cor <- cor(whogov$n_minister,
whogov$gdpcap, use = "pairwise.complete.obs")
cor
## [1] -0.149410110 Independent numèrica
10.1 Introducció
Per examinar una associació en què la variable independent és numèrica, és habitual utilitzar una tècnica que es coneix com la regressió. Anteriorment, ja hem vist que la línia de regressió té dues propietats principals. En primer lloc, és la línia que millor explica la relació entre dues variables. I, en segon lloc, ens permet crear un model que facilita estimar i aproximar-nos als valors d’una variable quan coneixem els valors de l’altra. En aquest capítol, ens centrarem més en les tècniques estadístiques que s’apliquen a l’anàlisi de regressió mitjançant exemples concrets relacionats amb les ciències socials.
En funció de si la variable dependent és numèrica o categòrica, farem servir una tècnica diferent de la regressió. Si la dependent és numèrica, utilitzarem la regressió lineal, mentre que si la dependent és categòrica, farem servir la regressió logística.
En essència, els estadístics que busquem en els dos mètodes són molt semblants, i per això ens detindrem més estona a explicar la regressió lineal i avançarem més ràpidament en l’apartat de la regressió logística. També és important recordar que aquests procediments són normalment el primer pas cap a l’anàlisi multivariada.
10.2 Regressió lineal
En una relació bivariada en què les variables independent i dependent són numèriques, la tècnica principal utilitzada és la regressió lineal. Aquesta tècnica és la més habitual en treballs de recerca amb dades quantitatives. Al llarg d’aquest capítol farem servir exemples extrets d’una nova base de dades recopilada per Nyrup & Bramwell (2020), en la qual es compila informació sobre tots els governs que van governar tots els països del món entre el 1966 i el 2016. En concret, ens fixarem a entendre millor per què hi ha diferències en el nombre de membres als gabinets.
Per estudiar l’evolució i les diferències de la mida dels governs de tot el món, la base de dades ens dona informació sobre la principal característica que ens interessa: el nombre total de ministres per país i any. A més a més, ens proporciona altres variables interessants: quantes legislatures fa que presideix el govern el mateix individu, el nombre de dones ministres, el nombre de militars ministres, el percentatge de ministres que repeteixen d’un govern a l’altre, el nombre de partits que formaven part del govern, etc.
Més enllà de la riquesa d’aquesta base de dades, podem pensar que la riquesa d’un país pot estar relacionada amb el nombre de ministeris. Podríem pensar, per exemple, que els països més rics poden dedicar més recursos a la gestió política; ara bé, també podríem pensar el contrari, que als països més pobres hi haurà més interès per crear càrrecs polítics ben remunerats. Tot això són consideracions que requereixen una anàlisi empírica. El que farem és combinar la base de dades de Nyrup & Bramwell (2020) amb les dades anuals de PIB per càpita per a cada país extretes del Banc Mundial1.
1 Les dades s’expressen en milers de dòlars corrents.
La formació de governs
L’exercici del poder polític s’executa gairebé sempre de manera col·legiada. Fins i tot en casos de dictadures personalistes, el dictador/a sempre s’envolta d’un govern format per un nombre variable de ministeris des d’on s’executen les decisions polítiques en cada àmbit sectorial. Aquest repartiment de tasques s’exerceix de maneres molt diferents en cadascun dels països del món. Mentre que hi ha llocs, com Suïssa, on el nombre de membres de l’executiu és sempre de 7 persones, el més habitual és que el nombre de persones que conformen el consell de ministres sigui variable.
Les ciències socials, i en especial la ciència política, ha dedicat molts esforços a entendre més bé com funciona el procediment de formació de governs i de selecció de les persones que conformen el poder executiu. Una contribució inicial la va fer William Gamson (1961), que va definir la llei de Gamson: en un govern de coalició el nombre de ministres es correspon a la proporció de diputats que aporta cada partit a la coalició. Altres autors també s’han interessat a estudiar dinàmiques de reformes dels gabinets però no és fins als anys 2010 que creix l’interès per entendre els factors rere el nombre de ministeris.
Després d’una primera exploració de les dades, hem comprovat que les dues variables d’interès són n_minister, que ens indica el nombre de ministres que forma part de cada gabinet i actuarà com a variable dependent, i gdpcap, que ens indica el PIB per càpita i actuarà com a variable independent.
A l’hora de quantificar la força i la direcció de la relació entre la mida del govern i el desenvolupament econòmic, utilitzarem la funció cor(), que ens mostra el coeficient de correlació entre les dues variables. En el primer argument, indicarem la variable dependent, en el segon, la variable independent, i en el tercer, l’argument use = "pairwise.complete.obs"2. Observem que la relació entre l’antiguitat de les OIs i el seu nivell de delegació és de -0.15 sobre 1, fet que significa que és una correlació negativa però relativament baixa.
2 No és el cas de l’exemple, però amb dades perdudes el resultat de l’operació seria NA, ja que per defecte es calcula r de totes les observacions. Amb use = "pairwise.complete.obs" només conservem les observacions completes a l’hora de fer l’operació, per la qual cosa sempre ens retornarà un resultat.
Si elevem el coeficient de correlació al quadrat obtindrem el coeficient de determinació (R2). Com veiem, la variació en la variable independent ens permet entendre un 2.2% de la variabilitat de la variable dependent.
cor^2
## [1] 0.02232339La millor manera que coneixem per visualitzar la relació entre dues variables numèriques ja sabem que és amb un diagrama de dispersió (figura 10.1). Representarem la línia OLS (Ordinary Least Squares, o Mínims Quadrats Ordinaris en català) amb la funció geom_smooth() i a dins de la funció especificarem dos arguments: el mètode de la regressió lineal (method = "lm") i si volem veure l’interval de confiança de la recta ombrejat en gris, que per defecte ens marcarà el 95%.
Mostra codi
whogov |>
ggplot(aes(x = gdpcap, y = n_minister)) +
geom_point(size=1) +
geom_smooth(method = "lm", se = TRUE)+
labs(x = "PIB/càpita (milers $)", y = "Número de ministres")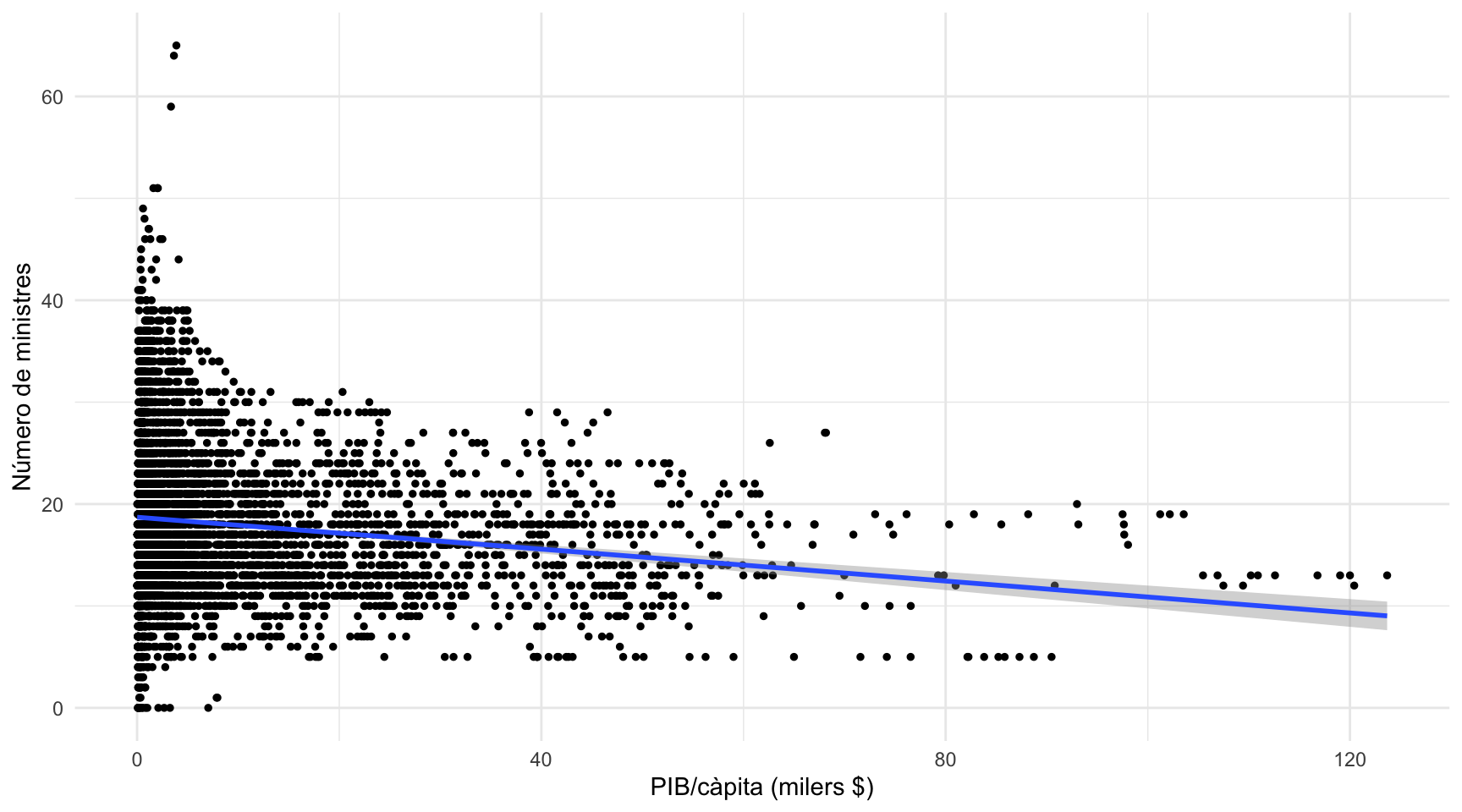
A ull, ja podem observar dues coses: que la recta té pendent negatiu i que la relació és estadísticament significativa. Sabem que la relació és significativa perquè els marges grisos dels intervals de confiança cobreixen valors diferents i no se superposen al llarg de tota la recta. Si la relació entre les dues variables no fos significativa els intervals de confiança serien més grans i seria possible dibuixar una línia recta horitzontal d’extrem a extrem del gràfic dins dels marges de confiança marcats pels marges grisos.
Tornant a les dades representades a la figura 10.1, a continuació generarem un model de regressió que expliqui la relació entre el nombre de ministres i el PIB per càpita. El model es crea amb la funció lm(), on especificarem el marc de dades que utilitzarem a l’argument data i les variables que volem incloure en el model a l’argument formula. Primer posarem la variable dependent, seguit del símbol ~ i finalment la variable independent. La informació l’hem desat a l’objecte model_lm i hem demanat un sumari d’aquest objecte.
model_lm <- lm(data = whogov, formula = n_minister ~ gdpcap)
summary(model_lm)
##
## Call:
## lm(formula = n_minister ~ gdpcap, data = whogov)
##
## Residuals:
## Min 1Q Median 3Q Max
## -18.701 -4.715 -0.902 4.308 46.598
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 18.705973 0.093371 200.34 <2e-16 ***
## gdpcap -0.078277 0.006111 -12.81 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.973 on 7186 degrees of freedom
## (869 observations deleted due to missingness)
## Multiple R-squared: 0.02232, Adjusted R-squared: 0.02219
## F-statistic: 164.1 on 1 and 7186 DF, p-value: < 2.2e-16Fixem-nos en els següents paràmetres d’aquests resultats:
- A l’apartat Coefficients veiem els coeficients estimats del model (columna Estimate). A la fila de la constant (intercept), observem que el nombre de ministres en un hipòtetic país amb un PIB per càpita de zero milers de dòlars seria de 18.71 (cal recordar que es tracta d’un model). Per cada unitat de PIB per càpita que augmentem (en aquest cas 1 unitat equival a mil dòlars), la variable dependent disminueix aproximadament en 0.078 ministres.
- En el mateix apartat, però a l’última columna (Pr(>|t|)), podem veure que la relació entre el nombre de ministres i el PIB per càpita és significativa, ja que el valor p associat és de 2e-16 (és a dir, 0.0000000000000002). En termes de confiança estadística, quan el valor de probabilitat (valor p) és inferior a 0.05 podem estar segurs amb un 95% de confiança que els resultats no s’han produït per atzar.
- L’R2 del model (Multiple R-squared) és de 0.02232, fet que indica que no podem saber gran cosa dels valors de la variable dependent a partir dels valors de la variable independent.
Malgrat que el model tingui una capacitat predictiva molt baixa, això no treu que amb els resultats de la regressió puguem crear una fórmula per predir els valors de la variable nombre de ministres a partir dels valors de la variable PIB per càpita:
\[ Ministres = 18.705973 + PIB * -0.078277 \]
Amb aquesta fórmula podem predir, per exemple, el nombre de ministres de dos països amb un nivell de desenvolupament econòmic diferent. Si pensem en un país pobre amb un nivell de PIB per càpita bàix, posem 5000$, el nombre de ministres predit seria de 18.3; en canvi per a un país ric amb un PIB per càpita de 40000$ seria de 15.6.
pibbaix <- 5
18.705973 + pibbaix * (-0.078277)
## [1] 18.31459
pibalt <- 40
18.705973 + pibalt * (-0.078277)
## [1] 15.57489Aquest, no obstant, és un model molt pobre, tal com ens indica l’R2. Més endavant, en l’apartat d’anàlisi multivariant intentarem millorar el model de regressió amb la incorporació de noves variables.
Solució a l’exercici
El país amb més partits al govern va ser l’Iraq l’any 2011.
Amb la funció cor(), demanem el coeficient de correlació, que és de 0.25. L’R2 és de 0.064.
cor <- cor(whogov$n_party,
whogov$n_minister,
use = "pairwise.complete.obs")
cor
cor^2Visualment, observem que la relació és positiva i és clarament significativa.
whogov |>
ggplot(aes(x = n_party, y = n_minister)) +
geom_point() +
geom_smooth(method = "lm", se = TRUE)Creem el model de regressió. Quan no hi ha cap partit polític al govern, el nombre de ministres és de 16.2. A més a més, observem que per cada nou partit que s’afegeix al gabinet, el nombre de ministres creix en 0.91.
La fórmula per predir els nivells del nombre de ministres en funció del nombre de partits seria la següent:
\[Ministres = 16.19321 + Partits * 0.91617\]
La línia LOESS
A diferència de l’OLS, que és una línia completament recta, la línia Locally Estimated Scatterplot Smoothing (LOESS) s’intenta ajustar a la distribució dels punts. Aquesta línia és especialment útil en línies temporals, ja que ens permet fer previsions de tendència.
Per utilitzar la línia LOESS, hem de substituir a geom_smooth() l’argument method = "lm" per l’argument method = "loess". Amb l’argument span controlem la sensibilitat de la línia. Més proper a 0, la sensibilitat serà més alta i la línia tindrà canvis més abruptes. Més proper a 1, la línia serà més harmònica.
Mostra codi
whogov |>
ggplot(aes(x = gdpcap, y = n_minister)) +
geom_point(size=1) +
scale_x_continuous(breaks = seq(0, 120, by = 10))+
geom_smooth(method = "loess", span = 0.05)+
labs(x = "PIB/càpita (milers $)", y = "Número de ministres")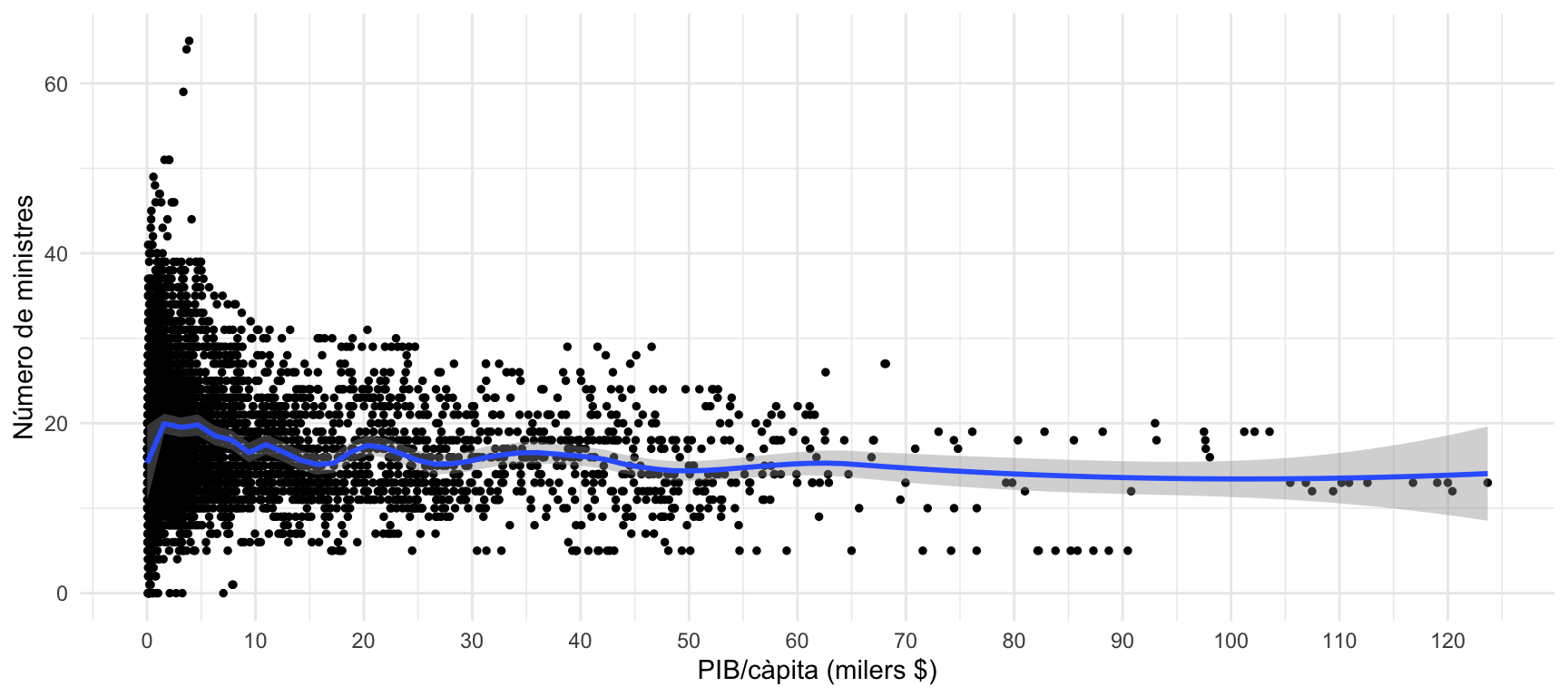
En aquest cas, quan apliquem l’ajustament LOESS a les dades que relacionen el PIB per càpita i el nombre de ministres al govern, observem una relació diferent entre les variables. La tendència sembla ser creixent per a valors baixos de PIB per càpita i descendent entre 5 i 15 mil dòlars per càpita. A partir d’aquests valors de riquesa la mida del gabinet no sembla que sigui sensible a variacions en els nivells de PIB per càpita.
10.3 Regressió logística
A l’hora d’analitzar una relació bivariada en què la variable independent és numèrica i la dependent és categòrica (concretament, binària), la tècnica estadística més utilitzada és la regressió logística3. Aquest mètode ens permet estimar les probabilitats que un esdeveniment passi o no passi a partir, en aquest cas, de dades numèriques. Seguint amb les mateixes dades, investigarem si el nivell de desenvolupament econòmic influeix en la probabilitat que en un país hi hagi ministres dones. Gràcies al model de regressió logística, podrem predir la probabilitat d’observar dones al govern a partir del nivell de PIB per càpita.
3 Si la variable dependent fos categòrica amb més de dues categories s’hauria de fer servir una regressió multinomial. Aquests models de regressió s’escapen de l’abast d’aquest curs.
Intuïtivament, hauríem d’esperar que la incorporació de les dones al mercat de treball i a l’esfera pública s’ha produït majoritàriament en països amb majors nivells de desenvolupament econòmic. Els nivells de desigualtat per gènere, per bé que variables, solen ser menors als països més desenvolupats. Per tant, seria raonable hipotetitzar que als països més rics serà més freqüent observar alguna dona al poder executiu.
Com a variable independent, utilitzarem la mateixa variable que hem fet servir a l’anterior apartat (PIB per càpita) obtinguda del Banc Mundial. Pel que fa a la variable dependent, farem servir una variable dicotòmica resultant de modificar la informació que ens proporcionava la base de dades WhoGov de Nyrup & Bramwell (2020). A partir de la variable que indica el nombre de ministres dones, simplement hem recodificat aquesta informació en una nova variable (female_minister) per tal que quan no hi ha ministres dones aquesta variable adopti el valor 0 i quan hi ha una o més ministres dones adopti el valor 1. A la taula 10.1 veiem els casos amb major nombre de ministres dones en termes absoluts i relatius.
| country_name | year | n_female_minister |
|---|---|---|
| Canada | 2016 | 15 |
| Canada | 2017 | 15 |
| Canada | 2018 | 15 |
| France | 2017 | 15 |
| France | 2018 | 15 |
| South Africa | 2011 | 15 |
| country_name | year | fem_perc |
|---|---|---|
| Finland | 2009 | 66.7 |
| Cambodia | 1979 | 66.7 |
| Slovenia | 2016 | 61.5 |
| Finland | 2007 | 61.1 |
| Austria | 2005 | 60.0 |
| Austria | 2006 | 60.0 |
Taula 10.1: Països amb major nombre de ministres dones en termes absoluts i relatius
Mentre que la regressió lineal busca la línia més recta possible que expliqui la relació entre variables, la línia de la regressió logística no és necessàriament recta. Això és així perquè, per definició, en una regressió logística la variable dependent només pot adoptar dos possibles valors (0 o 1). Per tal d’adaptar-se a aquests constrenyiments, la línia d’estimació de la regressió logística sempre es trobarà entre aquests dos valors.
A la figura 10.2 veiem una visualització típica d’una regressió logística amb les dades que hem descarregat. Hem posat la variable dependent female_minister a l’eix de les \(y\) i la variable independent gdpcap a l’eix de les \(x\). Fixem-nos que els punts de la part inferior del gràfic mostren el PIB per càpita de tots els països que no tenen cap dona a l’executiu i els punts de la part superior mostren el PIB per càpita de tots els països on, com a mínim, hi ha una dona al gabinet executiu. La recta de regressió prediu les probabilitats d’observar una dona ministra en funció del nivell de riquesa del país. Fixeu-vos que a partir d’un cert nivell de desenvolupament econòmic, la recta s’acosta cada cop més al valor 1, però mai arriba a sobrepassar-lo.
Mostra codi
whogov |>
ggplot(aes(x = gdpcap, y = female_minister)) +
geom_point() +
geom_smooth(method="glm", method.args = list(family = "binomial"))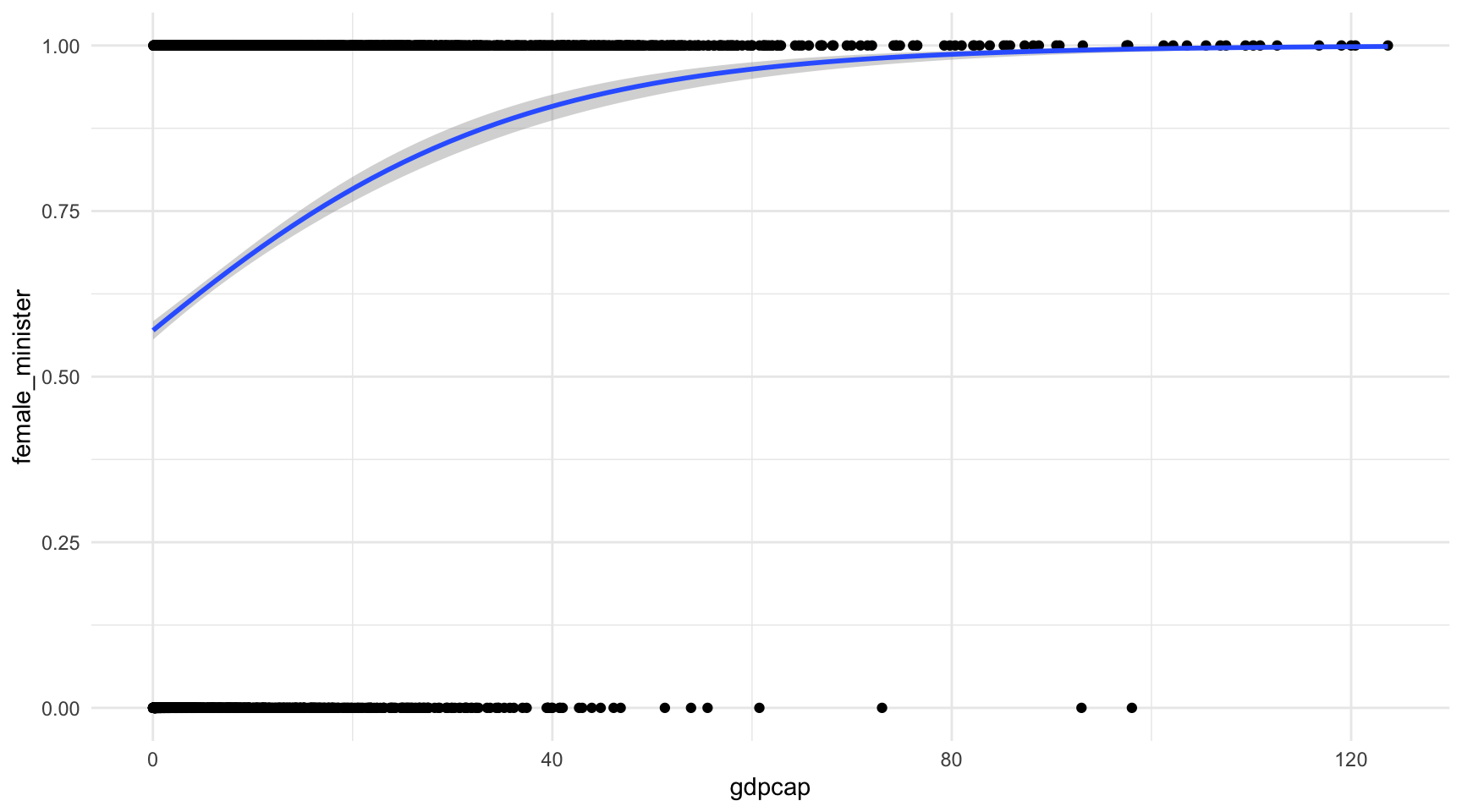
També podem calcular els coeficients de correlació i de determinació, amb les funcions que ja coneixem:
cor <- cor(whogov$female_minister, whogov$gdpcap, use = "pairwise.complete.obs")
cor
## [1] 0.1977472
cor^2
## [1] 0.03910394Ara ja podem demanar el model de regressió logística. El codi que hem de fer servir és molt semblant al que hem utilitzat en la regressió lineal, amb la diferència que utilitzarem la funció glm() i a dins especificarem l’argument family = "binomial".
model_glm <- glm(data = whogov,
formula = female_minister ~ gdpcap,
family = "binomial")
summary(model_glm)
##
## Call:
## glm(formula = female_minister ~ gdpcap, family = "binomial",
## data = whogov)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -3.2296 -1.3073 0.8249 1.0320 1.0598
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 0.280654 0.028847 9.729 <2e-16 ***
## gdpcap 0.050277 0.003245 15.494 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 9408.8 on 7187 degrees of freedom
## Residual deviance: 9036.6 on 7186 degrees of freedom
## (869 observations deleted due to missingness)
## AIC: 9040.6
##
## Number of Fisher Scoring iterations: 5En el sumari del model, ens haurem de fixar en el següent:
- El coeficient significació de la variable independent es troba a la columna Pr(>|z|). Tot i que en el gràfic ja hem vist a ull que la relació era significativa, en els resultats observem que el valor p és, de nou, de 2e-16 (és a dir, 0.0000000000000002), i per això podem considerar que la relació entre PIB per càpita i presència femenina al govern és significativa amb més d’un 95% de confiança (de fet, amb un valor tan baix podem dir que és significativa amb un 99.9% de confiança).
- Interpretar els coeficients estimats és més complicat, perquè els coeficients del model que es troben a la columna Estimate es troben deformats per la funció logit. Per tant, per poder interpretar correctament els coeficients haurem d’invertir abans els valors amb aquesta funció:
Un cop creada la funció, ja podem aplicar-la per calcular les probabilitats predites de tenir almenys una dona ministra per a un país amb un PIB per càpita determinat. Per veure alguns exemples, farem diverses proves, en funció de si el país té un PIB baix (5.000$) o elevat (40.000$). (És important recordar que la variable gdpcap està indicada en milers de dòlars.)
# PIB baix
logit_inv(0.280654 + 5 * 0.050277)
## [1] 0.6299586
# PIB elevat
logit_inv(0.280654 + 40 * 0.050277)
## [1] 0.9081901Podem observar que la probabilitat predita d’observar una dona al govern varia segons el nivell de desenvolupament econòmic d’un país. En un país amb un PIB per càpita baix, la probabilitat predita que hi hagi almenys una ministra és pràcticament del 63%. En canvi, en un país amb un nivell de riquesa elevat la probabilitat predita és de gairebé el 91%.
Per calcular un indicador similar a R2, haurem d’utilitzar aquest codi, on utilitzem la informació que queda guardada a dins de l’objecte model_glm. Com veiem, el coeficient de determinació és de 0.04.
1 - model_glm$deviance / model_glm$null.deviance
## [1] 0.0395517
Solució a l’exercici
El país amb un major nombre de militars al govern és Myanmar (Burma) l’any 1998. Si ho mirem en termes relatius, hi ha diversos països (Benín, Bolívia, Níger, Perú o Singapur) que han experimentat amb governs conformats plenament per militars en diferents moments al llarg del temps.
# Valors absoluts
whogov |> select(c(country_name,year,n_militarytitle_minister)) |> arrange(desc(n_militarytitle_minister)) |> head()
# Valors relatius
whogov |>
mutate(mil_perc = n_militarytitle_minister/n_minister*100) |>
select(c(country_name,year,mil_perc)) |> arrange(desc(mil_perc)) |>
head(n = 40)En el model observem que hi ha una relació negativa i significativa entre el nombre de ministres militars i el fet que aquests convisquin amb alguna ministra en el mateix gabinet.
Quan visualitzem les dades en un gràfic, ja observem que la corba canvia de sentit ja que la relació és negativa i abasta un rang de probabilitats més alt, que oscil·la entre el 0.64 i el 0.
whogov |>
ggplot(aes(x = n_militarytitle_minister, y = female_minister)) +
geom_point() +
geom_smooth(method="glm", method.args = list(family = "binomial"))+
labs(x ="Military ministers", y = "Probability of female minister")Adaptem el codi anterior amb els coeficients del model i veiem que les probabilitats predites que hi hagi una dona al govern quan hi ha 5 ministres militars són del 45.46%.
logit_inv(0.6385 + 5 * (-0.16413))