2 Incertesa
“Although we are never likely to be able to predict or thoroughly explain specific strategic interactions among states, firms, and nongovernmental organizations, we can aspire to conditional generalizations that narrow the range of our uncertainty by accounting for general patterns of behavior” (Keohane, 1997).
2.1 Introducció
A l’anàlisi de les associacions entre fenòmens socials, hem de tenir en compte que les dades amb les quals treballem presenten dues limitacions significatives: la primera és que sempre utilitzem una quantitat finita de dades, cosa que implica que hem de partir de la base que aquestes són incompletes. La segona és que les variables que utilitzem mai seran una mesura perfecta del fenomen que volem mesurar i, per això, sempre tindran problemes de validesa, per petits que siguin. Per tant, haurem de partir de la base que les dades són imperfectes. La inferència estadística és el procediment d’analitzar dades incorporant aquesta doble incertesa.
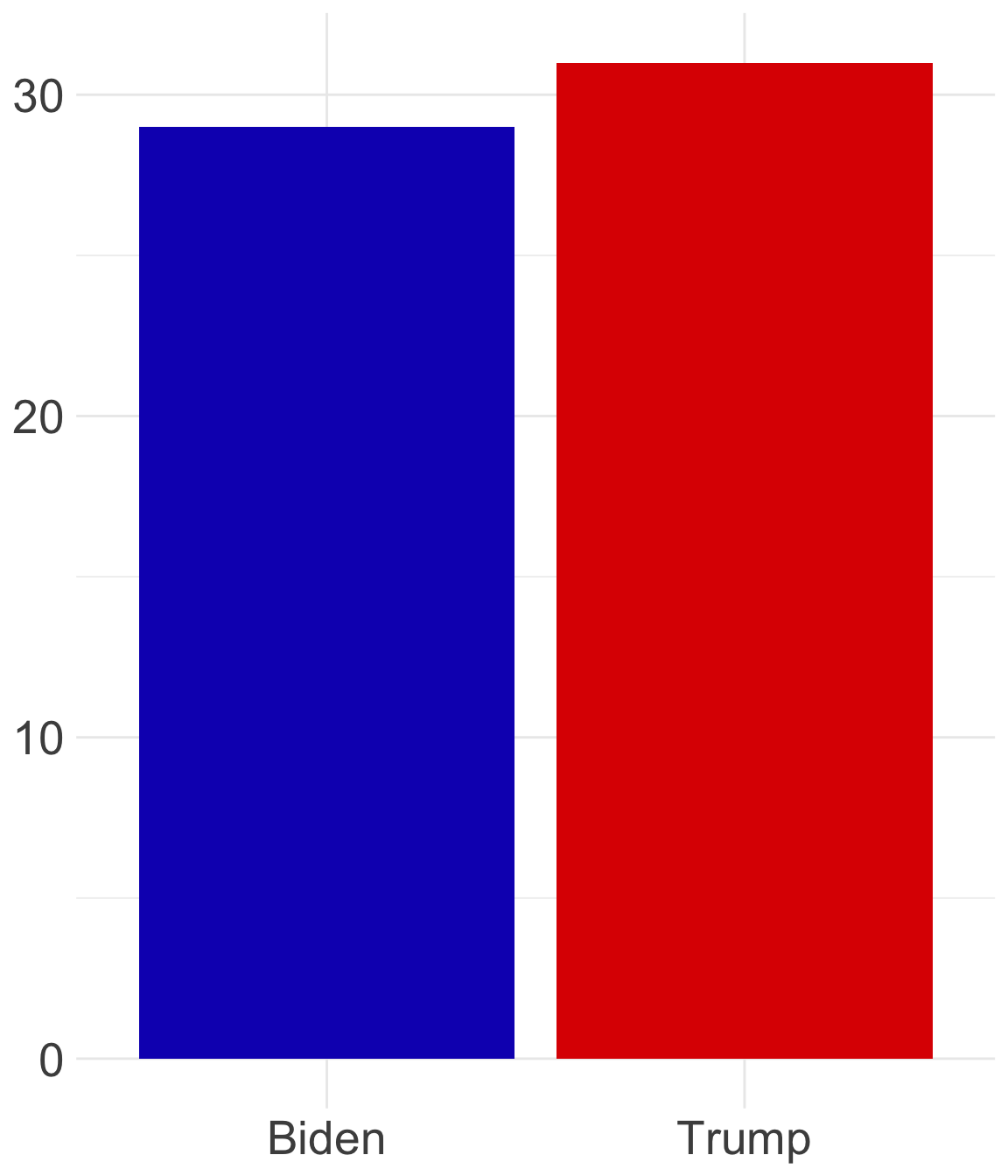
Consultem el següent exemple: el dia de les eleccions americanes de 2020 decidim fer un petit sondeig i preguntem a 60 persones que surten dels col·legis electorals a quin candidat han votat. Les respostes obtingudes s’han representat al diagrama de barres que observem a la figura 2.1, a la dreta de la pàgina, i són aquestes: 29 han votat Joe Biden i 31 han votat Donald Trump. Per tant, segons la mostra que hem recollit, hi ha més persones que votaran el candidat republicà que no pas el demòcrata. Amb aquests resultats fem una predicció: Trump guanyarà les eleccions.
Ara que ja coneixem el desenllaç electoral, podem afirmar que la predicció és equivocada, ja que, en realitat, va ser Biden qui va guanyar. I per què ens hem equivocat? Sembla evident que és molt difícil extreure conclusions sobre el comportament de tota la població americana a partir d’una mostra tan petita de 60 persones. La lògica que hi ha al darrere d’aquest raonament és que si haguéssim preguntat només a dues persones més, no hagués estat gens descabellat que també haguessin votat per Biden, el que hagués igualat els resultats a 31 vots per a cada candidat. De la mateixa manera que tampoc és gens estrany pensar que una tercera persona hagués votat per Biden, cosa que hagués canviat completament els resultats i, per tant, les nostres prediccions sobre el candidat guanyador. En altres paraules, si realitzem una enquesta a només 60 persones, les dades obtingudes seran molt incertes perquè serà possible que els resultats canvïin si recopil·lem unes quantes observacions més. Per tant, no podem estar gens segurs que els resultats observats siguin representatius del comportament de tota la població americana.
Aquest exemple il·lustra una de les limitacions més freqüents que trobem en l’anàlisi de dades: no sabem fins a quin punt les dades reflecteixen amb precisió allò que volem conèixer. Sempre hem de considerar la possibilitat, per remota que sigui, que la incertesa de les dades pugui eliminar o fins i tot contradir el que estem intentant observar, com ha succeït en la nostra modesta enquesta. Per evitar dir cap mentida a l’hora de presentar les dades, doncs, no només és important quantificar l’associació, com hem après en l’apartat anterior, sinó també quantificar la incertesa. I per incorporar la incertesa a la nostra anàlisi haurem d’aprendre com funciona l’atzar.
2.2 Les coses passen per atzar
Un dels jocs d’atzar més freqüents és llançar una moneda a l’aire i veure si surt cara o creu. Aquest resultat és totalment aleatori, llevat que la moneda estigui manipulada. La meitat de les vegades esperarem que surti cara i l’altra meitat creu. Utilitzarem el programari R per llançar, no només una vegada, sinó 10.000 vegades una moneda a l’aire:
Amb la funció sample() hem tirat 10.000 vegades una moneda a l’aire i ens ha retornat, a l’exemple, 4.941 cares i 5.059 creus. Aquesta lleugera diferència entre les cares i les creus que observem és deguda a l’atzar. Això vol dir que quan llancem moltes vegades una moneda a l’aire, no sempre obtindrem la mateixa quantitat de cares i creus, sinó que obtindrem petites diferències generades per l’atzar. En altres paraules, és perfectament possible que, fins i tot després de 10.000 intents, l’atzar faci sortir un 49.41% de les vegades cara i un 50.59% de les vegades creu.
Si l’atzar pot generar petites diferències respecte els resultats esperats quan llancem una moneda 10.000 vegades, també és possible que ens generi petites diferències amb les dades que analitzem. Aquesta circumstància planteja un problema d’inferència que cal tenir en compte. Suposem, seguint amb l’exemple anterior de l’enquesta a peu d’urna, que preguntem a 10.000 electors i un 49.4% declara haver votat Biden i un 50.6% declara haver votat Trump. Fixem-nos que aquesta diferència en els percentatges de vots entre Biden i Trump és la mateixa que hem obtingut abans quan llançàvem la moneda 10.000 vegades a l’aire. Per tant, si incorporem l’atzar en el nostre raonament, amb aquests resultats no podem estar segurs d’endevinar el guanyador, donat que aquesta mateixa diferència també es podria obtenir simplement llançant una moneda.
La possibilitat que les coses passin de manera casual ens obliga sempre a considerar la incertesa de les dades. Tenint en compte aquesta premisa, quin seria el llindar a partir del qual podem començar a pensar que la diferència és prou gran com per descartar que hagi estat produïda per l’atzar?
Entre els científics socials, existeix una convenció per la qual se sol considerar que aquest llindar el trobem per sota d’una possibilitat entre 20 que sigui atzar. En altres paraules, si la probabilitat que els resultats s’hagin produït per casualitat és inferior a 0.051, podem rebutjar amb suficient confiança que l’atzar hagi tingut alguna cosa a veure amb els resultats observats. En estadística, testejar la incertesa dels nostres resultats s’anomena test de significació.
1 1 dividit entre 20 és igual a 0.05. No obstant això, és important tenir en compte que, en alguns casos, es pot considerar que un llindar diferent és més adequat.
Veurem més clar com funciona el test de significació a partir de l’exemple de la moneda. Si una moneda està trucada, esperarem que hi hagi una desviació dels resultats respecte a l’atzar com, per exemple, que surti cara més vegades que no pas creu. La diferència serà prou àmplia o significativa com per descartar l’atzar. Comencem el test:
Les probabilitats que surti una combinació única concreta s’obté a partir de dividir 1 entre el nombre de combinacions possibles, que és 2 (cara o creu) multiplicat pel nombre de tirades.
1/2^1
## [1] 0.5
1/2^2
## [1] 0.25
1/2^3
## [1] 0.125
1/2^4
## [1] 0.0625
1/2^5
## [1] 0.03125- Llancem la moneda una vegada a l’aire i surt cara. No és sorprenent, ja que és igual de possible que surti cara com que surti creu, amb un 50% de probabilitat cada una.
- Llancem la moneda una segona vegada i surt de nou cara. La probabilitat d’aquesta ocurrència és del 25%, pel fet que en dos llançaments hi ha quatre possibles resultats: cara-cara, cara-creu, creu-cara i creu-creu. Tampoc és gens d’estranyar.
- Llancem la moneda una tercera vegada i torna a sortir cara. Això comença a ser molt més sospitós, ja que la probabilitat que això passi és només del 12.5%. Estarà trucada? Continuem.
- Tirem la moneda una quarta vegada i torna a sortir cara. Només hi ha un 6.25% de probabilitats que això sigui atzar. Comencem a sospitar de debò…
- Tirem la moneda una cinquena vegada. I torna a sortir cara! La probabilitat d’obtenir cinc cares seguides és només del 3.125%. D’acord amb els estàndards científics, com que la probabilitat és inferior al 5%, podem rebutjar que l’atzar hagi tingut res a veure amb aquest resultat tant sospitós. Per tant, podem defensar amb prou certesa que la moneda està trucada!
2.3 Intervals de significació
A continuació, il·lustrarem visualment com es comporta l’atzar. Agafarem el mateix codi que a l’exercici anterior i tornarem a tirar la moneda 10.000 vegades a l’aire. Quan arribem al final, anotarem la diferència entre els resultats de cara i creu. Per exemple, en el llançament anterior, la diferència ha estat de -118 (4941 - 5059 = -118). Repetirem aquest procediment 1.000 vegades per obtenir-ne una mostra més gran. En cada ocasió, anotarem de nou la diferència entre els resultats de cara i creu. Així, aconseguirem una variable amb 1.000 observacions i cadascuna representarà el resultat de la diferència entre cares i creus després de llançar la moneda 10.000 vegades. Utilitzarem aquesta variable per generar l’histograma de la figura 2.2, que ens ajudarà a visualitzar la distribució de les diferències entre cares i creus.
Mostra codi.
La sort pot ser un factor important en la creació de desigualtats. Xocs tecnològics, com l’aparició de Youtube o l’epidèmia del Covid-19, ens poden fer perdre el nostre lloc de treball o permetre prosperar econòmicament (Frank, 2016). Intentem quantificar aquests xocs produïts per l’atzar suposant que, en una població de 5 milions de persones, cada setmana es produeix un fet aleatori que pot ser positiu o negatiu per a cada individu. Si és positiu, l’individu guanya 10 euros addicionals al salari mensual, mentre que si és negatiu, en perd 5. Com haurà influït l’atzar al llarg de 20 anys?
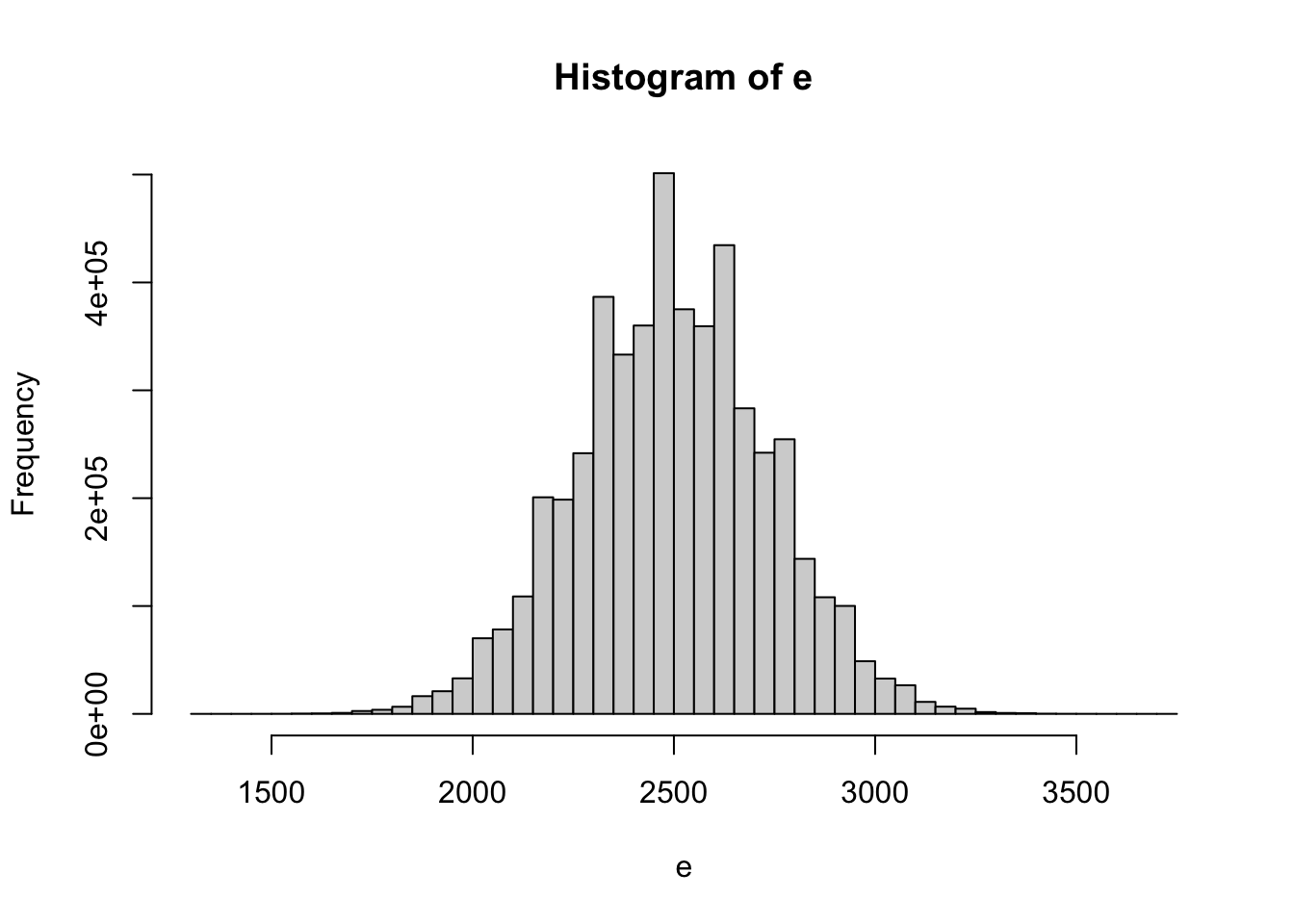
Per pura casualitat, al cap de 20 anys, algunes persones guanyaran més de 3.500 euros. En canvi, d’altres amb prou feines en guanyaran 1.500. La diferència de més de 2.000 euros s’haurà produït per atzar.
Què ens diu el gràfic? Quan llancem 10.000 vegades una moneda a l’aire, és molt probable que la diferència entre cares i creus estigui a prop del valor 0, que és la diferència mitjana teòrica entre cares i creus de llançar la moneda infinites vegades a l’aire. De fet, en un 40% de les repeticions la diferència ha estat entre -50 i +50 (si sumem les freqüències de les dues columnes del mig i les dividim entre 1.000). A mesura que ens allunyem del valor 0, els resultats es tornen menys freqüents. Sumem a ull el nombre de freqüències que es troben més enllà dels valors -200 i +200: en trobem unes 50 sobre un total de 1.000 repeticions. Això significa que, en el resultat de tirar 10.000 vegades una moneda a l’aire, aproximadament un 5% de les vegades la diferència entre cares i creus serà superior a -200 o +200.
Recordem allò que havíem dit alguns paràgrafs més amunt: els científics socials utilitzen una convenció segons la qual, si la probabilitat que els resultats observats siguin aleatoris és inferior al 5%, podem rebutjar la hipòtesi que la diferència sigui aleatòria. Per exemple, si realitzem una enquesta a 10.000 persones i obtenim una diferència de 4.899 persones que votaran a favor de Trump i 5.101 persones que votaran a favor de Biden (diferència de 202), seria improbable que aquesta diferència fos el resultat de l’atzar. En canvi, tota diferència inferior a 200 estarà per sota del llindar de confiança mínim del 5% que ens permeti descartar la hipòtesi de l’atzar.
Anem a representar aquestes franges entre les quals opera l’atzar a la figura 2.3, en forma del que es coneixen com els intervals de confiança (també dit p-valor):
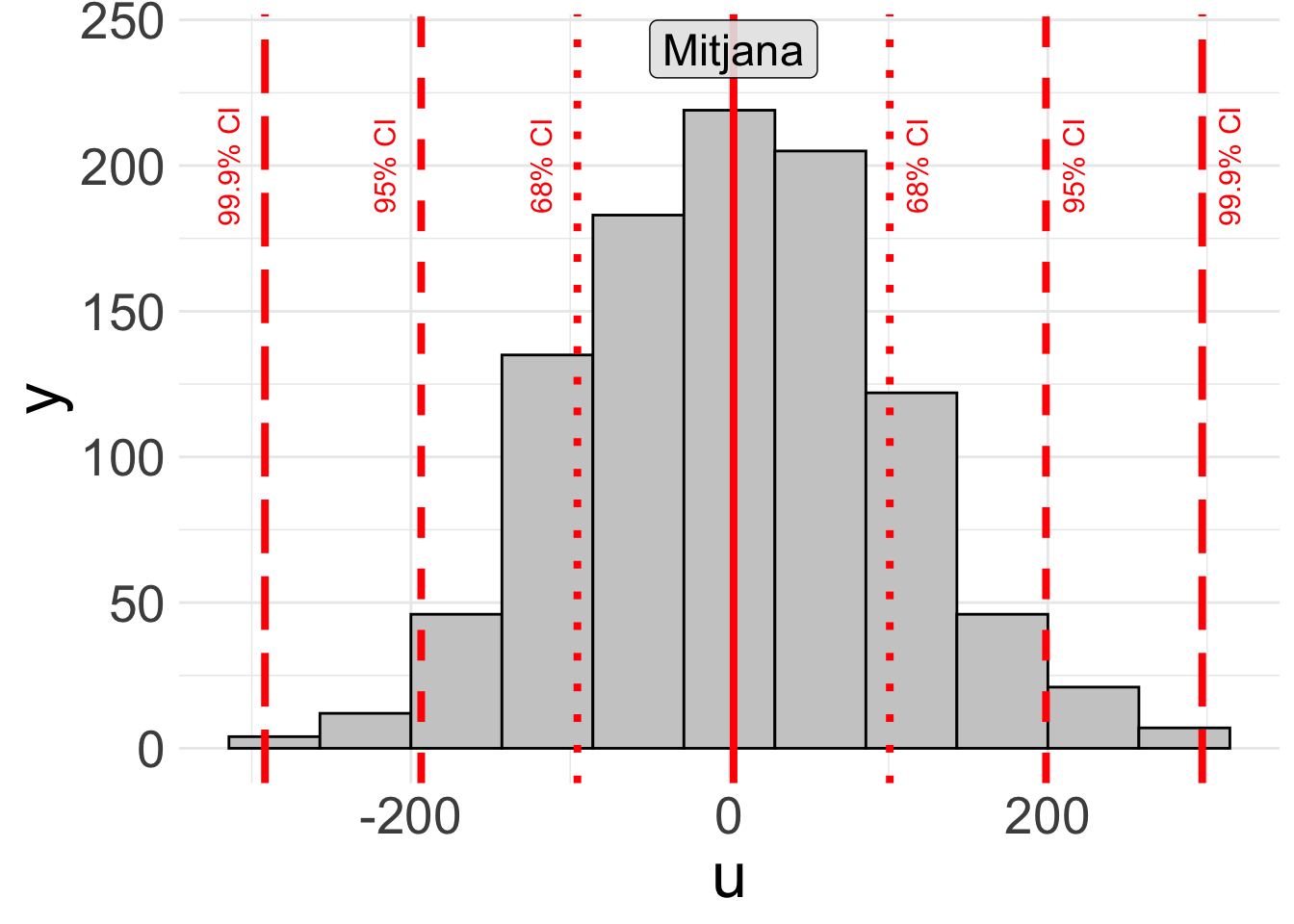
- El punt vermell representa la mitjana de la diferència entre cares i creus en 10.000 llançaments de moneda. És esperable que aquesta mitjana estigui prop del valor 0, ja que és el resultat més probable que obtindrem al calcular la mitjana de la diferència entre cares i creus quan llancem una moneda infinites vegades a l’aire.
- Les primeres línies discontínues més properes a la mitjana mostren on es troben el 68% dels casos d’aquest histograma. Aquest interval equival a una desviació típica per sobre i per sota de la mitjana.
- En molts models estadístics l’interval de confiança del 90% és representat amb un punt (
.). Aquest interval, però, no s’utilitza gaire sovint, per la qual cosa no el veiem representat en aquest gràfic. - Les línies contínues del gràfic representen un interval de confiança del 95%, el qual equival a dues desviacions típiques per sobre i per sota de la mitjana. Aquest serà el nostre principal punt de referència per determinar si una relació és significativa. Ho veurem representat en els models estadístics amb un asterisc (p-valor
*). - Un interval de confiança del 99% el representarem amb el p-valor
**. - Les línies discontínues més allunyades del centre de la distribució representen un interval de confiança del 99.99% de confiança, que equival a tres desviacions típiques sobre la mitjana. Ho veurem representat en els models de regressió amb tres asteriscos (p-valor
***).
Per tant, en qualsevol associació haurem de testar la incertesa associada a les dades. Perquè sigui significativa, l’interval de confiança de la relació haurà de ser normalment superior al 95%.
2.4 Determinants de la incertesa
De què depèn la incertesa? Com hem explicat anteriorment, les dades amb què treballem sempre són incompletes i imperfectes. En primer lloc, les dades són incompletes perquè mai podrem estar segurs que el nombre de casos amb què treballem representa amb precisió la població que volem estudiar. Sempre hem de considerar la possibilitat de poder treballar amb un nombre major de casos fins arribar a l’infinit. Per tant, cal esperar que com més casos tinguem, menor serà la incertesa.
En segon lloc, les dades de què disposem són també mesures imperfectes, ja que mai s’ajustaran prou bé al fenomen que estem estudiant. Això pot ser a causa de factors relacionats amb la precisió de les dades, com la seva validesa i fiabilitat. Així, mai podrem estar segurs que les dades representin amb precisió el fenomen en qüestió. L’únic que podem esperar és que si les dades són més precises, la incertesa serà menor.
Com que la incertesa depèn tant de la quantitat com de la qualitat de les dades, hem representat a la figura 2.4 l’efecte que tenen aquests dos factors sobre els intervals de confiança. Per a fer-ho, hem combinat mostres que es diferencien amb el número de casos (N = 200 o N = 50) i amb la precisió de les dades (desviació típica de 5 o de 10 al voltant de la mitjana). Fixem-nos com varien els intervals de confiança al 95%. El primer i el segon gràfic tenen el mateix nombre de casos, però les dades són més precises en el segon, per la qual cosa l’interval de confiança serà més petit. Si comparem el primer i el tercer gràfic, veurem que les dades tenen una imprecisió semblant (desviació típica de 10), però difereixen en el nombre de casos. Això vol dir que el tercer gràfic, amb menys casos, té un interval de confiança més ampli.
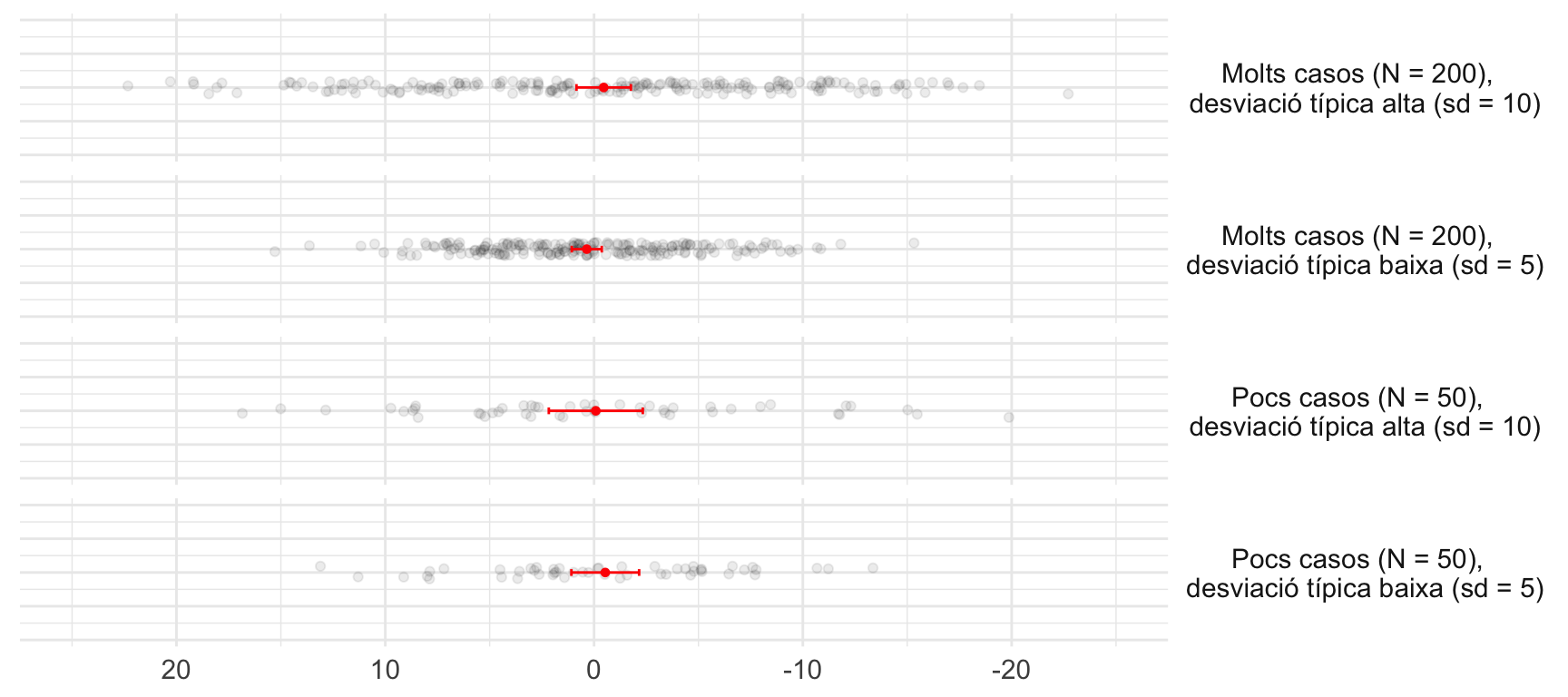
A l’anàlisi de dades és crucial tenir en compte i informar sobre la incertesa associada. Si no es fa, correm el risc de fer afirmacions que no sabem del cert. Les tècniques estadístiques ens ajuden a estimar, quantificar i visualitzar aquesta incertesa a través del coeficient de significació i dels intervals de confiança. A l’apartat següent, veurem com informar de la incertesa en l’estudi d’una relació entre dues variables.
2.5 Significació del petroli
La literatura acadèmica ha estudiat àmpliament la maledicció dels recursos naturals. Es creu que la disponibilitat de recursos naturals està negativament associada amb tres fenòmens de l’economia política internacional: el desenvolupament econòmic, la qualitat democràcia i el conflicte civil (Ross, 2015). A continuació, examinarem l’associació entre la dependència del petroli i el tipus de règim polític, tenint en compte els nivells d’incertesa de les dades.
La relació es troba il·lustrada a la figura 2.5. Per quantificar el règim polític, hem optat per utilitzar la Dichotomous Coding of Democracy dataset (Boix et al., 2013), que distingeix entre règims democràtics i règims autocràtics. Representem la variable democràcia a l’eix de les \(x\). Quantificar la dependència del petroli, en canvi, és més complex. Remenant per la base de dades del Banc Mundial, hem seleccionat dues variables que poden ajudar-nos: la primera variable, representada al diagrama de l’esquerra, mesura les exportacions de combustibles fòssils com a percentatge de les exportacions totals de mercaderies; la segona, al diagrama de la dreta, mesura el percentatge de les rendes del petroli sobre el total del PIB2. Representem aquestes variables a l’eix de les \(y\). En el gràfic, mostrem la mitjana de cada distribució i els intervals de confiança del 95%.
2 La primera variable correspon a l’indicador del Banc Mundial Fuel exports (% of merchandise exports) (codi TX.VAL.FUEL.ZS.UN), mentre que la segona variable correspon a l’indicador Oil rents (% of GDP) (codi NY.GDP.PETR.RT.ZS).
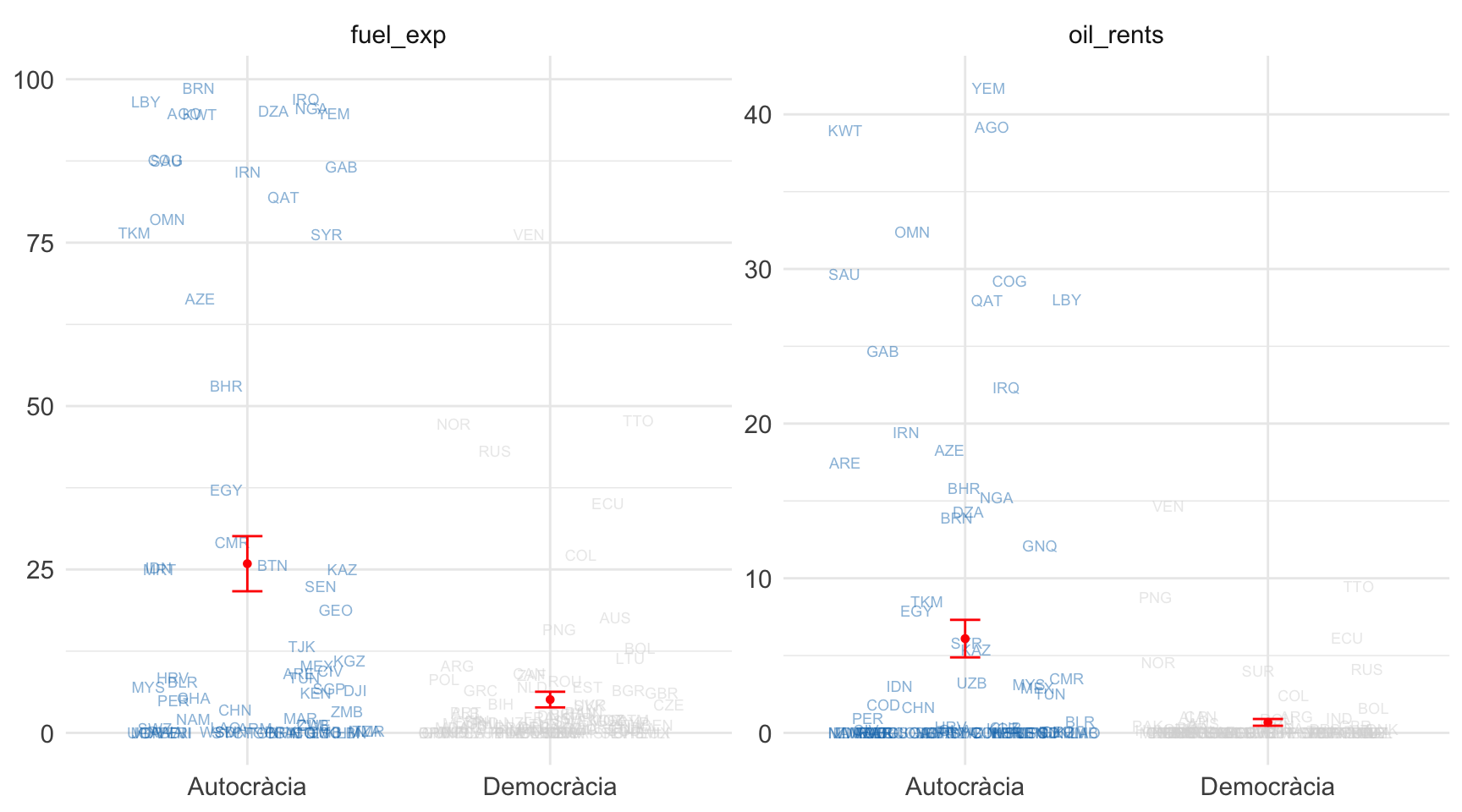
Intentarem llegir el gràfic de l’esquerra tenint en compte els intervals de confiança. En els règims autocràtics, els combustibles fòssils representen, de mitjana, el 25% de les exportacions. Però si tenim en compte la incertesa, no podem estar segurs d’on se situa exactament aquesta xifra. Serem molt més cautelosos si diem que, amb un nivell de confiança del 95%, aquest valor se situa aproximadament entre el 20% i el 30%. En canvi, en el cas de les democràcies, observem que els valors estan més concentrats a la part inferior del gràfic, cosa que indica una menor dependència del petroli. Com que hi ha més precisió, observem com l’interval de confiança és més reduït en comparació amb la distribució d’autocràcies. En aquest cas, la mitjana d’exportacions de combustibles fòssils a les democràcies se situa al 5% però, per estar-ne més segurs, direm que, amb un 95% de confiança, aquest valor es troba aproximadament entre el 3% i el 7%.
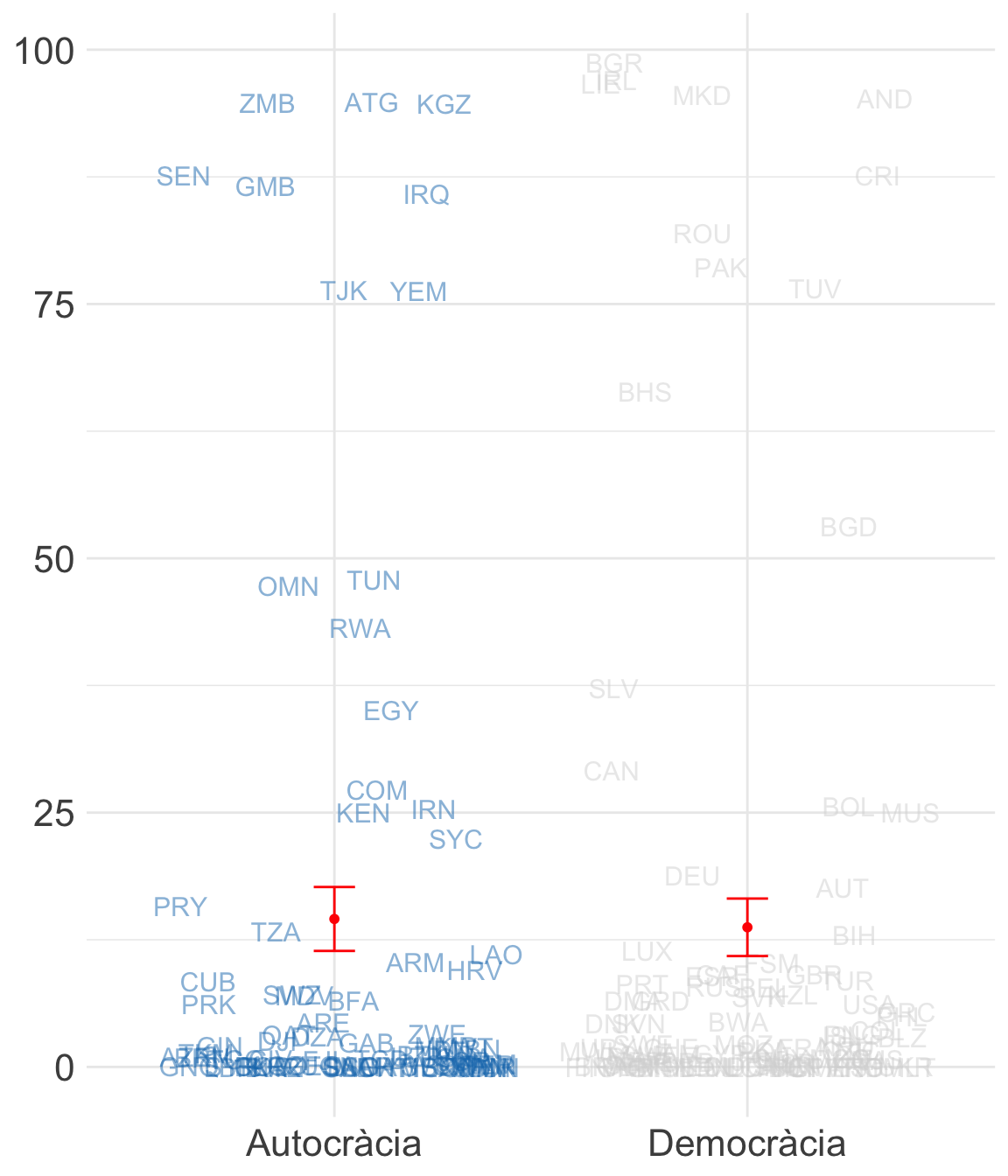
En el gràfic de l’esquerra de la figura 2.5 hem descartat que les diferències observades hagin estat produïdes per l’atzar. Això és perquè la mitjana d’exportacions de combustibles fòssils a les autocràcies és, com a mínim, del 20%, mentre que la mitjana d’exportacions a les democràcies és, com a màxim, del 7%. Com que els intervals de confiança no se solapen, això indica que és molt improbable que la diferència sigui 0. En canvi, el cas contrari és el que veiem a la figura 2.6, que trobem al marge dret de la pàgina. En aquest cas, quan comparem els intervals de confiança ens trobem que aquestes diferències no són significatives. És a dir, ens movem amb un rang d’incertesa en què no podem afirmar amb seguretat que aquestes diferències realment existeixin.
Per què el 0.05 va esdevenir l’estàndard de significació estadística? La resposta es remunta al 1926, quan Ronald A. Fisher va suggerir en un article del Journal of the Ministry of Agriculture of Great Britain un mètode d’inferència basat en només dos valors: el p-valor de 0.05 i el de 0.01. Segons Hurlbert & Lombardi (2009), R. A. Fisher sabia que el mètode d’inferència desenvolupat per Karl Pearson anys abans era millor que la seva aproximació binària, però K. Pearson no va permetre a R. A. Fisher utilitzar les seves taules en el seu nou llibre. Així doncs, R. A. Fisher va haver de publicar les seves obres utilitzant els p-valors de 0.05 i 0.01 com a referència, i aquests van acabar sent, a la llarga, acceptats com a estàndard per la comunitat acadèmica.
2.6 Hipòtesi nul·la
El què hem vist en l’apartat anterior ens porta a una trista però molt important conclusió: mai podem descartar del tot que una relació entre dues variables sigui produïda per l’atzar. Això significa que, per ridícula que sembli, sempre hi haurà una possibilitat que allò que observem estigui passant per pura casualitat. Aquesta premissa és clau per comprendre el que realment fan els testos estadístics: mai ens diran si dues variables estan relacionades o no, sinó que ens diran la probabilitat que aquesta relació sigui produïda per l’atzar. Donem alguna volta a aquesta idea.
Com investigadors socials, el nostre objectiu principal és analitzar la relació entre dues variables, ja que creiem que poden estar relacionades. Per tant, formularem una hipòtesi que expressi aquesta relació com, per exemple, la següent: “Els estats que comparteixen una llengua comuna tendeixen a establir aliances més fortes entre ells”. Si la nostra afirmació es compleix, esperaríem trobar, en mitjana, un major nombre d’aliances entre els estats que comparteixen una mateixa llengua en comparació amb aquells que no la comparteixen. A aquesta hipòtesi inicial n’hi direm hipòtesi alternativa i l’anomenarem “alternativa” perquè no és el que realment testem en una anàlisi estadística.
El que realment estem testant en l’anàlisi estadística és el contrari de la hipòtesi alternativa, és a dir, la probabilitat que les diferències observades entre les variables sigui el resultat de l’atzar. A això, n’hi diem hipòtesi nul·la, que en l’exemple podríem definir més o menys de la manera següent: “De mitjana, no hi ha diferències significatives en el nombre d’aliances signades entre els Estats que comparteixen una mateixa llengua i els que no la comparteixen”. Si aquesta probabilitat és superior a 0.05, acceptarem la hipòtesi nul·la, la qual ens indica que no hi ha una diferència significativa entre les variables. Si, en canvi, la probabilitat és inferior a 0.05, rebutjarem la hipòtesi nul·la i acceptarem la hipòtesi alternativa, la qual ens indica que hi ha una relació estadísticament significativa entre les variables.
Aquesta idea és important a l’hora de llegir els resultats dels tests de significació. En un test, el p-valor ens indicarà la probabilitat que la hipòtesi nul·la sigui certa. Per exemple, un p-valor inferior a 0.05 ens indica que hi ha menys d’un 5% de probabilitats que la hipòtesi nul·la sigui certa. Això vol dir que podem rebutjar la hipòtesi nul·la amb un nivell de confiança del 95% i acceptar la hipòtesi alternativa.