en gradient se indican los colores máximo y mínimo entre los que variarán los valores de una variable cuantitativa.
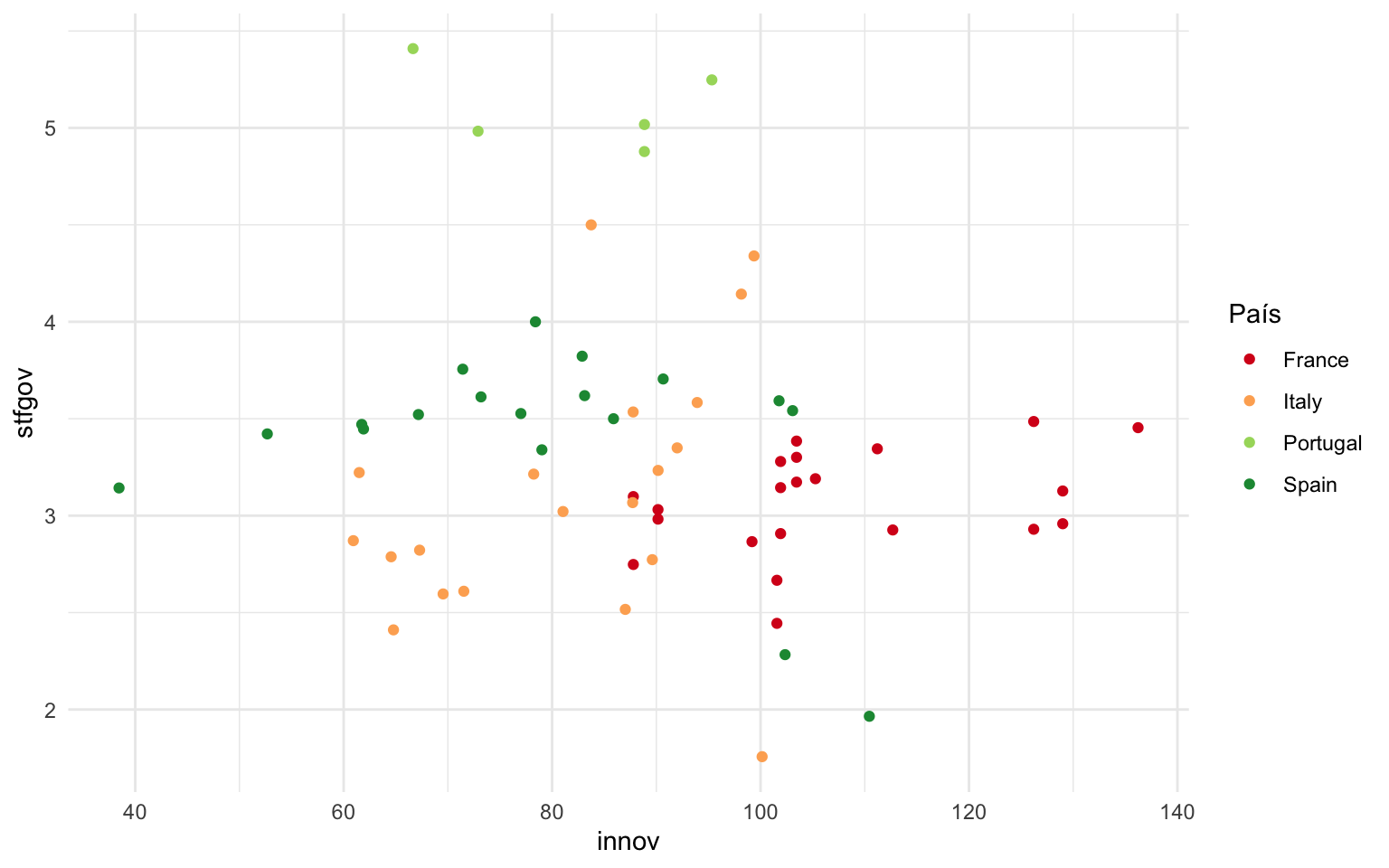
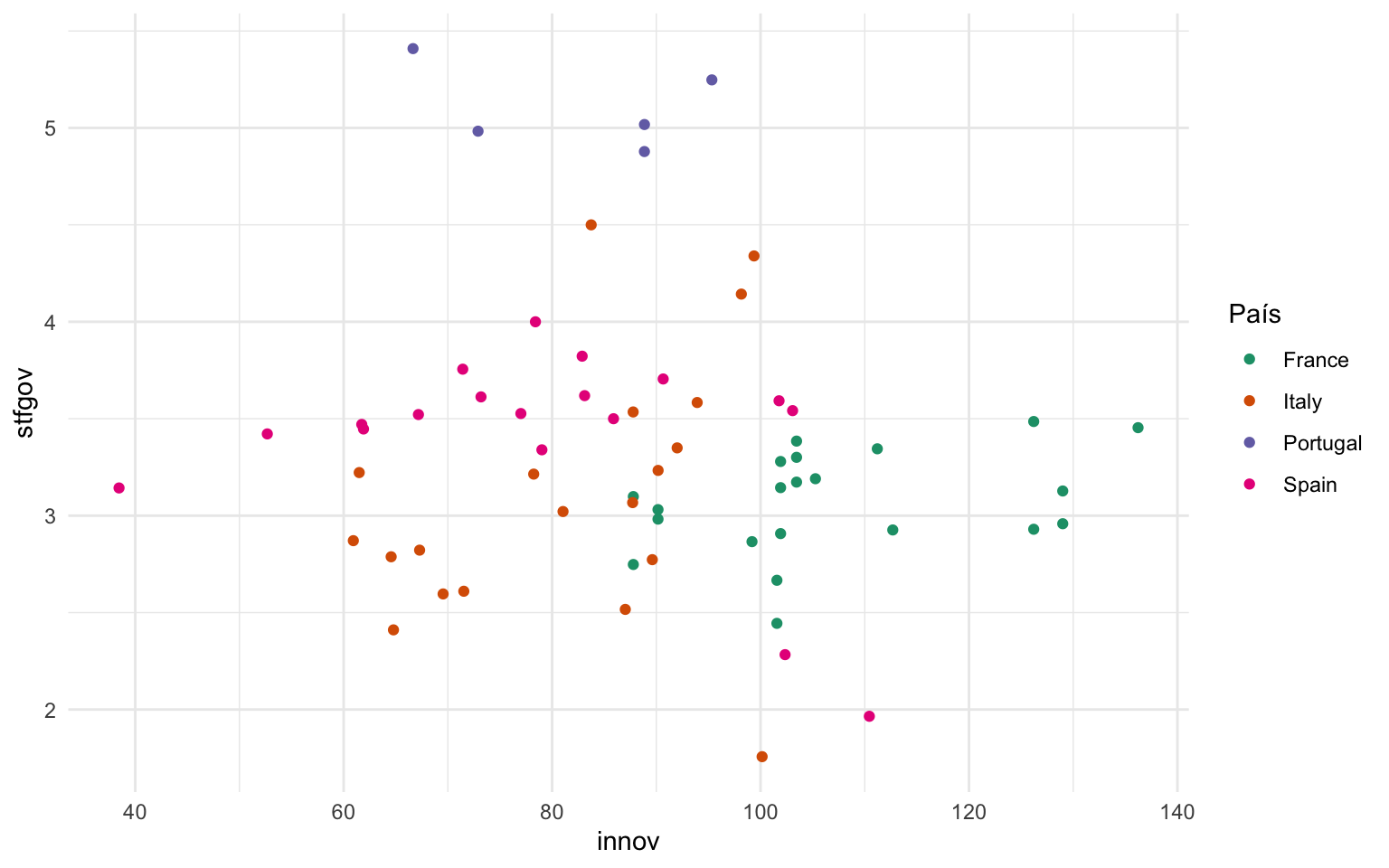
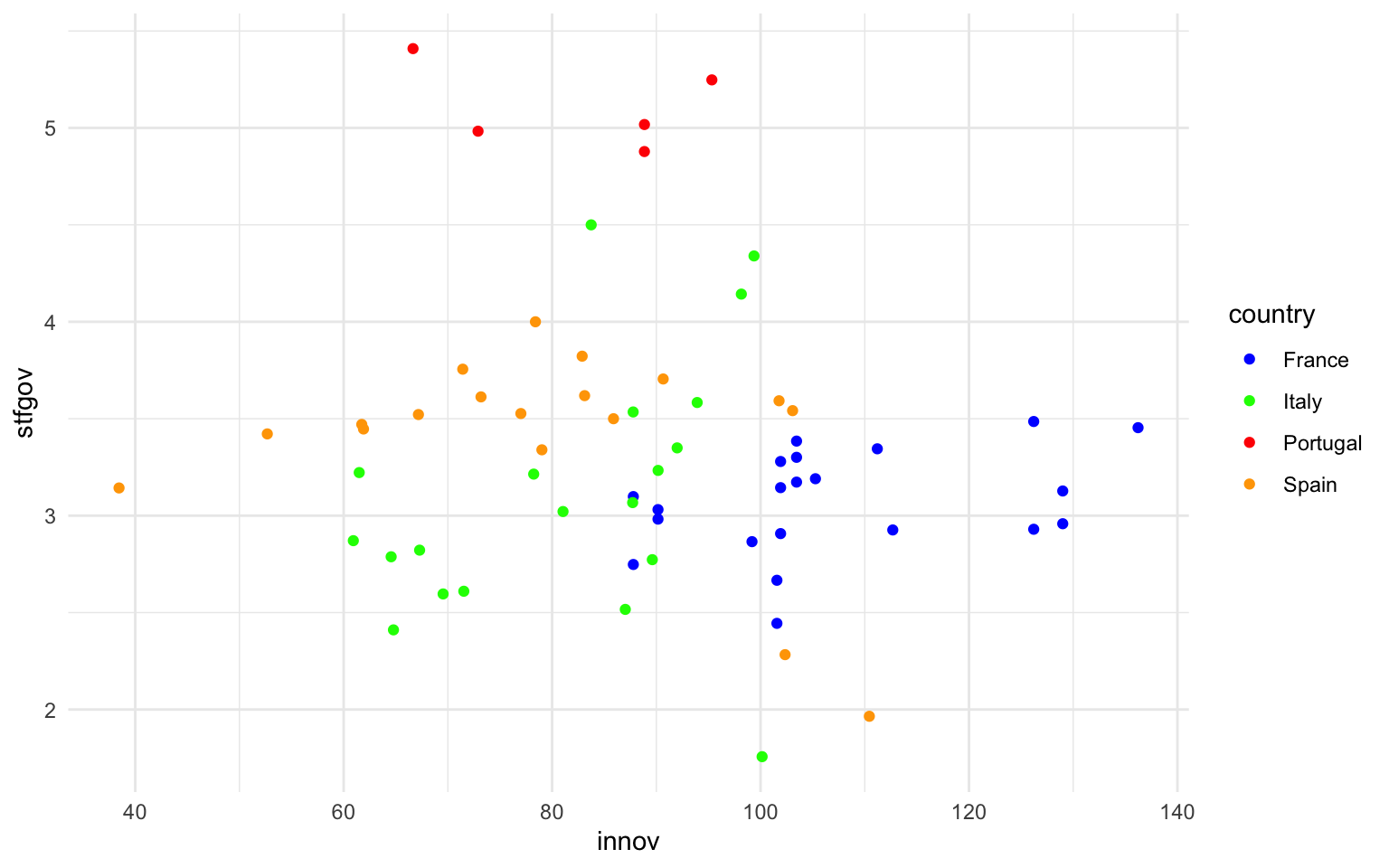
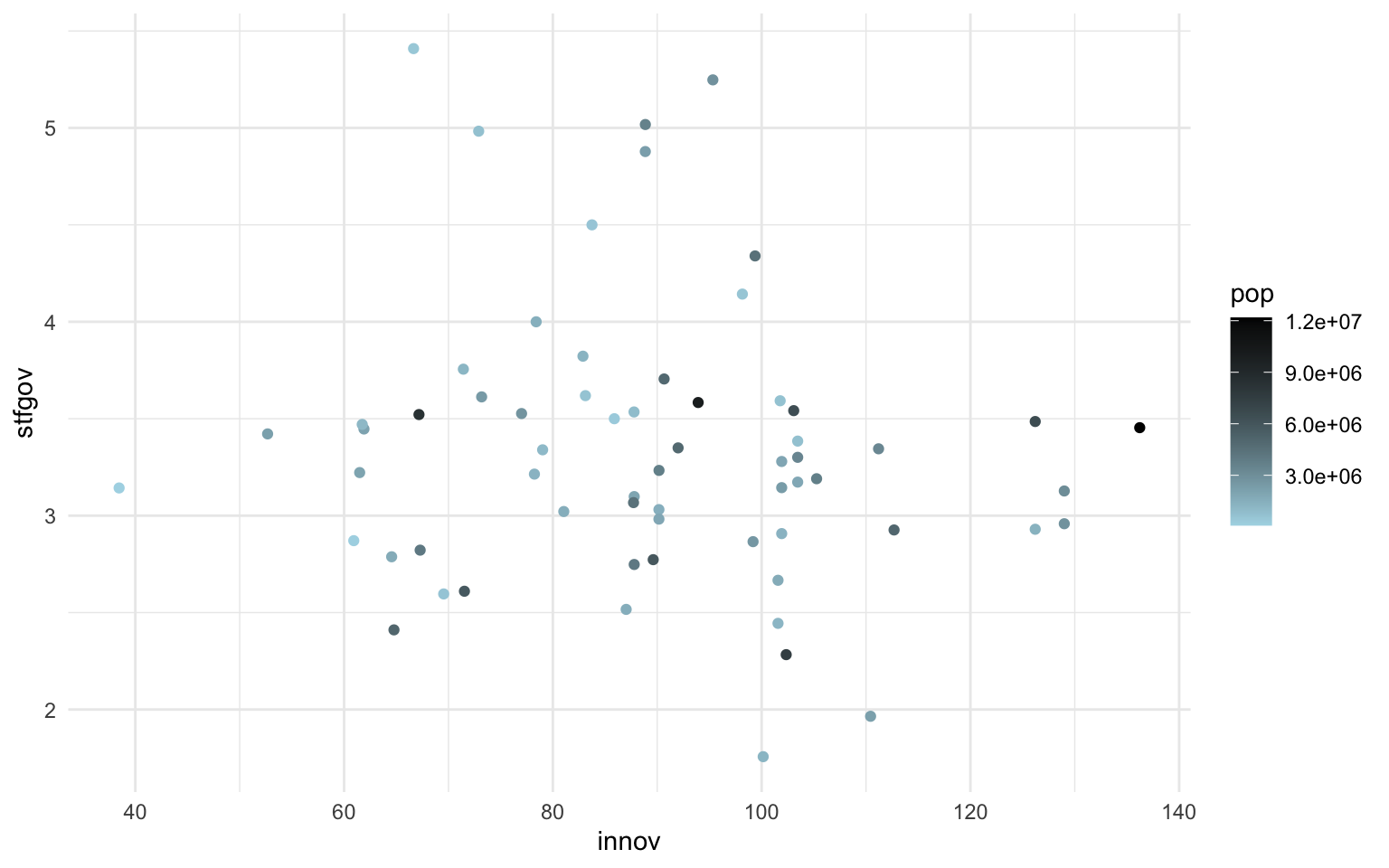
Con todo, una buena visualización de la gráfica, utilizando escalas de eje y de color, sería la que aparece en la figura 12.12:
Muestra código.
nuts |>
filter(ccode %in% c("ES", "FR", "IT", "PT")) |>
ggplot(mapping = aes(x = innov,y = stfgov,color = country)) +
geom_point(size = 2) +
scale_x_continuous(name = "Grado de innovación regional",
breaks = seq(0, 160, by = 20),
limits = c(10, 160)) +
scale_y_continuous(name = "Satisfacción con el gobierno",
breaks = seq(0, 10, by = 1),
minor_breaks = seq(0, 10, by = .25)) +
scale_color_brewer(palette = 8 , type = "div", name = "País")
Hay otras funciones similares que permiten controlar los colores asignados a la gráfica. Hay funciones del tipo scale_color_...() que llevan una paleta de colores predefinida. Por ejemplo:
-
scale_color_grey()mostrará una paleta de colores en escala de grises. -
scale_color_viridis_b()definirá una escala del tipo viridis para variables continuas.
12.3 Coordenadas
La capa de coordenadas controla las dimensiones de la gráfica. La mayoría de las gráficas con las que se trabaja más habitualmente son bidimensionales, como las que se han visto a lo largo de este apartado, y proyectadas sobre coordenadas cartesianas (con un eje \(x\) y un eje \(y\)). Existen, sin embargo, otros tipos de coordenadas, como por ejemplo las coordenadas polares, que son las que permiten crear gráficas de sectores como el de la figura 12.13:
nuts |>
filter(ccode %in% c("ES", "FR", "IT", "PT")) |>
group_by(ccode) |>
summarise(regiones = n()) |>
ggplot(aes(x=1, y = regiones, fill = ccode)) +
geom_col()+
coord_polar("y", start=0)+
theme_void()
Es importante remarcar que los diagramas circulares como el anterior no son muy recomendables, puesto que es bastante difícil evaluar y comparar el tamaño relativo de cada componente. Los diagramas de barras siempre serán preferibles a los diagramas de sectores.
La capa de coordenadas gana importancia a la hora de elaborar gráficas sobre cartografías. El hecho de que haya diferentes proyecciones de los mapas hace que la capa de coordenadas tenga que estar alineada con los datos y los archivos que representen las cartografías. La representación de mapas se escapa de los objetivos de este curso pero es un elemento en el que R tiene capacidades superiores respecto a otros programas estadísticos.
Una de las pocas aplicaciones relativamente frecuentes de la capa de coordenadas es la función coord_flip(). Esta función intercambia las dimensiones de la gráfica y hace que la información que tendría que aparecer en el eje de las \(x\) aparezca en el de las \(y\), y viceversa. Puede ser interesante, por ejemplo, cuando se hace una gráfica de barras con muchas categorías que cuestan de leer en el eje de las \(x\) y se pueden mostrar de manera más clara si las barras son horizontales en lugar de verticales. Así se puede ver en la figura 12.14, donde simplemente añadiendo la capa coord_flip() la gráfica pasa a representar las observaciones del diagrama de barras en el eje de las \(y\).
nuts |>
count(country) |>
filter(n > 10) |>
ggplot(aes(x = fct_reorder(country, n), y = n)) +
geom_col(fill = "dodgerblue2")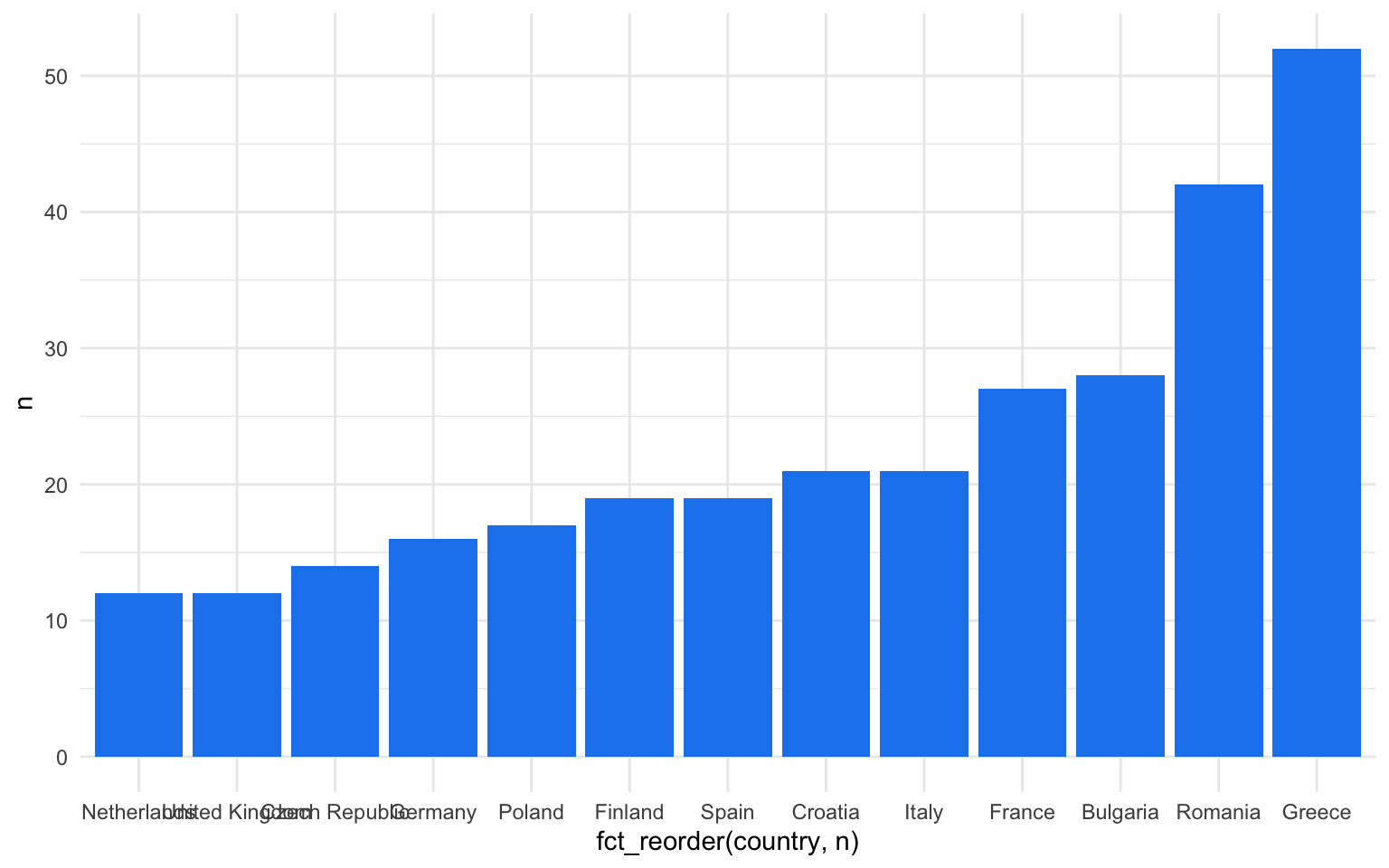
nuts |>
count(country) |>
filter(n > 10) |>
ggplot(aes(x = fct_reorder(country, n), y = n)) +
geom_col(fill = "dodgerblue2") +
coord_flip()
12.4 Títulos
Otro de los elementos importantes a la hora de crear una gráfica es asegurar que todos los elementos contextuales que ayuden a interpretarla correctamente estén muy especificados. Aquí tienen un papel crucial los títulos y etiquetas. Hay ciertos elementos clave que tienen que estar siempre muy especificados y que solo con leerlos tienen que permitir entender qué muestra la gráfica sin necesidad de leer el texto que la acompañará. El texto que acompaña a la gráfica tiene que acompañar al lector en su interpretación, pero no tendría que ser necesario para comprender los contenidos. Idealmente, las gráficas tendrían que ser autoexplicativas. Para conseguirlo, es necesario que los elementos siguientes estén muy especificados con la función labs()4:
4 En el apartado Section 12.2 también se ha visto que, cuando se modifican las escalas de los ejes, hay un argumento que permite definir los títulos de los ejes; ambas opciones son equivalentes pero es recomendable definir la información en la capa correspondiente.
-
Etiquetas de los ejes:
-
x: especifica el título del eje horizontal. -
y: especifica el título del eje vertical.
-
-
Título de la gráfica:
-
title: añade texto en el título. -
subtitle: añade texto al subtítulo. -
caption: añade texto como nota de la gráfica.
-
-
Guías o leyendas: Habrá que tener en cuenta qué variables están representadas como estéticos de la gráfica. Así, argumentos como
fill =,color =osize =permitirán definir el título de la leyenda (figura 12.16).
final <- nuts |>
filter(ccode %in% c("ES", "FR", "IT", "PT")) |>
ggplot(mapping = aes(x = innov, y = stfgov, color = country)) +
geom_point(alpha = 0.7) +
scale_x_continuous(breaks = seq(0, 160, by = 20)) +
scale_y_continuous(breaks = seq(0, 10, by = 1),
minor_breaks = seq(0, 10, by = .25))+
scale_color_brewer(palette = 8 , type = "div")+
labs(x = "Grado de innovación regional",
y = "Satisfacción con el gobierno",
color = "País",
title = "Relación entre innovación y satisfacción con el gobierno",
subtitle = "Análisis a nivel regional para cuatro países europeos",
caption = "Fuente de datos: Eurostat y Encuesta Social Europea")
final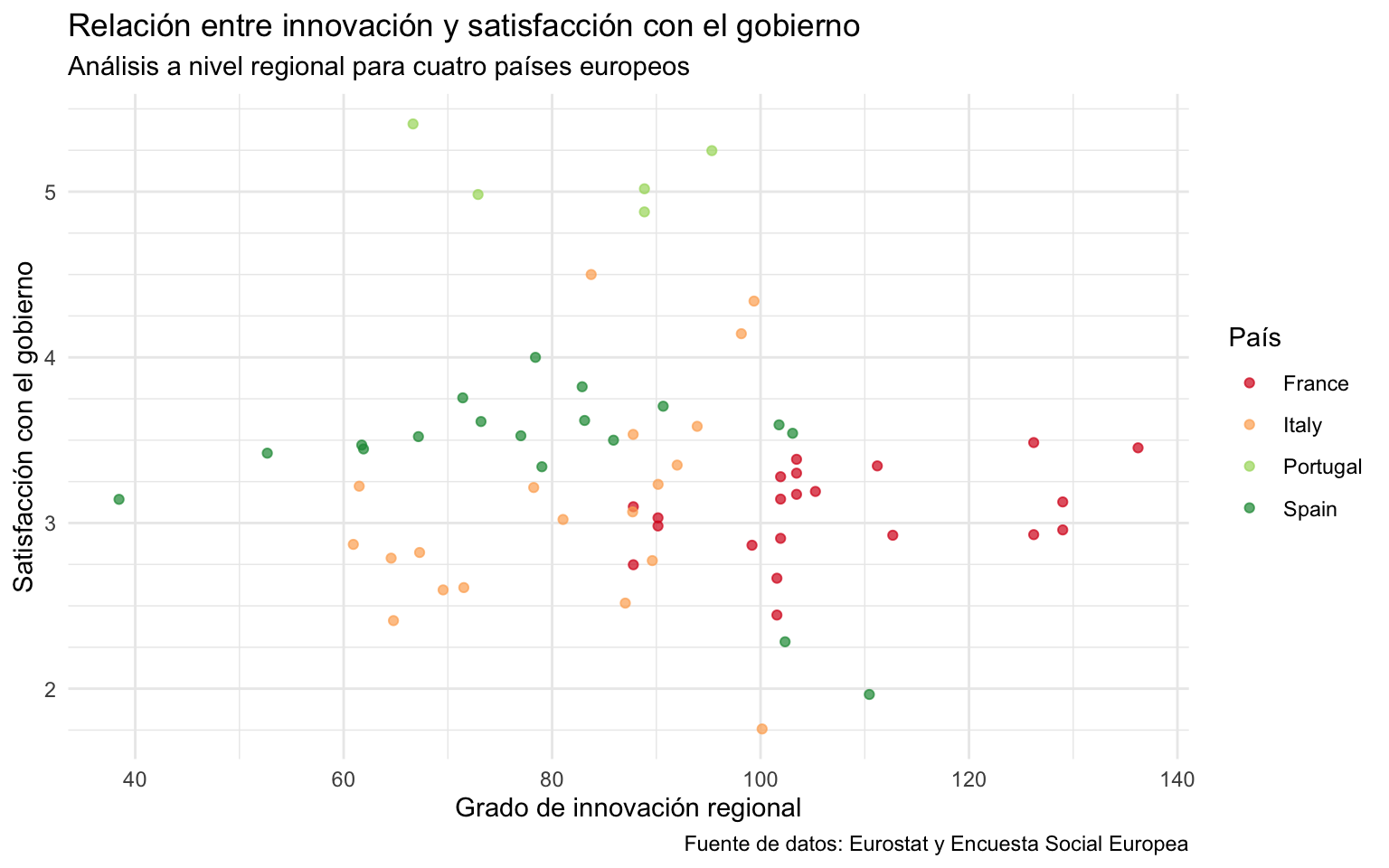
Una gráfica como la anterior tendría todos los elementos necesarios para estar a punto para su publicación. Como la gráfica ya contiene todos los elementos necesarios para ser legible por sí sola, se ha optado por guardarla en un objeto porque, si más adelante hubiera que añadir algo, no habría que volver a escribir todo el código de la gráfica.
12.5 Facets
La capa de facets se podría traducir como el aspecto o dimensión de un objeto. En ggplot2 esta capa sirve para dividir una visualización en varios paneles a partir de las diferentes categorías de una variable categórica. Esta capa se puede implementar con:
-
facet_wrap(): adecuado para visualizar una única dimensión de los paneles. -
facet_grid(): adecuado para visualizar dos dimensiones de los paneles.
En este enlace se pueden ver más ejemplos del funcionamiento de la capa de facet.
Se podría dar el caso que nos interesara mostrar la relación entre los niveles de innovación y de satisfacción con el gobierno, pero que, en lugar de distinguir los países de las regiones por colores, se optara por hacer una gráfica para cada país. Con la capa de facet, podríamos utilizar facet_wrap() para desplegar las gráficas horizontalmente, verticalmente o de manera mixta. La gráfica resultante que se observa en la figura 12.17 muestra la misma información que la gráfica generada en la sección Section 12.4, pero en este caso, en lugar de visualizar una única gráfica con toda la información, se generan tantas gráficas como países5.
5 En las gráficas se ha optado por mantener el estético de color, a pesar de que no es necesario; ahora bien, para evitar redundancias sí que se ha eliminado la leyenda de la gráfica con el argumento show.legend = FALSE.
En el argumento vars() marcamos la variable categórica que separará las gráficas y seguidamente el número de filas a nrow.
nuts |>
filter(ccode %in% c("ES", "FR", "IT", "PT")) |>
ggplot(mapping = aes(x = innov,y = stfgov, color = ccode)) +
geom_point(show.legend = FALSE)+
facet_wrap(facets = vars(ccode), nrow = 1)+
scale_x_continuous(breaks = seq(0, 160, by = 40)) +
scale_y_continuous(breaks = seq(0, 10, by = 1),
minor_breaks = seq(0, 10, by = .25))+
labs(x = "Grado de innovación regional",
y = "Satisfacción con el gobierno",
title = "Relación entre innovación y satisfacción con el gobierno",
subtitle = "Análisis a nivel regional para cuatro países europeos",
caption = "Fuente de datos: Eurostat y Encuesta Social Europea")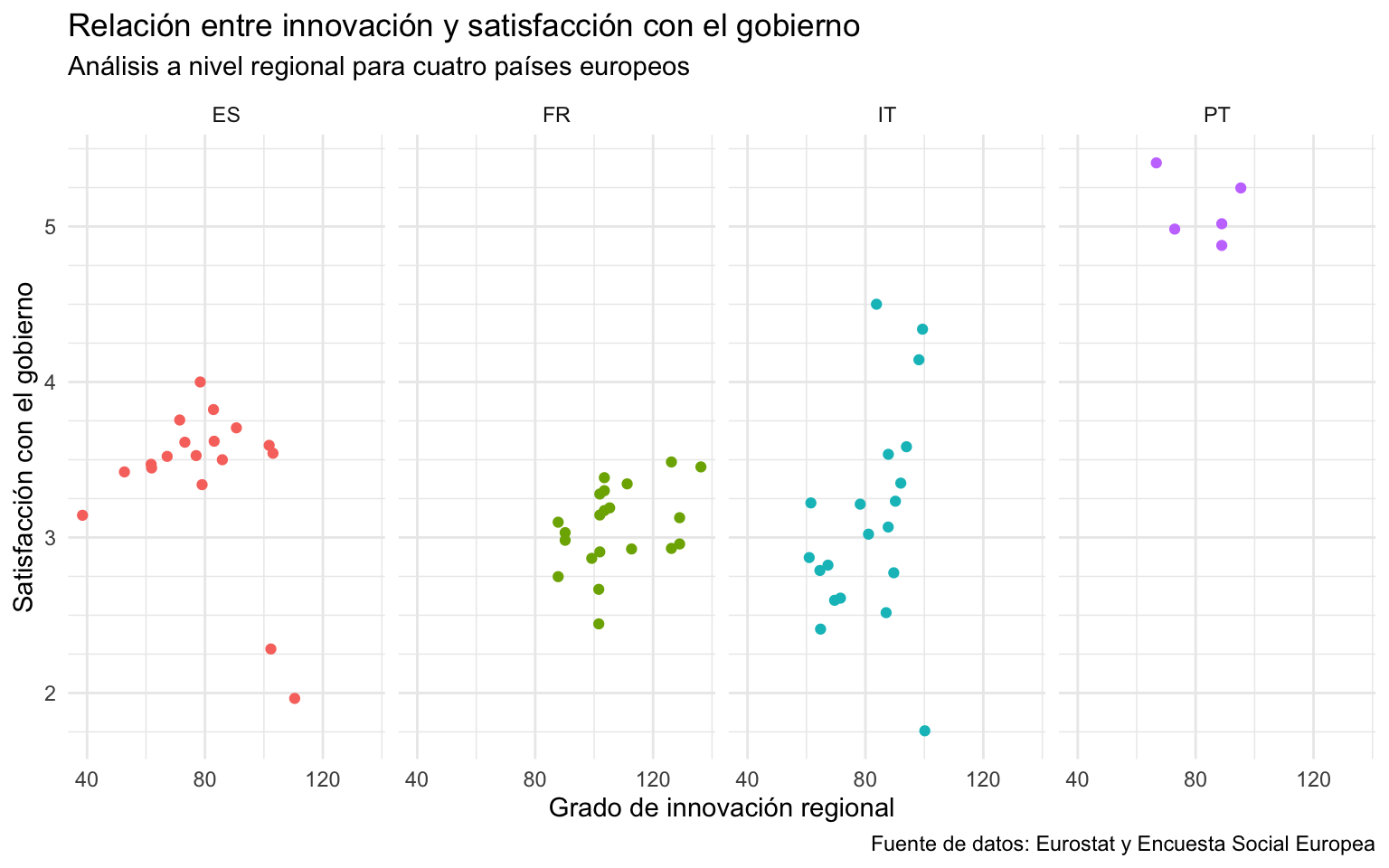
En el argumento vars() marcamos la variable categórica que separará las gráficas y seguidamente el número de columnas en ncol.
nuts |>
filter(ccode %in% c("ES", "FR", "IT", "PT")) |>
ggplot(mapping = aes(x = innov,y = stfgov, color = ccode)) +
geom_point(show.legend = FALSE) +
facet_wrap(facets = vars(ccode), ncol = 1) +
scale_x_continuous(breaks = seq(0, 160, by = 40)) +
scale_y_continuous(breaks = seq(0, 10, by = 1),
minor_breaks = seq(0, 10, by = .25))+
labs(x = "Grado de innovación regional",
y = "Satisfacción con el gobierno",
title = "Relación entre innovación y satisfacción con el gobierno",
subtitle = "Análisis a nivel regional para cuatro países europeos",
caption = "Fuente de datos: Eurostat y Encuesta Social Europea")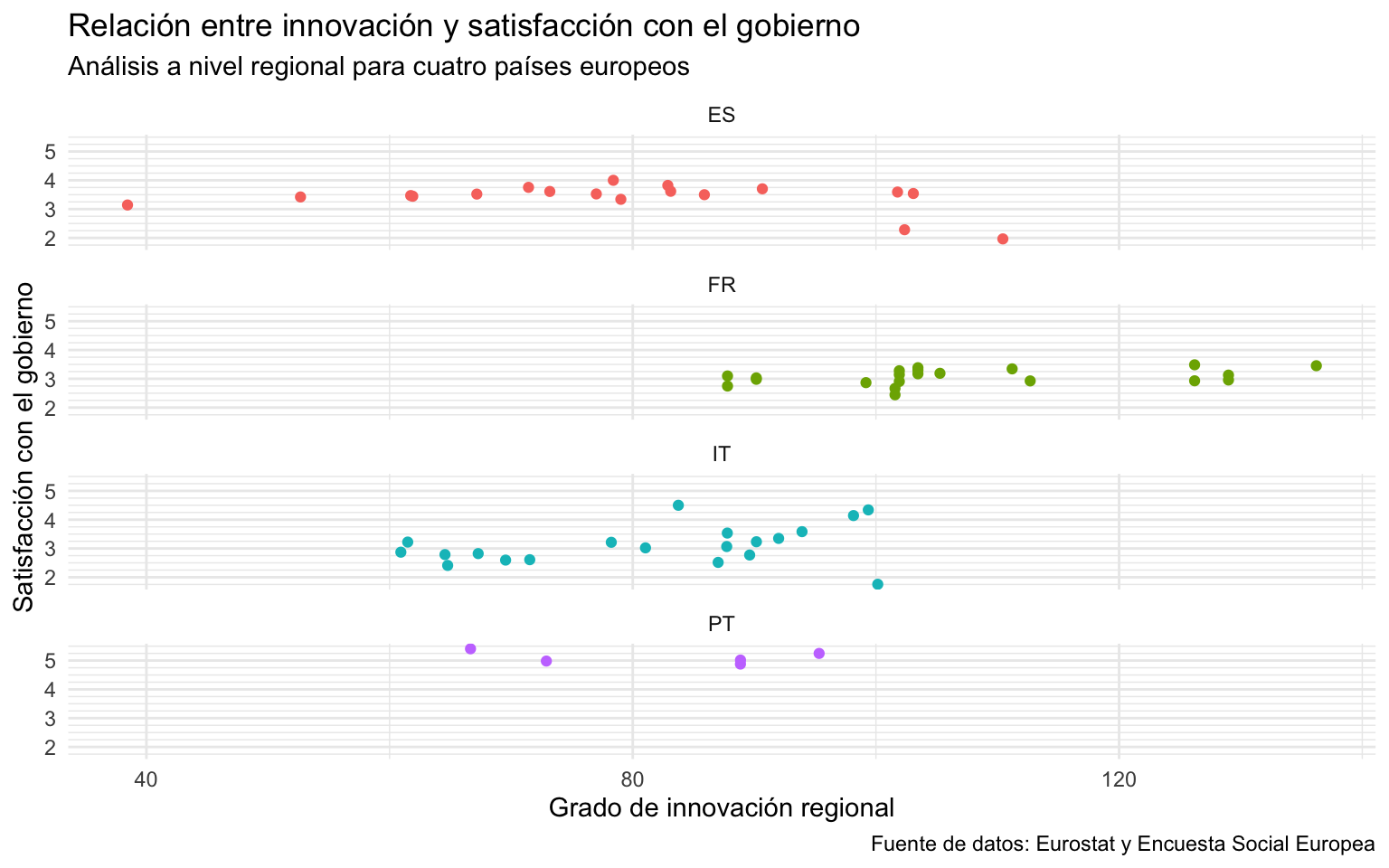
En el argumento vars() marcamos la variable categórica que separará las gráficas. Si no ponemos ningún otro argumento, la distribución se hará de forma automática y equilibrada entre filas y columnas.
nuts |>
filter(ccode %in% c("ES", "FR", "IT", "PT")) |>
ggplot(mapping = aes(x = innov,y = stfgov, color = ccode)) +
geom_point(show.legend = FALSE) +
facet_wrap(facets = vars(ccode)) +
scale_x_continuous(breaks = seq(0, 160, by = 40)) +
scale_y_continuous(breaks = seq(0, 10, by = 1),
minor_breaks = seq(0, 10, by = .25))+
labs(x = "Grado de innovación regional",
y = "Satisfacción con el gobierno",
title = "Relación entre innovación y satisfacción con el gobierno",
subtitle = "Análisis a nivel regional para cuatro países europeos",
caption = "Fuente de datos: Eurostat y Encuesta Social Europea")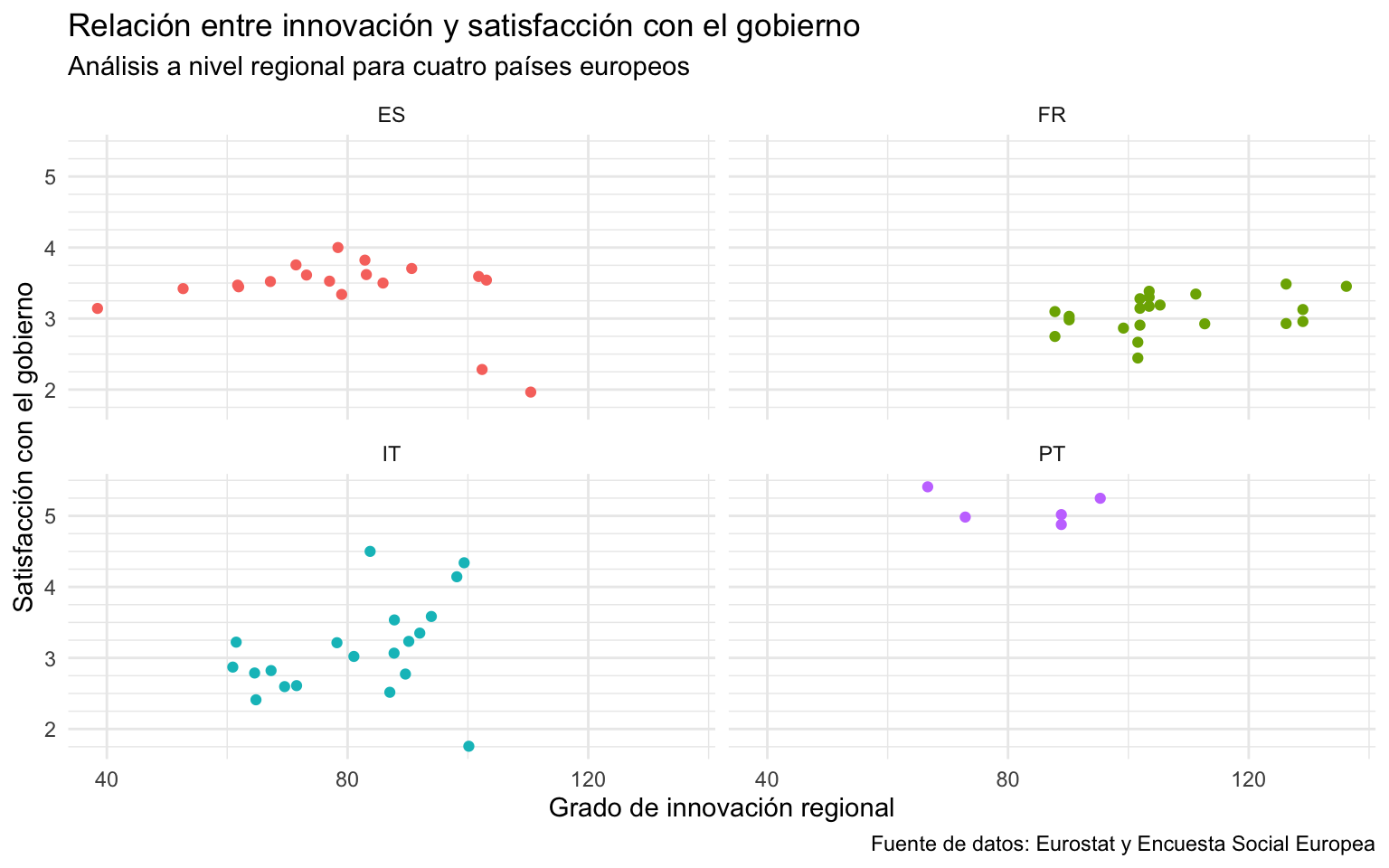
Si se usa facet_grid(), se pueden especificar dos variables. La que se indique en el argumento rows se situará en las filas y la que se indique en el argumento cols se situará en las columnas. La figura 12.20 muestra un ejemplo de una gráfica creada con facet_grid() en que el facet de las filas corresponde a la población —grande o pequeña— de la región NUTS y el de las columnas distingue, como antes, los diferentes países. Es posible que, al hacer estas divisiones, algún panel quede vacío o con pocos casos, como vemos en el caso de Portugal.
nuts |>
filter(ccode %in% c("ES", "FR", "IT", "PT")) |>
mutate(pop = if_else(pop > 2000000, "Large", "Small")) |>
ggplot(mapping = aes(x = innov, y = stfgov, color = ccode)) +
geom_point(show.legend = FALSE) +
facet_grid(pop ~ ccode) +
scale_x_continuous(breaks = seq(0, 160, by = 40)) +
scale_y_continuous(breaks = seq(0, 10, by = 1),
minor_breaks = seq(0, 10, by = .25))+
labs(x = "Grado de innovación regional",
y = "Satisfacción con el gobierno",
title = "Relación entre innovación y satisfacción con el gobierno",
subtitle = "Análisis a nivel regional para cuatro países europeos",
caption = "Fuente de datos: Eurostat y Encuesta Social Europea")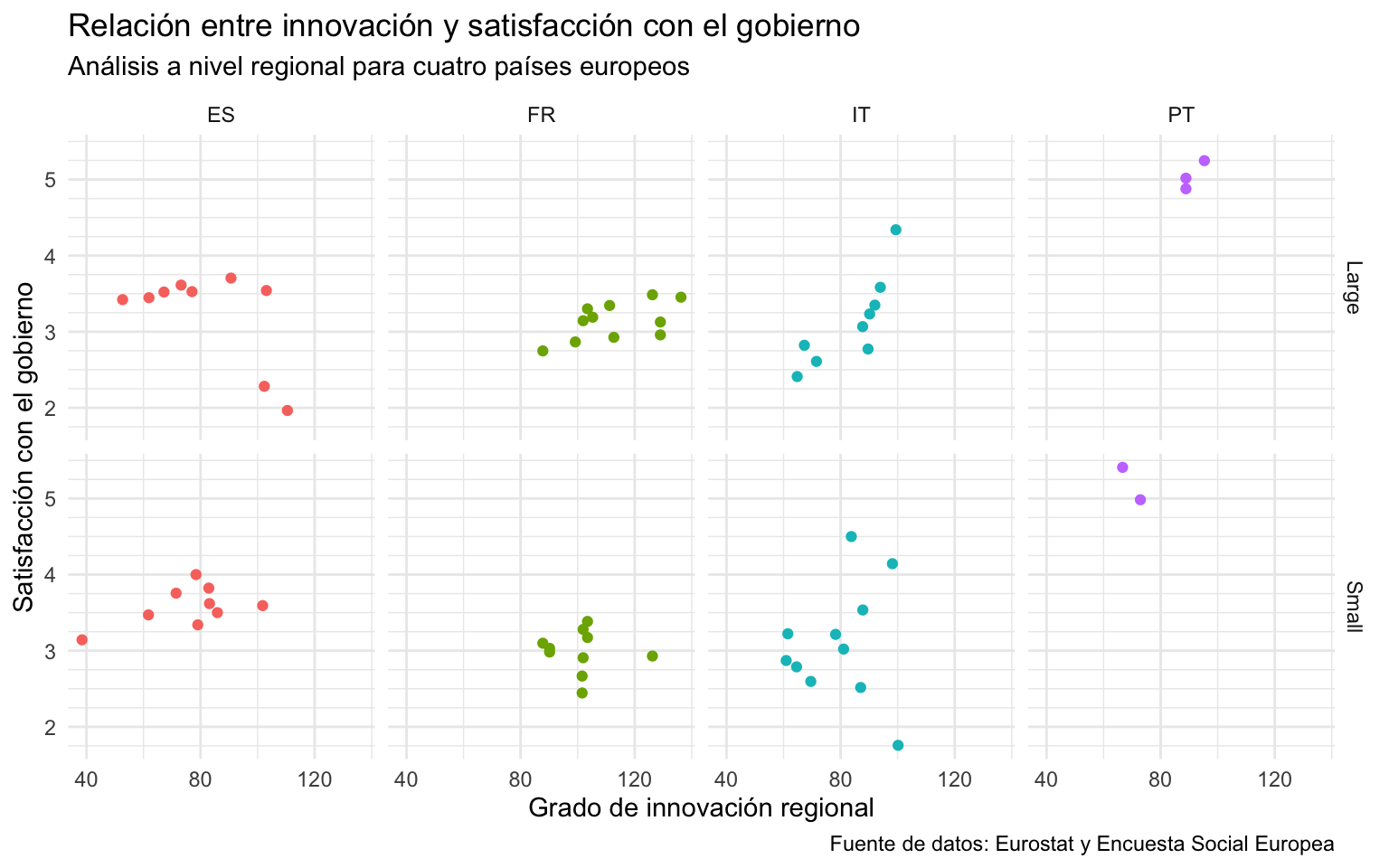
12.6 Temas
La última capa que se cubre en este capítulo es la de los temas. Cualquier elemento visual de la gráfica que no tiene que ver con los datos se introduce en esta capa. Desde la función theme() se puede cambiar el color de fondo de las gráficas, los tipos de letra, el aspecto de las marcas de las cuadrículas, la apariencia de las leyendas y un largo etcétera. Por ejemplo, ya se ha visto en el apartado Section 12.3 cómo modificar las marcas mayores y menores de una gráfica. Ahora bien, una opción estética puede ser no mostrar estos puntos de referencia (figura 12.21). Esto se puede hacer a partir de la función theme() indicando al argumento panel.grid = element_blank().
nuts |>
ggplot(mapping = aes(x = innov, y = stfgov)) +
geom_point() +
theme(panel.grid = element_blank())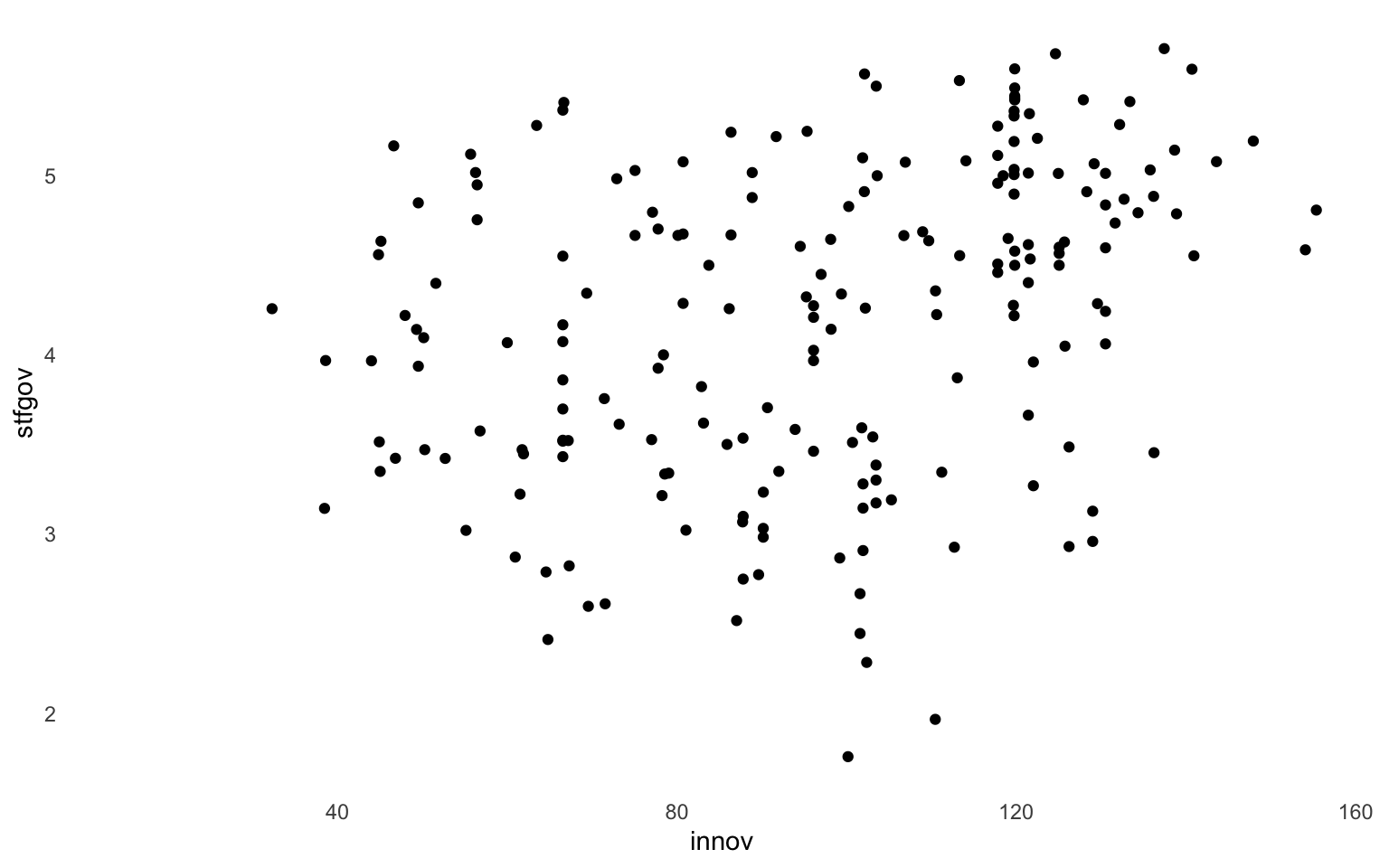
Es recomendable explorar la documentación de esta web para ver todas las posibilidades en la hora de personalizar el diseño de las gráficas con ggplot2.
La gran cantidad de argumentos que contiene la función theme() hace que sea oportuno dejar estas cuestiones para un nivel más avanzado de ggplot2. No obstante, podéis haceros una idea en esta web, donde también tenéis ejemplos prácticos en la parte final del documento.
Una opción más directa para intentar asegurar que todas las gráficas que se generan en un documento tienen una apariencia similar es utilizar temas predeterminados. ggplot2 incluye algunos como theme_bw() (figura 12.22), theme_minimal() (figura 12.23), theme_gray() (figura 12.24) o theme_void() (figura 12.25), cada uno con un diseño diferente. Si se usara el theme_bw() en la gráfica que se ha considerado que era final y que se ha guardado como un objeto, se obtendría la misma información en la gráfica pero con un diseño estético y una apariencia ligeramente diferente.
final + theme_bw()
final + theme_minimal()
final + theme_gray()
final + theme_void()
Una opción muy recomendable es predefinir un estilo estético de entrada: solo empezar a escribir el código en R. En este capítulo se ha hecho así y se ha predefinido desde el inicio que se aplicara el tema ‘minimal’. Usando la función theme_set(), se pueden indicar todas las características que tendrían que definir la estética de las gráficas. Una vez ejecutada, todas las gráficas a partir de aquel momento cumplirán con el tema que se haya definido sin necesidad de repetir, para cada gráfica, las consideraciones estéticas del tema. Al inicio de este capítulo se ha ejecutado la función theme_set(theme_minimal)) y esto ha hecho que, excepto cuando se ha indicado lo contrario, este tema fuera el definitorio de todas y cada una de las gráficas.
Más allá de los temas predefinidos suministrados por ggplot2, hay otra opción que es usar un paquete complementario llamado ggthemes. Este paquete dispone de un gran número de estilos predeterminados que se pueden usar como temas. Algunos de estos estilos son los que usan publicaciones como The Economist, software estadístico como Stata o simplemente diseños hechos por personalidades relevantes en el mundo de la visualización de datos como Edward Tufte. Los ejemplos siguientes (de la figura 12.26 a la figura 12.29) muestran cómo quedarían las diferentes gráficas si se aplican los diferentes temas.
final + theme_economist()
final + theme_stata()
final + theme_foundation()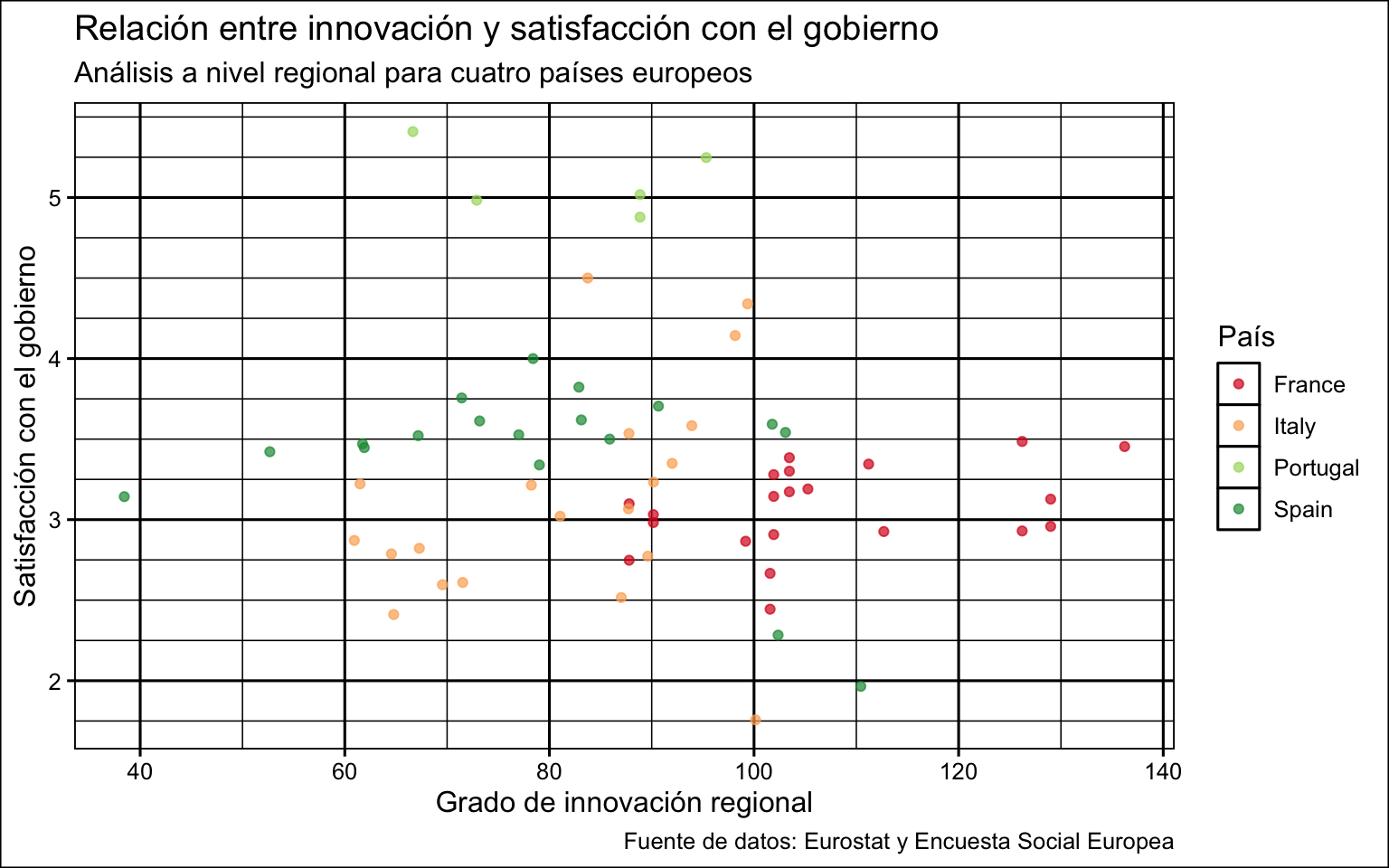
final + theme_tufte()
12.7 Para saber más
Llegados a este punto, los elementos básicos para generar gráficas con ggplot2 tendrían que haber quedado comprendidos. Como pasa siempre con R, las enormes potencialidades del paquete ggplot2 hacen que no se hayan podido cubrir todas las posibilidades de las que nos dota este paquete. La mejor opción para resolver las dudas que vayan surgiendo a la hora de trabajar en la visualización de datos es usar los **cheatsheets o consultar los foros de internet donde otros usuarios hayan planteado dudas similares. Lo más importante de este capítulo es que la lógica de capas a la hora de generar una gráfica haya quedado clara. Si esto es así, no debería haber muchas complicaciones para poder crear gráficas originales o replicar códigos para generar visualizaciones de datos.
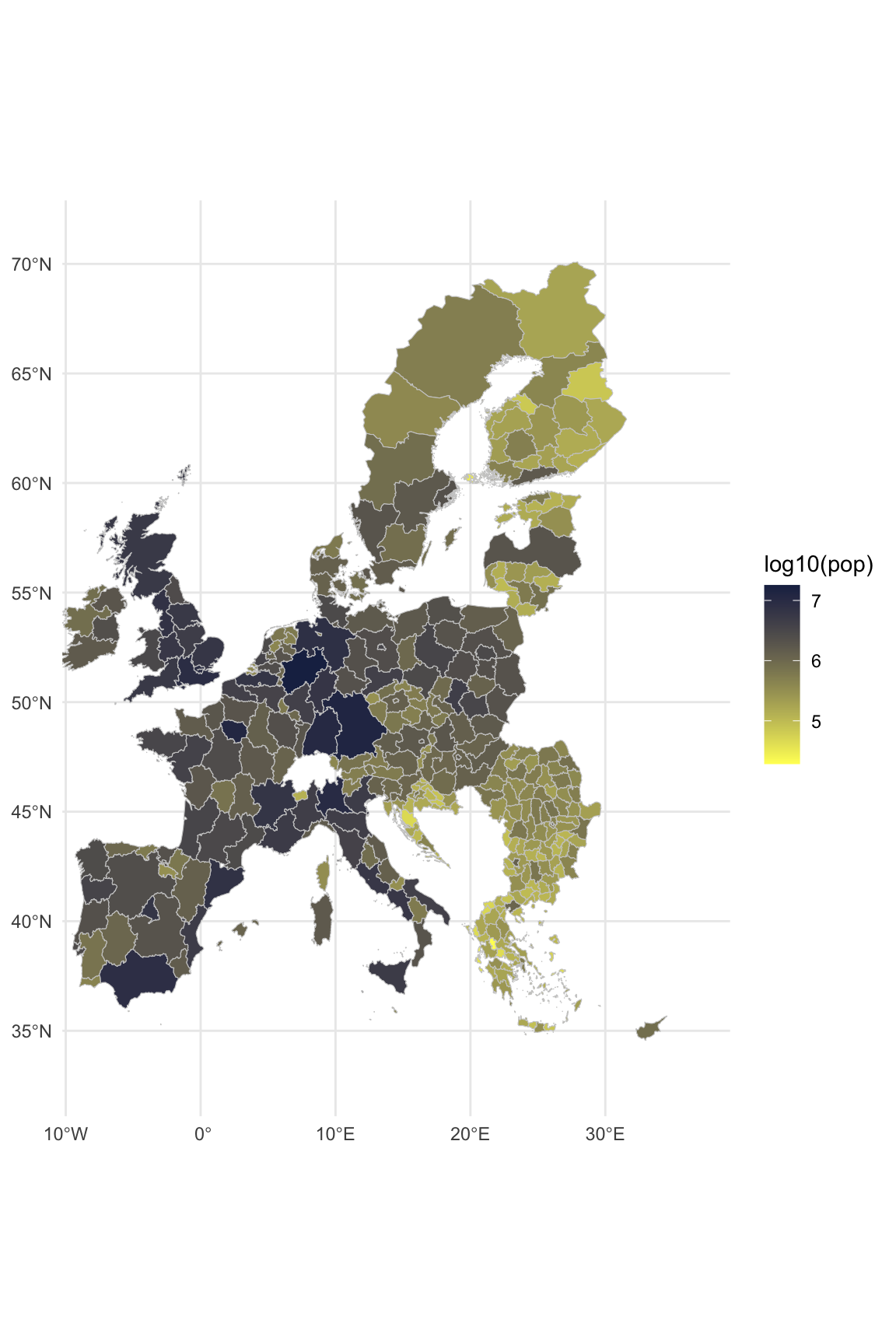
Ejercicio 12.4 (Mapear con ggplot2) El paquete ggplot2 también nos permite ver los datos representados en un mapa. En el archivo nuts_geo.shp tenemos la misma información contenida en el marco de datos NUTS, con el añadido de que también incluye información sobre el área de cada unidad de observación en forma poligonal. En primer lugar, cargad el objeto nuts_geo con la función read_sf() de la librería sf.
A continuación ya podemos visualizar cualquier variable de los datos. En la figura 12.30 siguiente visualizamos la variable pop en escala logarítmica. Hemos establecido los límites de la gráfica, para no visualizar los territorios que están muy alejados de Europa, como las Canarias o la Guayana francesa. Y finalmente hemos decidido qué gradación tomarán los colores de la gráfica con scale_fill_gradient() indicando el color que tomarán los valores máximo y mínimo de los datos.
Puedes probar de cambiar el código y visualizar otra variable y cambiar los colores.