14 Datos perdidos
14.1 Introducción
Una de las características que tienen los conjuntos de datos es que para cada combinación de una observación y una variable corresponde un valor concreto. Este principio, sin embargo, se rompe a menudo cuando algunos valores, por alguna razón, no existen o tienen una codificación que no es común a la de la escala de la variable en cuestión. A estos valores los llamaremos datos perdidos (missing data o también dichos valores perdidos), que aparecen normalmente codificados como NA (Not Available, no disponible), pero que como veremos a lo largo de este apartado pueden tomar la forma de casi cualquier tipo de valor. En la tabla 14.1 se muestra el ejemplo de un conjunto de datos con datos perdidos. Fijémonos en que la mayoría de valores de la columna fem_unempl, que muestra en diferentes países el porcentaje de mujeres con educación básica que en 2020 estaban en el paro, aparecen como NA.
Cojamos el caso de Andorra. Es evidente que en Andorra hay población femenina. También es evidente que algunas de estas mujeres tienen estudios primarios, y que algunas de ellas tendrían que estar en el paro. Por lo tanto, el porcentaje de mujeres en el paro con educación básica en Andorra es un dato que debería existir y oscilar entre 0 y 100. Sin embargo, por el motivo que sea, desconocemos el valor. Los datos perdidos son exactamente esto, valores que deberían estar pero no están.
| iso3c | country | fem_unempl | region | capital | income | lending |
|---|---|---|---|---|---|---|
| AFG | Afghanistan | 19.85 | South Asia | Kabul | Low income | IDA |
| ALB | Albania | NA | Europe & Central Asia | Tirane | Upper middle income | IBRD |
| DZA | Algeria | NA | Middle East & North Africa | Algiers | Lower middle income | IBRD |
| ASM | American Samoa | NA | East Asia & Pacific | Pago Pago | Upper middle income | Not classified |
| AND | Andorra | NA | Europe & Central Asia | Andorra la Vella | High income | Not classified |
| AGO | Angola | NA | Sub-Saharan Africa | Luanda | Lower middle income | IBRD |
| ATG | Antigua and Barbuda | NA | Latin America & Caribbean | Saint John’s | High income | IBRD |
| ARG | Argentina | 17.11 | Latin America & Caribbean | Buenos Aires | Upper middle income | IBRD |
| ARM | Armenia | 4.83 | Europe & Central Asia | Yerevan | Upper middle income | IBRD |
| ABW | Aruba | NA | Latin America & Caribbean | Oranjestad | High income | Not classified |
Hay muchos ejemplos de conjuntos de datos con datos perdidos. En las encuestas, a menudo los participantes no responden algunas preguntas, ya sea porque no recuerdan con precisión su comportamiento pasado o porque prefieren no compartir sus auténticas actitudes o creencias sobre asuntos delicados como la religión, la política o la salud sexual. En conjuntos de datos históricos, también hay datos que tendríamos que tener y no tenemos, posiblemente porque se han perdido en el tiempo y no se pueden recuperar. Además, a veces, es un reto obtener datos de ciertas comunidades o grupos de población, ya sea porque están perseguidos en sus países o porque residen en regiones remotas de difícil acceso.
Este módulo realiza una breve exploración del mundo de los datos perdidos y se concentra en dos objetivos principales. El primero de ellos es aprender a identificar los datos perdidos en un marco de datos, una tarea que no siempre resulta sencilla, puesto que un dato perdido puede adoptar múltiples formas. Se puede tener la suerte de que estos datos aparezcan etiquetados como NA, pero también pueden aparecer como valor numérico, o como string con alguna palabra como “N/A”, “missing” o simplemente con una casilla en blanco1. Y el segundo objetivo del módulo se orienta a dar herramientas para saber qué hacer con los datos perdidos. En gran parte, veremos que la manera en que se tratan estos datos dependerá del motivo por el que se han perdido, y adoptaremos diferentes estrategias en función de esta razón.
1 Los valores Inf (infinit) y Nan (Not a Number) también se pueden considerar como datos perdidos. En este módulo los trataremos dentro de la categoría de NA.
14.2 Identificar datos perdidos
Los datos perdidos son puñeteros porque pueden tomar la forma de cualquier valor. A menudo aparecerán etiquetadas como NA, pero también pueden adoptar la forma de un valor de carácter o incluso un valor numérico. R tiene muchas funciones que ayudan a detectarlas si están codificadas como NA. Pero el problema surge cuando están escondidos detrás de un valor numérico o de carácter, o cuando tenemos toda una fila desaparecida, como veremos en los próximos apartados.
14.2.1 NA
Detectar datos perdidos es relativamente sencillo cuando están codificadas como NA, puesto que R contabiliza estos valores como una categoría diferente de los valores numéricos o de carácter. Esto permite que muchas funciones puedan identificar estos valores NA con facilidad cuando las buscamos dentro de una variable categórica o numérica. Una de las más empleadas es summary(), que hace una exploración general de los principales estadísticos descriptivos de una variable. Esta función se puede aplicar tanto a una sola variable como un marco de datos entero. Cuando una variable tiene datos perdidos codificados como NA, en la descripción de la variable aparece una fila extra que indica el número de valores coincidentes. Si pedimos un sumario de la variable fem_unempl, vemos que tiene 128 datos perdidos contabilizados como NA.
NA
summary(missing$fem_unempl)
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.050 5.822 10.035 11.866 15.560 41.010 128Existen otras funciones que permiten hacer preguntas más específicas sobre los NA de una variable o un conjunto de datos. La función por excelencia es is.na(), que devuelve el mismo objeto con los valores perdidos marcados como TRUE y el resto de valores marcados como FALSE. Ya hemos visto anteriormente esta función aplicada en combinación con filter(), pero también se puede combinar con otras funciones para responder a preguntas sobre los NA.
¿Hay algún NA? Combinada con is.na(), la función any() permite preguntar, simplemente, si hay algún valor perdido en un objeto. R da TRUE si encuentra algún dato perdido y FALSE si no encuentra ninguno. A continuación preguntamos si hay algún dato perdido en el marco de datos missing y la respuesta es que sí. Esta combinación de funciones se puede aplicar tanto a marcos de datos como vectores.
En el paquete naniar, any_na() consigue el mismo resultado.
¿Cuántos NA hay? Combinada con is.na(), la función sum() cuenta la cantidad de datos perdidos en un objeto. R suma la cantidad de TRUE. A continuación hemos pedido que sume la cantidad total de NA del marco de datos missing. Esta combinación de funciones también se puede aplicar tanto a marcos de datos como vectores.
En el paquete naniar, n_miss() consigue el mismo resultado.
¿En qué número de fila se encuentran exactamente los NA? La combinación de is.na() y which() devuelve un vector numérico con la posición de las filas que tienen datos perdidos. Es preferible utilizar este procedimiento sobre un vector. En el paquete naniar, which_na() consigue el mismo resultado.
[1] 2 3 4 5 6 7 10 14 15 16 17 20 21 22 28 31 33 34
[19] 35 37 38 39 40 42 43 44 46 48 50 51 54 55 57 60 61 63
[37] 64 65 66 69 70 71 74 75 77 78 79 80 81 82 83 84 85 89
[55] 92 94 98 100 101 102 103 106 107 108 110 111 112 113 114 117 118 121
[73] 124 125 128 130 133 134 136 137 138 140 142 143 144 146 148 149 150 152
[91] 153 155 158 163 164 165 167 169 170 172 175 176 178 180 181 183 184 185
[109] 186 189 190 193 194 195 197 199 200 201 202 204 205 207 208 209 210 212
[127] 214 216Las funciones which pueden servir, por ejemplo, para seleccionar las filas que tienen NA con los corchetes. Combinando filter() y is.na() también se puede conseguir el mismo resultado.
missing[which_na(missing$fem_unempl),]# A tibble: 128 × 7
iso3c country fem_unempl region capital income lending
<chr> <chr> <dbl> <chr> <chr> <chr> <chr>
1 ALB Albania NA Europe & Central… Tirane Upper… IBRD
2 DZA Algeria NA Middle East & No… Algiers Lower… IBRD
3 ASM American Samoa NA East Asia & Paci… Pago P… Upper… Not cl…
4 AND Andorra NA Europe & Central… Andorr… High … Not cl…
5 AGO Angola NA Sub-Saharan Afri… Luanda Lower… IBRD
6 ATG Antigua and Barbuda NA Latin America & … Saint … High … IBRD
7 ABW Aruba NA Latin America & … Oranje… High … Not cl…
8 BHS Bahamas, The NA Latin America & … Nassau High … Not cl…
9 BHR Bahrain NA Middle East & No… Manama High … Not cl…
10 BGD Bangladesh NA South Asia Dhaka Lower… IDA
# ℹ 118 more rowsEl resultado de esta operación es parecido al que obtendríamos con filter(missing, is.na(fem_unempl)).
El paquete de R naniar (Tierney et al., 2023), destinado específicamente al tratamiento de datos perdidos, contiene muchas funciones para detectar NA. Una de las más interesantes es vis_miss(), que aplicada a un marco de datos crea una visualización que marca con negro los valores codificados como NA y con gris el resto de valores. Si aplicamos la función al marco de datos missing (figura 14.1 del lateral), se observa que tiene un 8.9 % de datos perdidos, cuya mayor parte pertenece a la variable fem_unempl. También se puede apreciar que una pequeña parte de NA está localizada en la variable capital, mientras que en las otras variables no hay datos perdidos codificados como NA.

vis_miss()A la hora de ejecutar la función vis_miss() se debe ir con cuidado, porque la generación del gráfico consume mucha memoria. Cuando se intenta visualizar un marco de datos de más de un millón de valores, R impide el proceso, y solo se puede visualizar si introducimos en la función el argumento warn_large_data = F.
14.2.2 Valores numéricos
No siempre ocurre así, pero los valores perdidos están codificados como NA. En las variables numéricas los datos perdidos pueden tomar la forma de un valor numérico cualquiera. Y en estos casos, detectarlos es bastante más complicado. La mejor estrategia acostumbra a ser asumir que estos valores perdidos tomarán forma de un valor extremo (también llamado outlier), es decir, un valor alejado de lo que consideramos normal en la distribución de los datos. Por ejemplo, si sabemos que la esperanza de vida mediana de un país acostumbra a oscilar entre 30 y 80 años, resultará muy extraño encontrarnos que en un país determinado la media es de 120. Muy probablemente, este será un dato perdido porque el valor no es el correcto y desconocemos el valor real.
De entre estos valores extremos que pueden ser considerados NA, distinguiremos de dos tipos: cuando estos valores extremos son voluntarios, consecuencia de una decisión deliberada en el proceso de codificación de los datos, o involuntarios, consecuencia de errores en el proceso de creación de los datos.
14.2.2.1 Codificaciones especiales
| country | year | polity |
|---|---|---|
| Bosnia | 2013 | -66 |
| Bosnia | 2014 | -66 |
| Bosnia | 2015 | -66 |
| Bosnia | 2016 | -66 |
| Bosnia | 2017 | -66 |
| Haiti | 2013 | -77 |
| Haiti | 2014 | -77 |
| Haiti | 2015 | -77 |
| Haiti | 2016 | -88 |
| Haiti | 2017 | 5 |
| Myanmar (Burma) | 2013 | -3 |
| Myanmar (Burma) | 2014 | -3 |
| Myanmar (Burma) | 2015 | -88 |
| Myanmar (Burma) | 2016 | 8 |
| Myanmar (Burma) | 2017 | 8 |
| Tunisia | 2013 | -88 |
| Tunisia | 2014 | 7 |
| Tunisia | 2015 | 7 |
| Tunisia | 2016 | 7 |
| Tunisia | 2017 | 7 |
En cuanto a los valores extremos voluntarios, estos acostumbran a ser codificaciones especiales que han utilizado los codificadores de la base de datos para señalar algún propósito concreto. Veamos, por ejemplo, la base de datos Polity V (Marshall & Gurr, 2020), que clasifica los regímenes políticos según su nivel de democracia, siendo 10 el nivel máximo y -10 el mínimo. En la tabla 14.2 del lateral observamos como el personal de Polity ha clasificado algunas observaciones (Bosnia, Haití, Myanmar y Túnez) entre los años 2013 y 2017. Fijémonos en que algunos valores de la variable polity no se corresponden con la escala que acabamos de describir. Bosnia tiene en todos los años el valor -66, mientras que Haití alterna entre -77 y -88 y solo en 2017 tiene un año que corresponde con la escala. Myanmar y Túnez son clasificados como -88 en un año.
Para poder interpretar correctamente estos valores será necesario siempre hojear el libro de códigos de la base de datos, donde esperamos encontrar el significado de estas codificaciones que se encuentran fuera de la escala de la variable. En el libro de códigos de Polity V se especifica que estos valores son codificaciones especiales que se otorgan a los regímenes en transición (código -88), en caso de interrupción del régimen (código -66) o en periodo de interregno (código -77).
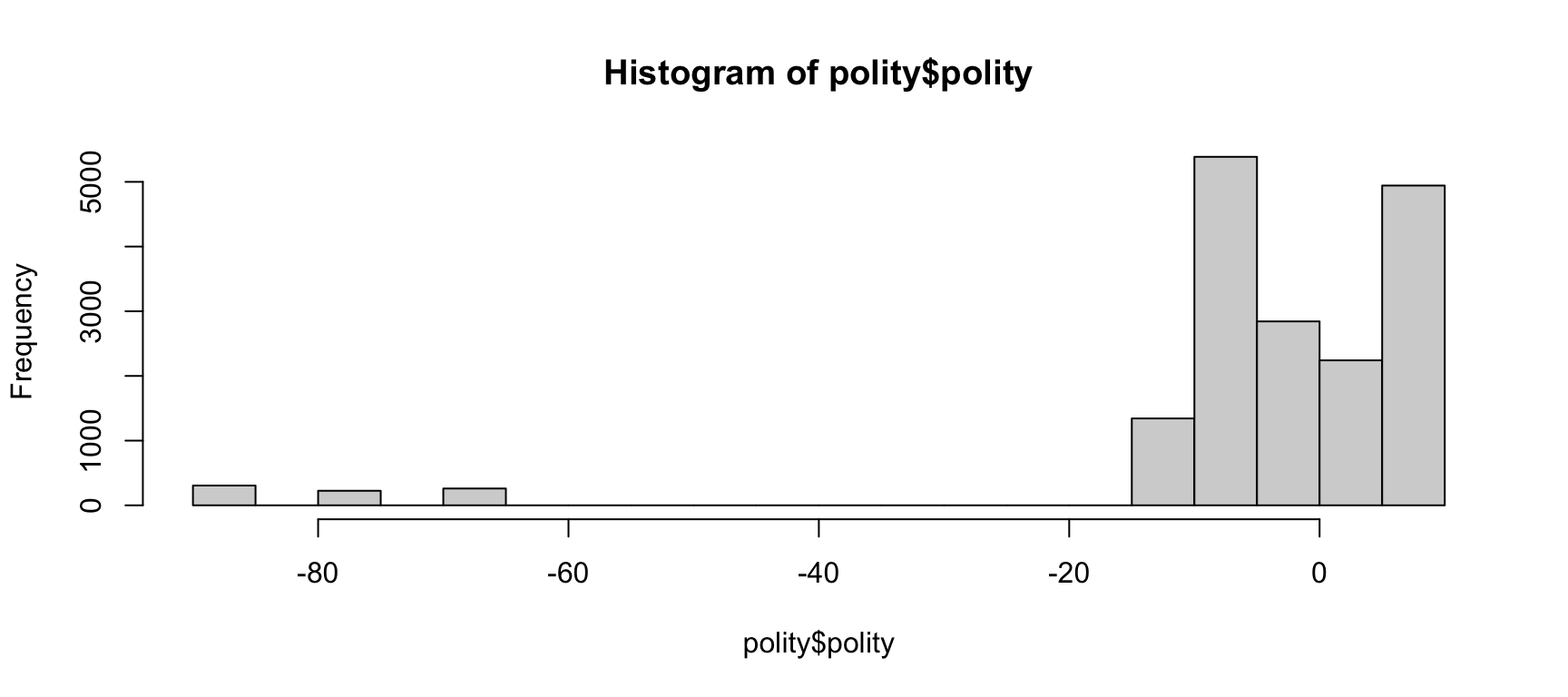
Se pueden considerar valores perdidos porque no forman parte del intervalo de los datos y porque no se pueden contabilizar a la hora de obtener, por ejemplo, estadísticos descriptivos como la media de la distribución. Por ejemplo, si consideramos los valores extremos de la variable polity, la media seria de -3.99 mientras que si no los consideramos la media es de -0.54. Como observamos en el histograma de la figura 14.2, los valores extremos son fácilmente identificables con esta visualización y se encuentran muy alejados de la mayoría de valores de la variable polity, que se ubican entre -10 y +10. Si no tenemos en cuenta esto, acumularemos sesgos importantes en algunas medidas cuantitativas, hecho por el que necesitaremos previamente tratar estos casos de alguna manera, como veremos más adelante en este módulo.
Hay otros muchos ejemplos en otras bases de datos de valores que se podrían considerar perdidos porque escapan de la escala habitual de la variable. Un ejemplo lo hemos visto anteriormente en la Intergovernmental Organizations dataset (v3) (tabla 1.3), donde los países están codificados 1 si pertenecen a una organización internacional, 0 si no pertenecen y -9 si se desconoce. En las encuestas de opinión, un caso muy típico de codificaciones especiales es para las preguntas en que la persona encuestada “No Sabe” o “No Contesta” a la respuesta. Cuando la escala es numérica, estos dos casos se suelen codificar con los valores 98 y 99.
Dentro del paquete naniar se encuentra el objeto common_na_numbers, que almacena algunos de los formatos más habituales que puede tomar un dato perdido dentro de un vector numérico.
naniar::common_na_numbers
## [1] -9 -99 -999 -9999 9999 66 77 88Esta no es una clasificación exhaustiva, puesto que no incluye, entre otros, las tres codificaciones especiales mencionadas antes de Polity. Sin embargo, nos puede dar una pista de donde se encuentran los valores que pueden estar asociados a datos perdidos.
14.2.2.2 Errores en les datos
Hay valores extremos que pueden responder a errores en los datos, producidos por errores humanos o de computación a la hora de codificar los datos. Como la causa del error es más bien aleatoria, en estos casos no existe ninguna solución mágica para encontrar estos valores extremos, aparte de explorar atentamente cada variable y pensar si tiene sentido que los datos tengan el valor que tienen. La lógica nos dirá, por ejemplo, que difícilmente un país tendrá un PIB per cápita negativo, y señales como este nos pueden hacer sospechar que existe algún error en los datos.
A veces, un sumario es suficiente para detectar algunos valores que se escapan de toda lógica. En la siguiente tabla 14.3 se utiliza la función summary() para pedir un resumen del marco de datos gapna. Este marco de datos es el mismo que el de gapminder, pero lo hemos alterado ligeramente para el propósito del siguiente ejercicio.
| country | continent | year | lifeExp | pop | gdpPercap | |
|---|---|---|---|---|---|---|
| Afghanistan: 12 | Africa :623 | Min. :1952 | Min. :-24.00 | Min. : 0 | Min. : 241 | |
| Albania : 12 | Americas:300 | 1st Qu.:1964 | 1st Qu.: 48.14 | 1st Qu.: 2785708 | 1st Qu.: 1204 | |
| Algeria : 12 | Asia :396 | Median :1982 | Median : 60.66 | Median : 7021078 | Median : 3537 | |
| Angola : 12 | Europe :360 | Mean :1980 | Mean : 59.42 | Mean : 29611080 | Mean : 66176 | |
| Argentina : 12 | Oceania : 24 | 3rd Qu.:1997 | 3rd Qu.: 70.84 | 3rd Qu.: 19593660 | 3rd Qu.: 9342 | |
| Australia : 12 | NA | Max. :2049 | Max. : 82.60 | Max. :1318683096 | Max. :100405504 |
Año máximo: 2049
Esperanza de vida mínima: -24
Población mínima: 0
PIB per cápita máximo: 100.405.504
Puede haber otros valores perdidos que sean todavía más complicados de encontrar, por eso es importante tener un conocimiento sustantivo de los datos y hacer un esfuerzo inicial para conocer a fondo qué miden las variables que queremos trabajar. Es capital tener muy claro qué unidad de medida tiene cada variable y entre qué valores acostumbran a oscilar sus valores. Podemos utilizar funciones como hist(), plot() o hacer operaciones lógicas con which() para comprobar si algunos valores salen de la norma.
14.2.3 Valores de carácter
En las variables categóricas, los datos perdidos pueden venir camufladas en una gran variedad de maneras dentro de valores de carácter. Lo más habitual será que dentro de la variable aparezcan nombres como “NA” o “N/A”, entre comillas, que técnicamente R no los toma como NA sino como valores de carácter. En el lateral vemos una ilustración práctica y más abajo, en la cajita Las codificaciones más comunes se pueden ver las formas más habituales que puede tomar un dato perdido codificado como valor de carácter.
En el paquete naniar se encuentra el objeto common_na_strings, que almacena algunos de los formatos más habituales que puede tomar un dato perdido dentro de un vector de carácter o un factor.
naniar::common_na_strings
## [1] "missing" "NA" "N A" "N/A" "#N/A" "NA " " NA"
## [8] "N /A" "N / A" " N / A" "N / A " "na" "n a" "n/a"
## [15] "na " " na" "n /a" "n / a" " a / a" "n / a " "NULL"
## [22] "null" "" "\\?" "\\*" "\\."De nuevo, esta no es una clasificación exhaustiva, puesto que muchos valores que podemos considerar que son datos perdidos en nuestro estudio pueden estar codificadas con nombres como “Not aplicable”, “Others”, etc.
Es importante recalcar que, en algunos casos, el hecho de que unos datos estén o no perdidos dependerá de nuestra consideración. Normalmente, si una variable categórica tiene valores como “Desconocido”, “No disponible”, “No aplicable”, “No registra”, etc. será señal de que la podemos considerar como perdida. También se puede aplicar el mismo razonamiento en valores en blanco (es un valor de carácter pero dentro está vacío), codificaciones especiales como “-999”, en respuestas como “No Sabe” o “No Contesta” en las encuestas, o en las categorías “Otras” para agrupar opciones menos comunes o poco frecuentes. Deberemos pensar qué información nos aportan, si es relevante o no para nuestro análisis, y en caso negativo recodificarla como NA.
Por ejemplo, si nos fijamos en los datos de la tabla 14.1 y buscamos información complementaria, descubriremos que el Banco Mundial clasifica a los países en tres grandes grupos según el tipo de préstamo a que se pueden acoger: “IDA”, “IBRD” y “Blend”. En la columna lending, sin embargo, vemos que existe el cuarto grupo “Not Classified”. Si nuestro propósito es solo analizar los países que caen en las tres categorías de interés, es muy posible que no nos interese tener categorizado este grupo, por lo que prefiramos codificarlo como NA o directamente eliminar toda la fila.
A veces los datos perdidos pueden estar incluso más escondidos y la única forma de detectarlos es una lectura atenta de los datos. Fíjate en la tabla 14.4, donde se muestra la ubicación ideológica en el eje izquierda derecha (variable V4_Scale) de los partidos políticos de España según la versión 2.1 Global Party Survey (GPS) (Norris, 2020). Si tenemos un conocimiento en profundidad de la política española, llamará la atención que EHB (Euskal Herria Bildu) tenga un 5.4 en el eje izquierda-derecha. Esto indicaría que es un partido que se sitúa más a la derecha que a la izquierda, cuando sabemos del cierto que esto no es así. El motivo de esta codificación es porque la GPS se equivocó y etiquetó EH Bildu cuando realmente los datos corresponden al Partido Nacionalista Vasco.
| ID_GPS | ISO | Partyabb | Partyname | V4_Scale |
|---|---|---|---|---|
| 280 | ESP | EHB | Basque Country Unite | 5.395833 |
| 281 | ESP | Cs | Citizens | 7.724638 |
| 282 | ESP | PP | People’s Party | 7.783784 |
| 283 | ESP | ERC | Republican Left of Catalonia | 2.986111 |
| 284 | ESP | PSOE | Spanish Socialist Workers’ Party | 4.000000 |
| 285 | ESP | JxCat | Together for Catalonia | 6.846154 |
| 286 | ESP | UP | Unidas Podemos | 1.862069 |
| 287 | ESP | VOX | Vox | 8.972973 |
Para detectar anomalías y errores en los datos no hay ningún otro secreto que examinar con atención las categorías de cada variable con funciones como unique() o distinct(). También puede resultar útil la función miss_scan_count(), que sirve para buscar caracteres concretos en un marco de datos. En el margen de la derecha, se utiliza la función para preguntar si hay algún valor en el marco de datos missing que se llame “Other”.
miss_scan_count(missing,
search = "Other")
## # A tibble: 7 × 2
## Variable n
## <chr> <int>
## 1 iso3c 0
## 2 country 0
## 3 fem_unempl 0
## 4 region 0
## 5 capital 0
## 6 income 0
## 7 lending 014.2.4 Observaciones perdidas
| country | year | democracy | duration |
|---|---|---|---|
| France | 1980 | 10 | 133 |
| France | 1981 | 10 | 134 |
| France | 1983 | 10 | 136 |
| France | 1984 | 10 | 137 |
Finalmente, las observaciones perdidas son un tipo de NA que se produce cuando toda una observación debería estar pero no está: hay una fila entera que debería estar pero la observación no existe. Lo comprenderemos rápidamente con la tabla 14.5. Tenemos datos de Francia en 1980, 1981, 1983 y 1984, pero la observación de 1982 no existe. En casos como este, la mejor manera para detectar las observaciones perdidas es con los datos ordenados por su unidad de observación. Así es fácil fijarse en que la observación del año 1982 no existe por el caso concreto de Francia, pero sí que está para todos los otros países.
También es muy común que haya observaciones perdidas con datos de acontecimientos puntuales, como los conflictos o las migraciones. Las bases de datos sobre estos fenómenos acostumbran a registrar las observaciones en que el acontecimiento se ha producido, pero no las observaciones en que no se ha producido. En Correlates of War, por ejemplo, ofrece una observación por cada año en que los Estados Unidos y el Reino Unido han estado en guerra, pero no ofrece observaciones de los años en que no lo han estado. De manera similar, los municipios tienden a reportar datos de los meses en que han tenido flujos migratorios, pero no cuando no han tenido. Para estudiar la variabilidad de los fenómenos, es muy importante tener presente que cuando el fenómeno no se ha producido (valor 0) también interesa.
14.3 Qué hacer con los datos perdidos
Existen dos acciones principales que se pueden tomar con los datos perdidos: eliminar los datos o sustituirlas por datos nuevos. En la mayoría de los casos, la elección de una opción o la otra vendrá determinada por el objetivo de investigación que tengamos. Por ejemplo, los institutos de opinión pública que realicen proyecciones de voto no tendrán ningún interés en eliminar los valores “No Sabe” y “No Contesta”, puesto que saben que los votantes de determinados partidos son más propensos a no responder qué votaron en las últimas elecciones. Por lo tanto, esta información puede ser muy valiosa para hacer cálculos y estimaciones de voto. En cambio, los mismos valores no serán relevantes en otros estudios, como los que examinen la orientación ideológica de determinados votantes según su recuerdo de voto. Todo dependerá, pues, de las preguntas que queramos contestar con los datos.
Una cuestión esencial en la gestión de los datos perdidos es averiguar el motivo por el que estos datos no están. En ciencias sociales, la explicación casi siempre está asociada con alguna característica de la unidad de observación, y esto es problemático para nuestro trabajo como analistas. Como hemos visto, el motivo por el que los encuestados no revelan su voto suele estar asociado a que han votado partidos que no son populares o que han generado controversia en la opinión pública. Esto comportará que respondan “No Sabe” o incluso se abstendrán, cuando en realidad no quieren revelar el voto. En ámbitos como la violencia doméstica o la drogadicción, la no respuesta puede estar relacionada con temores a represalias, estigma social o cuestiones de privacidad. Esta falta de respuesta puede complicar el análisis y crear sesgos en la comprensión de los problemas relacionados con estas cuestiones, de forma que las estrategias de gestión de los NA deben tener en cuenta estas circunstancias.
Por lo tanto, a la hora de gestionar los datos perdidos, distinguiremos dos grandes tipos: los que están perdidos pero no van relacionados con ninguna característica de la unidad de observación (motivo aleatorio); y los que están perdidos y tienen relación con alguna característica de la unidad de observación (motivo no aleatorio) (OECD, 2008).
14.3.1 Motivo aleatorio
Los datos pueden estar perdidos por un motivo aleatorio debido a errores a la hora de codificar la información, aunque este no acostumbra a ser el caso de los datos en ciencias sociales. En el ejemplo de los partidos políticos de España de la tabla 14.4, podríamos considerar que la confusión de EH Bildu por el PNB es totalmente aleatoria, que solo pasa muy de tanto en tanto cuando los codificadores llevan muchas horas delante de la pantalla2. A este tipo de datos perdidos se los denomina MCAR (siglas de Missing Completely at Random): se llaman así porque el hecho de que estén perdidos no está asociado con ninguna variable observada o no observada.
2 No obstante, también podríamos pensar que el motivo no es aleatorio y que el error tiene que ver con el hecho de que son partidos menos conocidos, y por lo tanto sí que estaría relacionado con la unidad de observación (en este caso, que sea un partido regional o que tenga pocos votantes en el ámbito estatal).
Cuando es este el caso, se puede elegir entre dos opciones. La primera opción es sustituir los datos perdidos por su valor, si lo podemos conocer, como es el caso de cambiar PNB por EH Bildu con case_match() o alguna otra función similar. La segunda opción es eliminar directamente la observación (o mantenerla como NA), que sí que haremos si no se puede encontrar la información por la que debemos sustituir los datos erróneos o encontrarla es demasiado costoso. Eliminar los datos no será problemático, porque el motivo de su ausencia es aleatorio y no hay peligro de que su eliminación cree sesgos en el análisis de los datos. El único problema será que eliminando observaciones se reduce el número de casos que se tienen a disposición.
A continuación se muestran algunas opciones que se podrían utilizar cuando los datos perdidos son aleatorios o simplemente no los usaremos:
La categoría “Not classified” del vector missing$lending no nos interesa, porque solo queremos estudiar los países que están acogidos en algún programa de préstamo del Banco Mundial. Eliminaremos los datos con un filter(!is.na()) o bien convertiremos todos estos valores en NA.
missing$lending[missing$lending == "Not classified"] <- NAHemos detectado un caso en el marco de datos gapna donde la esperanza de vida es inferior a cero. Deducimos que es un error de los datos. Buscamos cuál es la información correcta y la sustituimos. Alternativamente, también se podría convertir el valor en NA.
gapna[gapna$lifeExp < 0,]
## # A tibble: 1 × 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <dbl> <dbl> <dbl> <dbl>
## 1 Canada Americas 1962 -24 18985849 13462.
gapna$lifeExp[gapna$lifeExp < 0] <- 71.6
gapna |>
filter(country == "Canada", year == 1962)
## # A tibble: 1 × 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <dbl> <dbl> <dbl> <dbl>
## 1 Canada Americas 1962 71.6 18985849 13462.14.3.2 Motivo no aleatorio
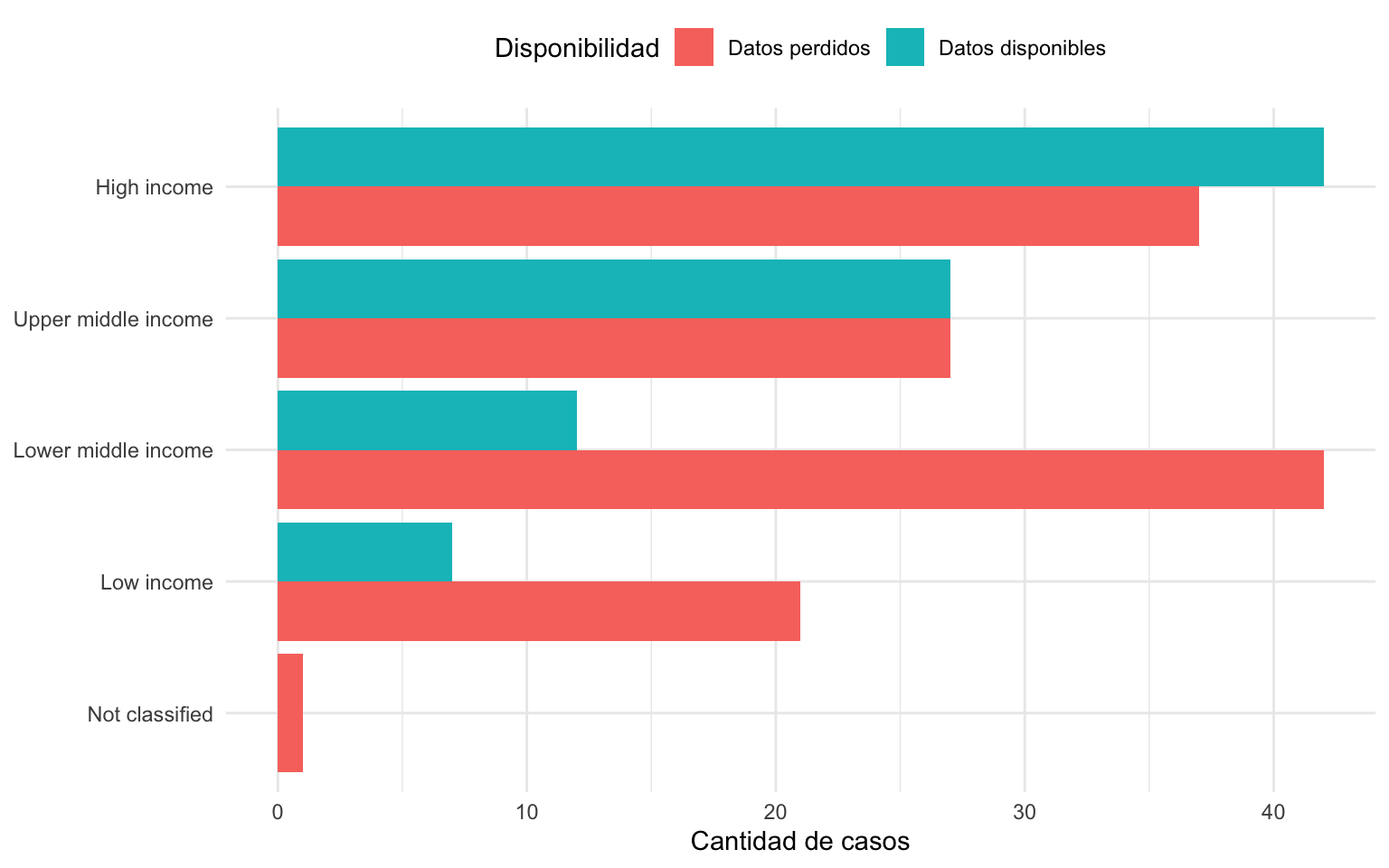
Lo más común es que los datos perdidos estén asociados con alguna característica de las unidades observadas. A este tipo de datos perdidos se los conoce como MAR (siglas de Missing At Random). Podemos ilustrar este concepto con un ejemplo concreto que se encuentra en el marco de datos missing (tabla 14.1), concretamente en la variable fem_unempl. La presencia de elementos NA en esta variable en algunos países no es casual. Para entenderlo, observamos la figura 14.3, que ofrece un resumen gráfico de los países que registran datos sobre el porcentaje de mujeres con educación básica que estaban paradas en 2020, clasificados según su nivel de renta. En países de alto nivel de renta (High income), es más probable que los datos estén disponibles que no que se encuentren como ausentes. Sin embargo, a medida que disminuimos el nivel de renta, aumenta la probabilidad de que haya datos perdidos. Esto evidencia una relación clara entre el PIB per cápita de un país y la disponibilidad de determinadas datos.
La falta de registro de algunos datos también puede tener intencionalidad política. De esto se dieron cuenta Barbieri et al. (2009) cuando recopilaban datos de los flujos comerciales entre los estados para la base de datos International Trade, 1870-2014 (v4.0) del proyecto Correlates of War. Los autores observaron que algunos estados reportaban ausencia de comercio con otros estados, cuando en realidad no era así. Utilizando otras fuentes, comprobaron que sí había actividad comercial, pero que esta información no se mostraba porque las relaciones diplomáticas con el estado concreto eran conflictivas. La ausencia de datos, pues, obedecía a motivos políticos.
El motivo de esta relación es que la disponibilidad de los datos está fuertemente ligada a la capacidad que tiene la institución para recogerlos (Bates, 2008)3. Es habitual que estados pequeños —como Andorra— o con un nivel bajo de desarrollo —como Uganda— no tengan la infraestructura necesaria para poder recoger datos como la tasa de homicidios, el número de personas sin hogar o la tasa de robos. En cambio, en países donde las oficinas nacionales de estadística tienen capacidad organizativa y tecnológica de llegar a todo el territorio, la disponibilidad y también la calidad de los datos serán más elevadas.
3 Hay que tener en cuenta que la mayoría de los datos publicados por el Banco Mundial no están recopilados por esta organización, sino que son los estados los encargados de proporcionarlos.
Como en este caso, cuando la explicación de por qué los datos están perdidos depende de otra variable que podemos observar, la mejor opción es sustituir los datos perdidos por otros4. En algunos casos, deberemos considerar cuánta fiabilidad se sacrifica con este cambio a expensas de la validez que ganamos en los resultados. El manual Handbook on Constructing Composite Indicators editado por la Organización por la Cooperación y el Desarrollo en Europa (OECD, 2008: 55–63) ofrece varios métodos para resolver estas situaciones. A continuación vemos algunos casos donde se ejemplifica esta disyuntiva:
4 Eliminar los datos perdidos no es recomendable porque es muy probable que una característica importante de los casos quede infrarrepresentada. Justamente, una explicación de por qué las mujeres están más en el paro es el nivel de desarrollo de los países. Pero si no tenemos datos de los países menos desarrollados, raramente podremos llegar a esa conclusión.
No disponemos de datos del PIB de Tonga del año 2009, pero sí tenemos de los años 2008 y 2010. Una opción razonable es asignar el valor del año anterior o del año posterior, que se puede hacer fácilmente con la función de tidyr fill(). La otra opción es hacer la media del valor de estos dos años.
El Banco Mundial no ofrece datos del PIB de Tuvalu pero hemos encontrado los mismos datos en un web del Ministerio de Economía de Tuvalu. En este caso, nos encontramos con un problema de fiabilidad, puesto que no podemos estar seguros de que los datos se hayan recogido siguiendo la misma metodología. Pero el riesgo no es muy alto, y por eso decidimos sustituirlos para evitar tener este dato como perdido.
La base de datos de democracia Polity no ofrece datos de Andorra ni de la mayoría de microestados. En cambio, hemos encontrado los datos en el web de Freedom House (FH). El problema es que la escala de los indicadores no coincide (los valores de Polity se mueven entre -10 y +10 y los de FH de 0 a 100). Una opción es imputar los datos, o bien haciendo una estimación manual de cuál sería el valor en Polity teniendo en cuenta los datos de FH, o bien utilizando métodos de imputación estadística como el de la función impute_lm(), del paquete de R _*simputation_ (van der Loo, 2022).
Cuando tenemos datos perdidos, el problema más grave que puede pasar es que la razón por la que los datos están perdidos está sistemáticamente relacionada con datos no observados, hecho que se conoce como MNAR (siglas de Missing not at random). Un ejemplo sería cuando en las encuestas se pregunta por el nivel de ingresos. Algunas personas podrían optar por no revelar su verdadero nivel de ingresos a causa de la estigmatización social asociada a ganar menos dinero o por cuestiones de privacidad. En este caso, los datos que faltan no son aleatorios porque la probabilidad que alguien no revele su ingreso está relacionada con la variable misma que se intenta medir (el ingreso). Tanto la eliminación de los datos como la imputación de datos crearán sesgo, por lo que la inferencia que se puede hacer será siempre limitada.
14.3.3 Algunas observaciones no están
Cuando algunas observaciones del conjunto de datos no están, pero deberían estar, la decisión dependerá de la facilidad de obtener estos datos. Un ejemplo habitual es con datos de flujo, como el comercio o las migraciones. Cuando se piden los datos de migraciones, los municipios no acostumbran a proporcionar las observaciones cuando el flujo migratorio es cero. Fijémonos en el código siguiente, donde hemos creado el marco de datos mun con las bajas en el padrón municipal del municipio de Altafulla en 1980. Tenemos datos de abril, marzo, julio y agosto, pero no tenemos los de mayo. El motivo es que no hubo ninguna baja durante el mes de mayo, pero analíticamente nos interesa observar toda la variación, y por eso también querremos saber cuando la cifra es cero. Cuando este sea el caso, utilizaremos la función complete(), donde indicaremos la unidad de observación y, si se da el caso, el intervalo de datos de la variable o variables que haya que completar.
mun <- tribble(~municipio, ~año, ~mes, ~baja,
"Altafulla", "1980", 4, 4,
"Altafulla", "1980", 5, 3,
"Altafulla", "1980", 7, 1,
"Altafulla", "1980", 8, 8)
mun |>
complete(municipio, año,
mes = first(mes):last(mes),
fill = list(baja = 0))
## # A tibble: 5 × 4
## municipio año mes baja
## <chr> <chr> <dbl> <dbl>
## 1 Altafulla 1980 4 4
## 2 Altafulla 1980 5 3
## 3 Altafulla 1980 6 0
## 4 Altafulla 1980 7 1
## 5 Altafulla 1980 8 8gapna |>
complete(country = "Eritrea",
continent = "Africa",
year = 1992,
lifeExp = 50.0,
pop = 3668440,
gdpPercap = 583)