7 Variables categóricas
7.1 Introducción
Como hemos visto en el ejercicio del apartado anterior, si no hacemos ningún tratamiento, una variable categórica nos aparecerá en la consola de R como una secuencia desordenada de diferentes categorías, que se van repitiendo de vez en cuando. Precisamente, las dos técnicas cuantitativas principales que tenemos para sintetizar la información de este tipo de variable son o bien contar la cantidad de veces que se repite cada una de estas categorías (es decir, la frecuencia en la que aparecen), o bien contar la cantidad de veces que se repite cada categoría en comparación con las otras categorías de la variable. Estas serán las dos técnicas principales que aprenderemos en este apartado.
El instrumento que utilizaremos para representar estos cálculos es la tabla de frecuencias. En la tabla 7.1 encontramos un ejemplo de su contenido. La tabla muestra la cantidad de veces, en términos absolutos y en términos relativos, que se repiten los valores de la variable happy del marco de datos wvs. Esta variable pregunta a los encuestados si creen que son felices con la vida. Las respuestas posibles son “Muy feliz”, “Bastante feliz”, “No muy feliz” o “Nada feliz”.
| happy | Freq. Absolutas | Freq. Ac. Absolutas | Freq. Relativas | Freq. Ac. Relativas |
|---|---|---|---|---|
| Not at all happy | 12511 | 12511 | 2.8 | 2.8 |
| Not very happy | 67252 | 79763 | 15.2 | 18.0 |
| Quite happy | 234545 | 314308 | 53.1 | 71.1 |
| Very happy | 127750 | 442058 | 28.9 | 100.0 |
Como vemos, la tabla de frecuencias nos permite sintetizar la información de una variable categórica. La columna de frecuencias absolutas simplemente nos recuenta el número de casos de cada categoría, mientras que la columna de frecuencias relativas nos dice qué porcentaje representa esta cantidad sobre el total de casos. En el caso de las variables ordinales, también nos puede interesar conocer las frecuencias acumuladas, que es la suma de las frecuencias de todas las categorías hasta una categoría particular de la tabla.
7.2 Frecuencia absoluta
Pedir las frecuencias absolutas es algo relativamente sencillo con código de R, y tenemos una gran variedad de funciones que nos lo permiten hacer. Sin embargo, nos centraremos en dos funciones. La primera es count(), que, al ser una función de dplyr, tiene dos características que la hacen muy útil: devuelve como resultado un marco de datos y se puede utilizar en el sistema pipe. El argumento sort = T nos permite ordenar las categorías de más a menos frecuencia.
gapminder |>
count(continent, sort = T)
## # A tibble: 5 × 2
## continent n
## <fct> <int>
## 1 Africa 624
## 2 Asia 396
## 3 Europe 360
## 4 Americas 300
## 5 Oceania 24La otra función con la que podemos crear una tabla de frecuencias es table(). A diferencia de count(), esta función no se puede usar en el sistema pipe ni tampoco devuelve un marco de datos, sino un objeto de tipo table. Es por eso que tendremos que utilizar el formato dólar para enlazar el marco de datos con el vector que queremos observar (table(df$v)).
En los primeros módulos hemos dicho que estudiaríamos principalmente dos objetos, los vectores y los marcos de datos, pero que en realidad hay otros muchos tipos de objetos.
d <- table(gapminder$continent)
is(d)
## [1] "table" "oldClass"table(gapminder$continent)
##
## Africa Americas Asia Europe Oceania
## 624 300 396 360 24Además de cuantificar una variable numérica, a menudo también querremos visualizar la distribución de las frecuencias en un gráfico. Una opción rápida es barplot(), una función que nos creará un diagrama de barras si lo añadimos al objeto creado anteriormente con table().
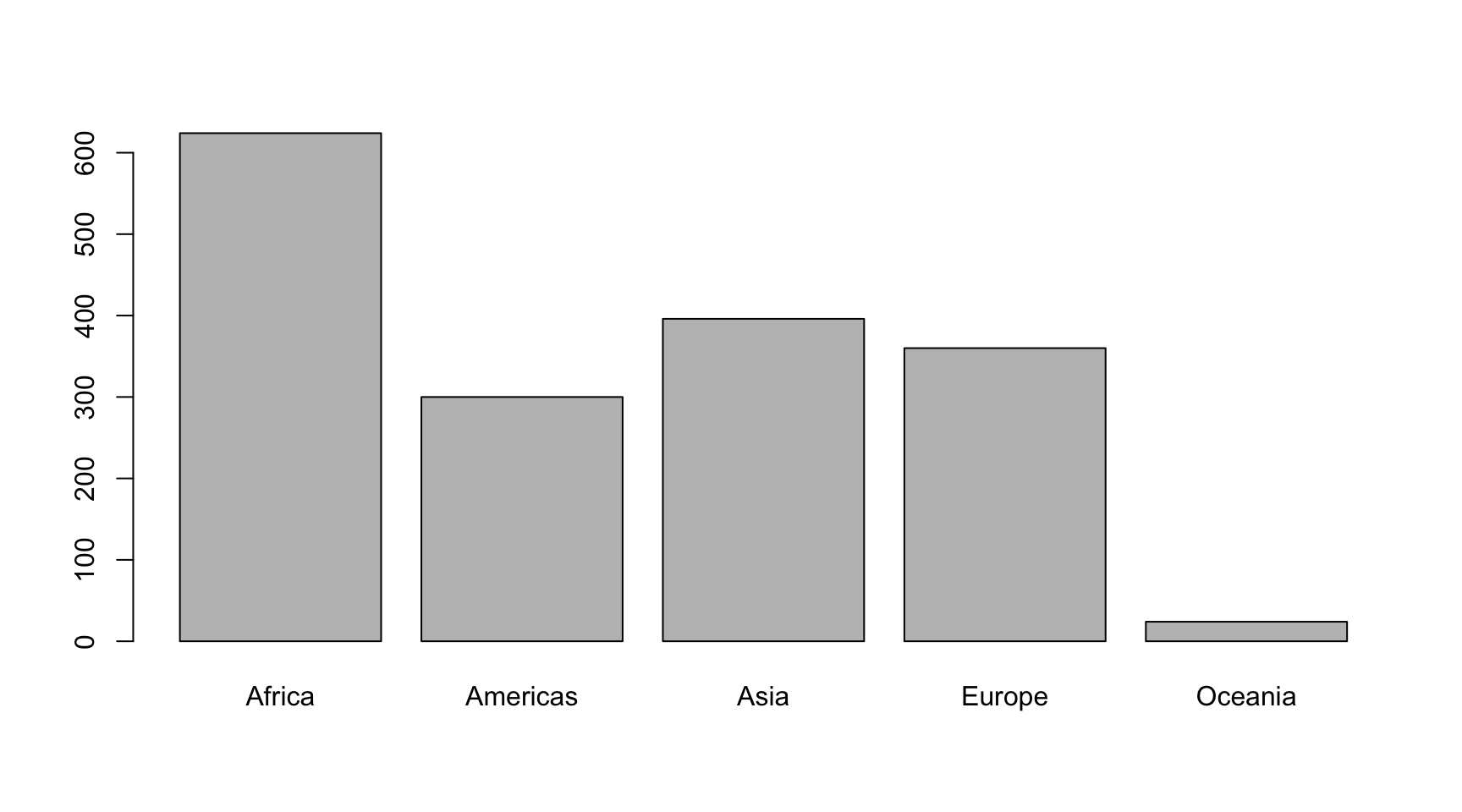
Si probamos de visualizar una variable con muchas frecuencias, es muy posible que este código no nos permita visualizar correctamente los nombres de las categorías. Para resolverlo, tenemos varias maneras, que aprenderemos en Tipos de visualizaciones.
Tanto en la tabla de frecuencias anterior como en este diagrama de barras encontraremos el estadístico que nos interesa más en las variables categóricas: la moda. La moda es el valor o valores que aparecen con más frecuencia en una distribución. En la tabla 7.1, la moda es “Quite happy”, con 234.545 ocurrencias, mientras que en el ejemplo que acabamos de ver la moda es África con 624.
No siempre encontraremos necesariamente una moda en todas las variables categóricas. A veces podemos encontrar dos (bimodal) o varias (multimodal).
7.3 Frecuencia relativa
La frecuencia relativa es la proporción o el porcentaje que representa la frecuencia absoluta de un valor en relación con el total de observaciones en una muestra o población. Volviendo al ejemplo anterior, para pedir la frecuencia relativa de una variable nominal con count() dividiremos el número de ocurrencias de cada valor por el total de observaciones. El resultado, expresado en porcentajes, se suele representar con uno o dos decimales para facilitar la interpretación.
Si utilizamos la función table(), añadiremos a la tabla de frecuencias la funciónprop.table(). R devuelve el resultado sobre 1, y por eso tendremos que multiplicar por 100 para tener la frecuencia relativa en porcentajes.
prop.table(table(gapminder$continent)) * 100
##
## Africa Americas Asia Europe Oceania
## 36.619718 17.605634 23.239437 21.126761 1.408451Y también podemos hacer el mismo procedimiento para visualizar la distribución de las frecuencias relativas. Solo habrá que añadir barplot() al código anterior para generar un diagrama de barras. Fijaos que en el eje vertical vemos los porcentajes de cada categoría.
barplot(prop.table(table(gapminder$continent)) * 100)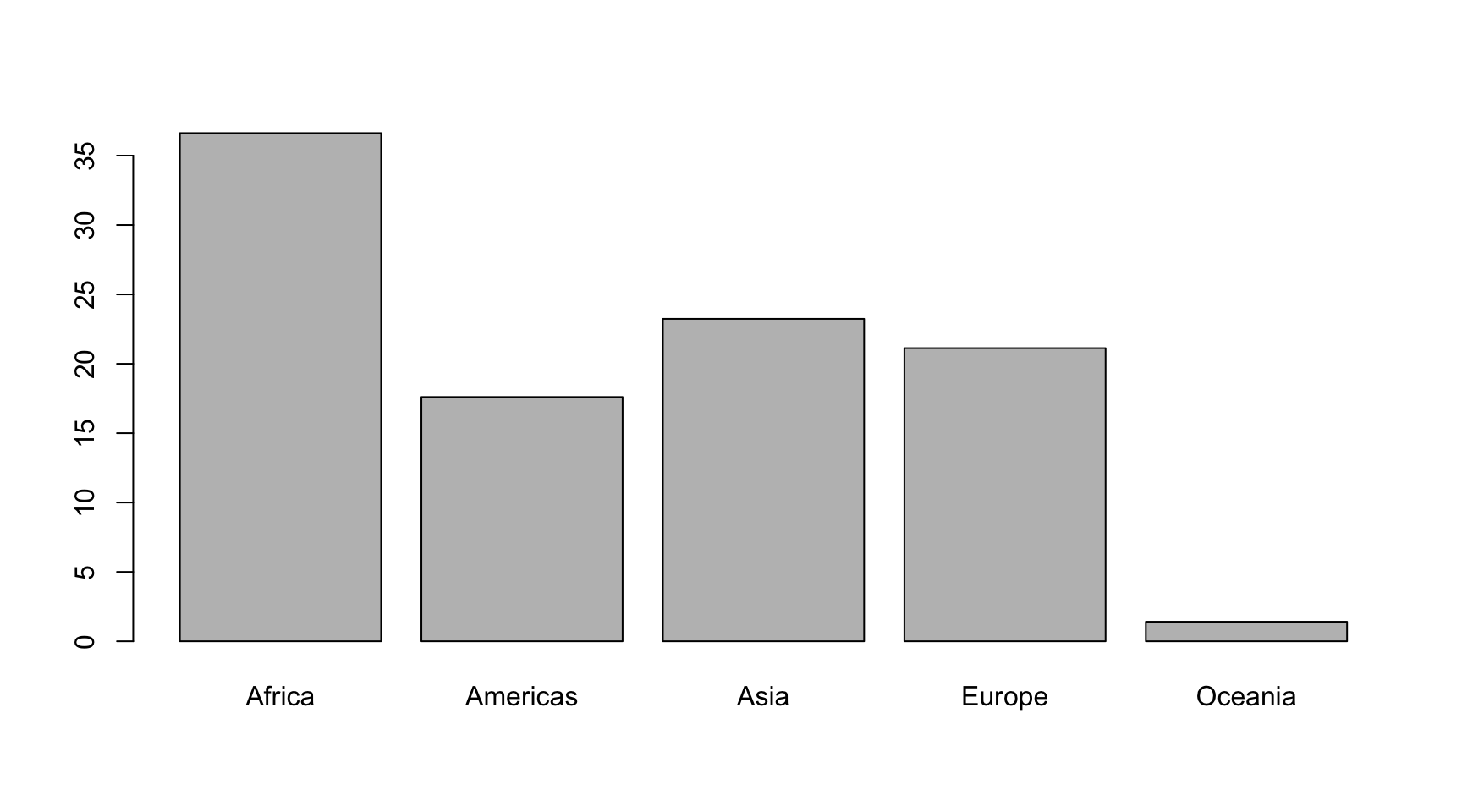
7.4 Frecuencias acumuladas
Si trabajamos con variables categóricas nominales, nos bastará con las funciones anteriores para visualizar los datos, pero si se trata de variables ordinales también nos puede interesar ver las frecuencias acumuladas para cada categoría. Es decir, querremos observar cómo se acumulan los valores y los porcentajes si los añadimos a los valores o porcentajes de las filas anteriores. En el código siguiente vemos cómo crear una tabla con frecuencias y porcentajes acumulados.
wvs |>
count(happy) |>
filter(!is.na(happy)) |>
arrange(desc(happy)) |>
mutate(n_cum = cumsum(n),
per = round(prop.table(n) * 100, 2),
per_cum = cumsum(per))
## # A tibble: 4 × 5
## happy n n_cum per per_cum
## <ord> <int> <int> <dbl> <dbl>
## 1 Not at all happy 12511 12511 2.83 2.83
## 2 Not very happy 67252 79763 15.2 18.0
## 3 Quite happy 234545 314308 53.1 71.1
## 4 Very happy 127750 442058 28.9 100Es importante que los valores en cuestión estén ordenados de menor a mayor para ver cómo los valores se acumulan en orden ascendente.
7.5 Comparar frecuencias
Con la información contenida en la tabla de frecuencias, podemos observar la importancia absoluta y relativa de cada valor en el conjunto de datos, que proporciona información sobre qué valores tienen más presencia o prevalencia en la muestra o población estudiada. Pero también facilita la comparación entre diferentes conjuntos de datos. Así, podemos entender la distribución de los datos entre grupos e identificar qué valores son más comunes o representativos en las muestras o poblaciones analizadas.
En la tabla 7.2 hemos comparado las frecuencias absolutas (n) y relativas (r) de varias variables de la WVS, que preguntan sobre la importancia de varios aspectos de la vida: la familia, los amigos, el tiempo de ocio y la política. Observamos, por ejemplo, que 915 de los 1.000 encuestados consideran que la familia es muy importante, y esto representa un 91,5 % de la muestra. Estos porcentajes son inferiores cuando preguntamos por los amigos (40,5 %), el tiempo de ocio (38,6 %) o la política (16,1 %).
| Q1 | n | r |
|---|---|---|
| 1 | 915 | 91.5 |
| 2 | 74 | 7.4 |
| 3 | 7 | 0.7 |
| 4 | 4 | 0.4 |
| Q2 | n | r |
|---|---|---|
| 1 | 404 | 40.5 |
| 2 | 449 | 45.0 |
| 3 | 116 | 11.6 |
| 4 | 28 | 2.8 |
| Q3 | n | r |
|---|---|---|
| 1 | 383 | 38.6 |
| 2 | 437 | 44.0 |
| 3 | 145 | 14.6 |
| 4 | 28 | 2.8 |
| Q4 | n | r |
|---|---|---|
| 1 | 159 | 16.1 |
| 2 | 311 | 31.5 |
| 3 | 304 | 30.8 |
| 4 | 214 | 21.7 |
Tabla 7.2: Comparación entre diferentes respuestas de la World Values Survey