9 Resumir y agrupar
9.1 Introducción
Ahora que hemos adquirido un conocimiento fundamental de las principales técnicas de análisis univariado, en este apartado aprenderemos a utilizar las funciones específicas para establecer comparaciones entre varios grupos. La comparación entre categorías es uno de los principales propósitos a los que queremos llegar cuando describimos datos, puesto que nos permite contrastar fenómenos sociales en diferentes segmentos de la población.
Hay dos funciones del paquete dplyr que, combinadas, nos permitirán resumir distribuciones y compararlas entre ellas de forma sistemática.
-
summarize(). -
group_by().
9.2 Summarize
La función summarize() es la que usaremos con más frecuencia para obtener sumarios de variables, puesto que es muy fácil de utilizar con el sistema pipe y de combinar con las otras funciones de dplyr. Dentro de summarize() tenemos que introducir la operación que haremos para resumir en un solo valor la información de una variable. Y también indicaremos el nombre que tomará la nueva variable resumida. El resultado de aplicar summarize() siempre será un nuevo marco de datos, pero normalmente mucho más reducido. La estructura de la función es la siguiente:
- Nombre (
nombre) de la nueva variable con la información resumida. - Símbolo igual (
=). - Operación, normalmente con alguna función de sumario como
max(),mean(),median(),sd(), etc.
df |>
summarize(nombre = funcion(vector))Un primer ejemplo de lo que hace summarize() lo vemos en la función siguiente. Hemos pedido el valor máximo de la variable pop del marco de datos gapminder. Fijaos que el resultado es un tibble de 1x11.
1 Hay que tener presente que el marco de datos gapminder no tiene datos perdidos, y por eso no será necesario aplicar el argumento na.rm = TRUE dentro de la función de sumario. Pero debemos tener presente que muchas veces tendremos que introducir este argumento.
gapminder |>
summarize(pop = max(pop))
## # A tibble: 1 × 1
## pop
## <int>
## 1 1318683096Dentro de summarize() podemos hacer varias operaciones. Solo hay que separar cada operación por comas siguiendo la misma estructura que acabamos de ver. En el código siguiente pedimos el máximo y el mínimo de población, la media y la mediana del PIB per cápita y el recuento de observaciones, que obtenemos con la función n().
Dentro de summarize() se pueden combinar operadores lógicos con funciones descriptivas. Como una operación lógica divide las observaciones entre TRUE y FALSE, la combinación con sum() mostrará la suma de los casos en que la operación lógica sea verdad, mientras que la combinación con mean() mostrará el porcentaje de observaciones en que la condición sea verdad. Veámoslo con algunos ejemplos.
En el marco de datos gapminder, ¿cuántas observaciones tiene su población superior a un millón de habitantes? La operación lógica pop > 1000000 crea un vector que será TRUE para los casos superiores a un millón. Seguidamente, sum() sumará todos los TRUE computando 1.524 observaciones con una población superior a un millón.
gapminder |>
summarize(milion_count = sum(pop > 1000000))# A tibble: 1 × 1
milion_count
<int>
1 1524En el marco de datos gapminder, ¿qué porcentaje sobre el total representan las observaciones que tienen la población superior a un millón de habitantes? La operación lógica pop > 1000000 crea un vector que será TRUE para los casos superiores a un millón. Como TRUE equivale al número 1 y FALSE al número 0, la función mean() nos hace la media de valores 1 sobre el total de valores. Por ejemplo, si tuviéramos cinco 1 y cinco 0, la media sería 0.5. En este ejemplo, la media es 0.894, que multiplicaremos por 100 para tener la cifra en tanto por ciento.
gapminder |>
summarize(milion_perc = mean(pop > 1000000) * 100)# A tibble: 1 × 1
milion_perc
<dbl>
1 89.4En el marco de datos gapminder, ¿cuántas observaciones son del continente asiático y cuál es la proporción? Las combinaciones sirven exactamente igual para vectores de carácter.
library(haven)
wvs |>
summarize(age_20 = quantile(age, 0.9, na.rm = T),
age_max = max(age, na.rm = T),
age_median = median(age, na.rm = T),
age_median_up = mean(age >= median(age, na.rm = T), na.rm = T) * 100)
## # A tibble: 1 × 4
## age_20 age_max age_median age_median_up
## <dbl> <dbl+lbl> <dbl> <dbl>
## 1 65 103 39 50.89.3 Group_by
Como ya sabemos, la función group_by() agrupa los datos por los valores de una variable, normalmente categórica, y se tiene que combinar con otra función para que tenga utilidad. Anteriormente, se ha utilizado group_by() en combinación con filter() y mutate(), pero la función con la que realmente se puede explotar más su potencial es summarize(). La combinación de estas dos funciones seguirá la estructura siguiente:
df |>
group_by(vector) |>
summarize(nombre = funcion(vector))Lo más esencial que se debe tener en cuenta de combinar group_by() y summarize() es que el marco de datos resultante tendrá una nueva unidad de observación, que vendrá marcada por la variable o las variables que introduzcamos en group_by(). Por ejemplo, si la unidad de observación original es el individuo y queremos agrupar los datos por país, group_by(country) hará una agrupación previa de los datos antes de que summarize() aplique los cálculos pertinentes. En el resultado, veremos el sumario de tantos países como marque la variable country.
Consideremos los marcos de datos con los que hemos trabajado hasta ahora. La columna UO Original de la tabla 9.1 muestra la unidad de observación de cada marco de datos y la columna UO modificada muestra cuál podría ser la nueva unidad de observación según se indique dentro de group_by().
| Base de datos | UO original | UO modificada |
|---|---|---|
| NUTS | Región | País |
| Gapminder | País-Año | Año, Continente, País, Continente-Año |
| WVS | Individuo | País, Año, País-Año |
| UNVotes | País-Votación-Tema | País, Votación, Tema, País-Votación, País-Tema |
La forma más fácil de ver la aplicabilidad de group_by() es intentar responder las mismas preguntas que hemos hecho en el apartado anterior pero agrupando los datos por continente. Al obtener información de la misma pregunta entre subgrupos de datos, group_by() es una herramienta que facilita la comparabilidad.
En el marco de datos gapminder, ¿cuántas observaciones de cada continente tienen su población superior a un millón de habitantes?
gapminder |>
group_by(continent) |>
summarize(milion_count = sum(pop > 1000000))# A tibble: 5 × 2
continent milion_count
<fct> <int>
1 Africa 502
2 Americas 293
3 Asia 369
4 Europe 336
5 Oceania 24En el marco de datos gapminder, ¿qué porcentaje sobre el total de cada continente representan las observaciones que tienen la población superior a un millón de habitantes?
gapminder |>
group_by(continent) |>
summarize(milion_perc = mean(pop > 1000000) * 100)# A tibble: 5 × 2
continent milion_perc
<fct> <dbl>
1 Africa 80.4
2 Americas 97.7
3 Asia 93.2
4 Europe 93.3
5 Oceania 100 En el marco de datos gapminder, ¿cuántas observaciones son del continente asiático y cuál es la proporción?
La función group_by() permite agrupar por varias variables. Si en los códigos anteriores se agrupan por continente y año, los datos estarán agrupados a la vez por continente y por año. Debemos tener en cuenta dos últimas cuestiones importantes:
- Si agrupamos la unidad de observación del marco de datos, nos devolverá exactamente el mismo marco de datos. Por ejemplo, en
gapmindersería un contrasentido agrupar por país y año, porque los datos ya están expresados en estos términos. - La función
group_by()se aplica solo en variables discretas. Esto significa que funciona bien con cualquier variable categórica, pero también con numéricas que tengan unos valores discretos, como la mayoría de las variables de intervalo. En cambio, si aplicamosgroup_by()a variables numéricas continuas, lo más probable es que nos acabe devolviendo el mismo marco de datos.
wvs |>
filter(country %in% c("KOR", "JPN")) |>
group_by(country) |>
summarize(polideol = mean(polideol, na.rm = T),
stflife = mean(stflife, na.rm = T))
wvs |>
filter(country %in% c("KOR", "JPN")) |>
group_by(country) |>
summarize(sex = mean(sex == "Male") * 100)
wvs |>
filter(country == "JPN") |>
group_by(year) |>
summarize(happy = mean(happy == "Very happy", na.rm = T) * 100)Ejercicio 9.4 (UN Votes) El código siguiente junta los tres marcos de datos de UN Votes en uno solo, donde la unidad de observación es país-votación-tema:
library(unvotes)
unvotes <- un_votes |>
left_join(un_roll_call_issues, by = "rcid") |>
left_join(un_roll_calls, by = "rcid") |>
mutate(year = as.numeric(str_sub(date, end = 4)))Con el marco de datos unvotes, responde las preguntas siguientes sobre las votaciones en la Asamblea General de Naciones Unidas (UNGA):
- Queremos observar los cambios en los patrones de voto favorable al AGNU de Estados Unidos o Canadá en función de si los votos son importantes o no (
importantvote). Muestra los datos en porcentaje de votos.
- De cada país, ¿cuál ha sido la media de votos favorables, la media de votos desfavorables y la media de abstención en la AGNU?
- ¿Cuál es el porcentaje de votos favorables de Estados Unidos en la AGNU por año y tema? ¿Cuántas observaciones tenemos en cada caso? Guarda el resultado en el marco de datos
unus.
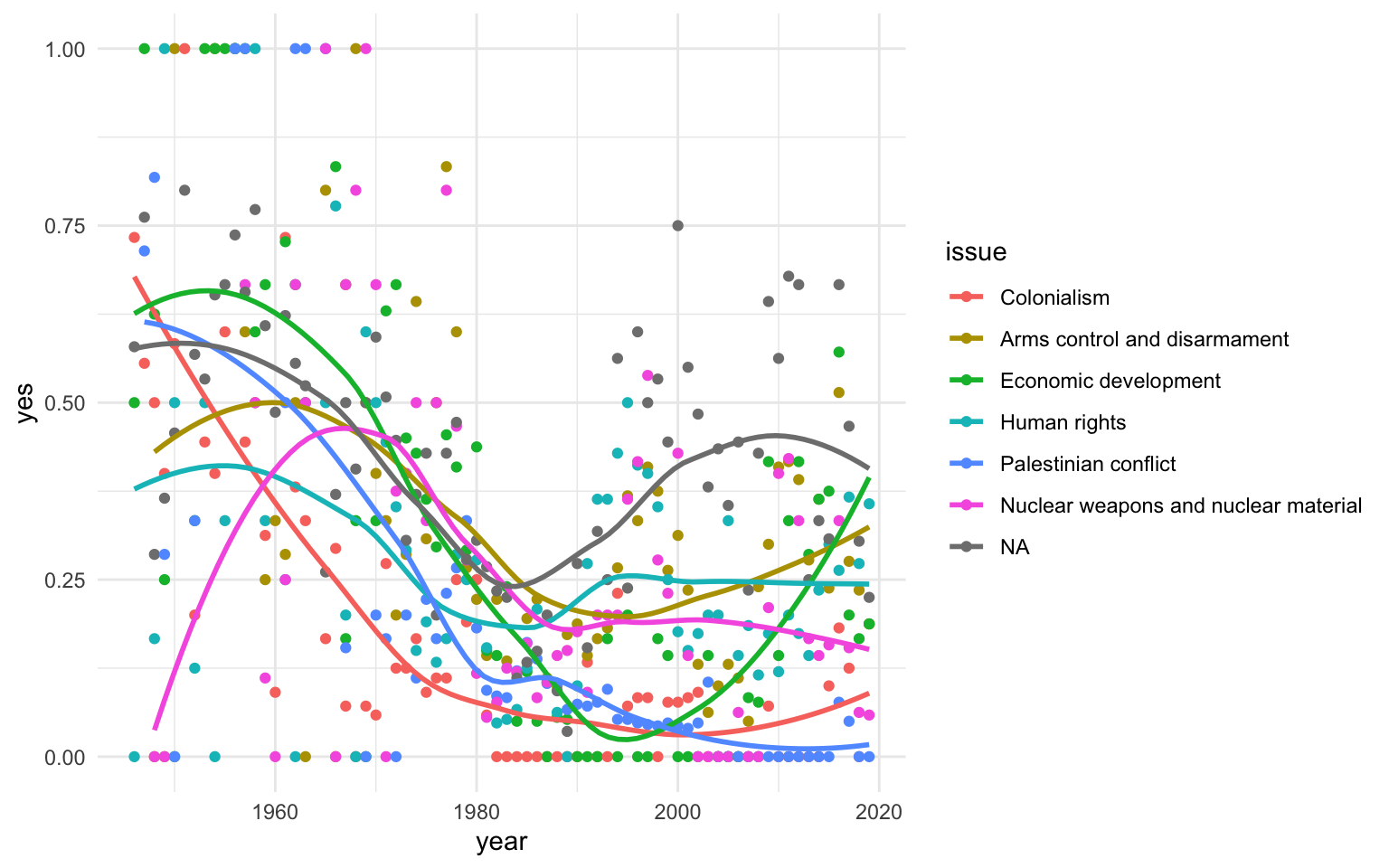
Con la creación del marco de datos anterior, podemos observar las variaciones en el comportamiento de voto favorable de Estados Unidos en la AGNU según el tema. En el próximo módulo aprenderemos a hacer gráficos como este.
unus |>
ggplot(aes(x = year, y = yes, col = issue)) +
geom_point() +
geom_smooth(se = F)