4 Modelar
4.1 Introducció
Una de les virtuts més importants de les dades és la seva capacitat per generar prediccions. Intentar predir coses que desconeixem és una part inherent del nostre dia a dia. Els meteoròlegs s’esforcen a encertar les seves previsions del temps utilitzant dades com la pressió atmosfèrica, la temperatura i la direcció del vent, així com l’observació visual dels patrons de núvols. Quan les Nacions Unides fa projeccions de població per al 2050, es basa en dades actuals i històriques de fertilitat, mortalitat o migracions, i també en d’altres variables demogràfiques. De manera similar, el Banc Mundial genera informes sobre les perspectives econòmiques mundials a partir de dades facilitades per les oficines d’estadística dels Estats, com és el PIB, la inflació, l’ocupació, els fluxos de capital, o informació diversa relacionada amb riscos geopolítics.
Els instruments que utilitzem per realitzar aquestes prediccions també poden servir per entendre millor fenòmens actuals que no coneixem (o que no coneixem prou). Per exemple, es poden fer servir les dades per entendre per què els conflictes han sigut més freqüents en certs contextos o períodes temporals, o quins factors estan associats a majors o menors taxes de suport a certs candidats polítics. Entendre millor per què ha passat un determinat fenomen en el passat ens pot ajudar a predir millor quan tornarà a passar, però també és útil per dissenyar noves polítiques públiques que incideixin sobre un determinat fenomen. Posem per cas que hi ha hagut un repunt en la conflictivitat social i els models existents han mostrat que la desigualtat és un factor rellevant per explicar la conflictivitat. Aquest coneixement pot ajudar a planificar polítiques públiques que es focalitzin a mitigar la desigualtat com a eina per prevenir la conflictivitat social.
Per generar aquestes prediccions, necessitem principalment dos elements: en primer lloc, és necessari disposar d’algun paràmetre (alguna dada) que proporcioni informació rellevant sobre allò que es vol predir. I, en segon lloc, és necessari tenir un model (una fórmula matemàtica) que ens permeti transformar els paràmetres en una estimació.
En aquest capítol, aprendrem a crear un model senzill. Per fer-ho, utilitzarem dades de l’Índex de Desenvolupament Humà (IDH) i del percentatge d’usuaris d’Internet a cada país. Les dades de l’IDH tenen una cobertura molt àmplia a nivell mundial, de manera que pràcticament disposem de les dades de tots els països. En canvi, la informació sobre el percentatge d’usuaris d’Internet és més limitada, ja que existeixen alguns països dels quals no disposem de dades. Si creem un model que ens relacioni aquests dos paràmetres, però, podrem estimar el percentatge d’usuaris d’Internet dels països que no tenim dades a partir de les dades de l’IDH.
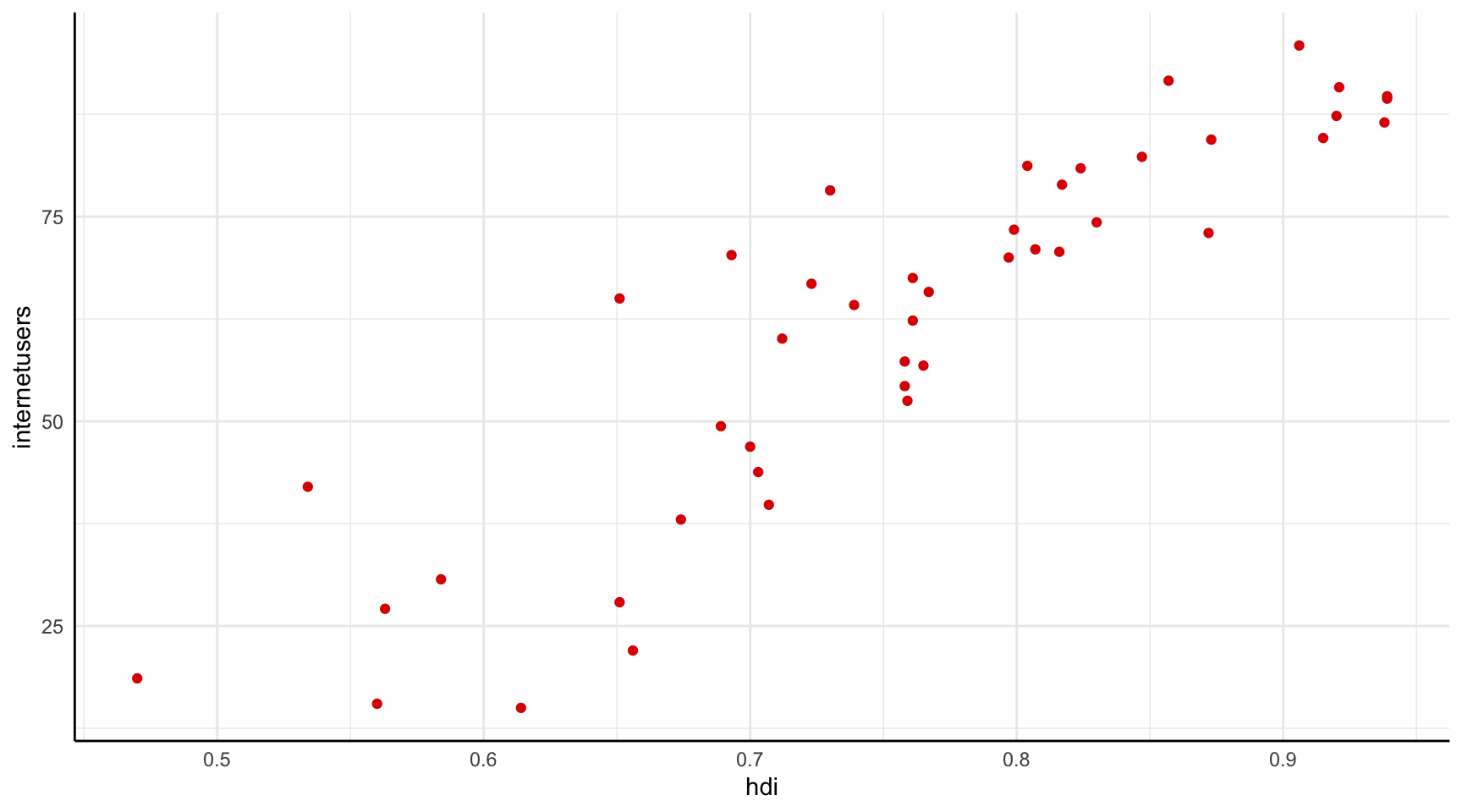
A la figura 4.1 mostrem la relació entre aquestes dues variables en un diagrama de dispersió. Habitualment posarem la variable que utilitzarem per fer la predicció (hdi) a l’eix de les \(x\) i la variable que volem predir a l’eix de les \(y\) (internetusers).
Amb els instruments d’inferència estadística que hem après, ja podem extreure algunes conclusions d’aquest gràfic. Per una banda, podem afirmar que hi ha una relació forta entre les variables. Probablement el coeficient de correlació se situarà al voltant de 0.9, cosa que implica que l’R2 se situarà aproximadament al 0.8. Aquesta informació és important, pel fet que ens indica que la primera variable és capaç d’explicar una part considerable de la segona variable, la qual cosa ja ens apunta que el model que podrem crear a partir de les dades de l’IDH ens permetran tenir una estimació prou acurada del percentatge d’usuaris d’Internet. D’altra banda, també podem concloure que la direcció de la relació entre les variables és positiva, tal com indica la direcció ascendent dels punts.
El què també podem fer amb aquestes dades és crear un model que permeti estimar el percentatge d’usuaris d’Internet utilitzant les dades de l’IDH. Farem servir una tècnica coneguda com a regressió OLS (Ordinary Least Squares, que en català es denomina mínims quadrats ordinaris).
4.2 Mètode dels mínims quadrats ordinaris
La regressió OLS és una tècnica que ens permet resumir i analitzar la relació entre dues variables utilitzant una línia recta. El seu nom prové de la seva característica fonamental, que consisteix a minimitzar la suma de les distàncies al quadrat entre aquesta línia i els punts de les dades (d’aquí el terme “mínims quadrats ordinaris”). Això implica que, de totes les rectes possibles que podríem dibuixar en un gràfic, la línia OLS és la que millor s’ajusta als punts en termes de promig, per tant, qualsevol altra recta que intentem traçar s’hi ajustarà pitjor.
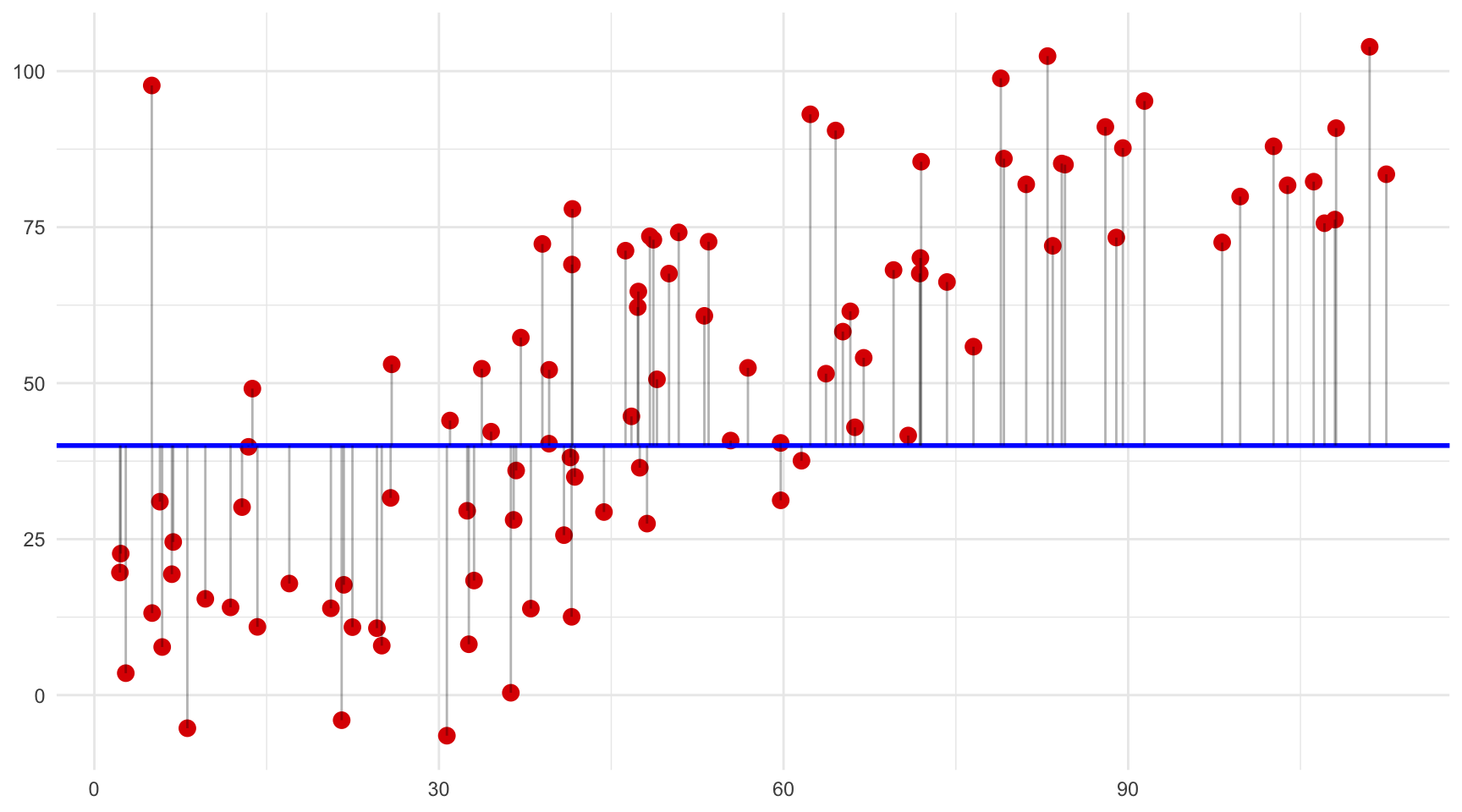
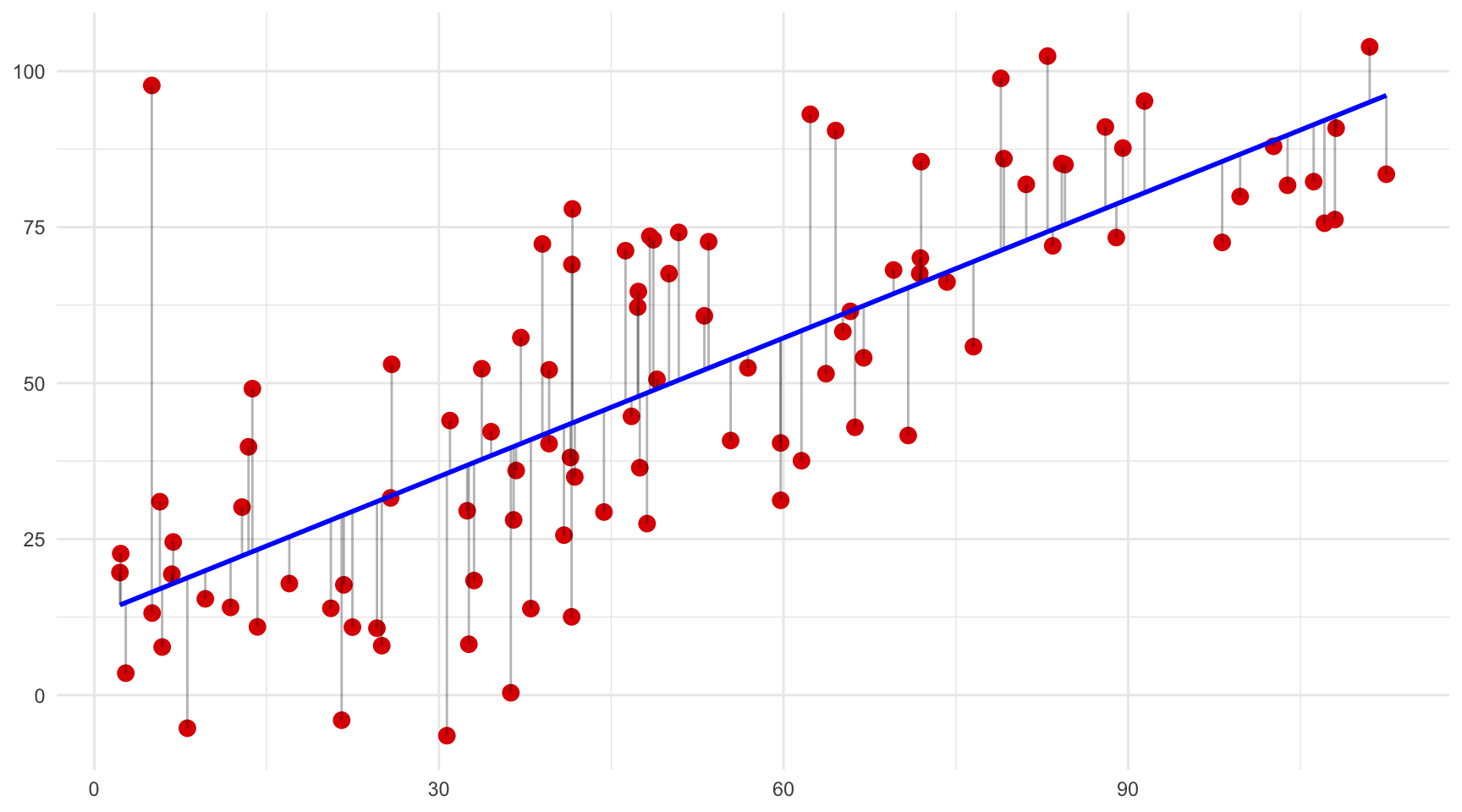
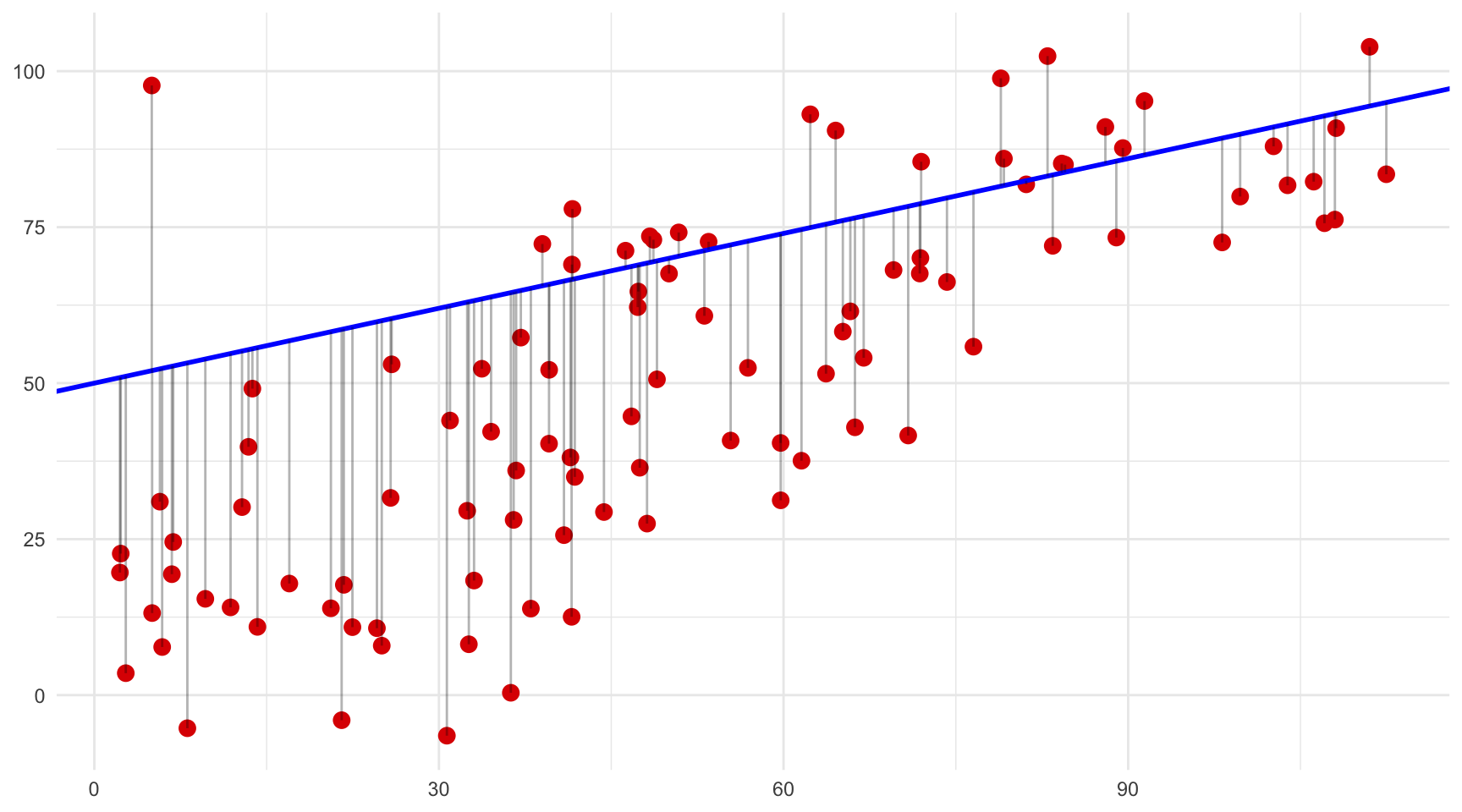
Per tal de comprendre millor aquesta propietat fonamental de la regressió OLS, a la figura 4.2 hem reproduït la mateixa relació entre dues variables quatre vegades. A cada diagrama de dispersió, hem dibuixat una línia recta diferent i unes línies grises que indiquen la distància vertical entre cada punt i la línia recta corresponent. Si observem atentament cada gràfic, és evident que les distàncies verticals entre la línia i els punts tenen longituds diferents a cada gràfic. I si calculéssim la suma dels quadrats d’aquestes distàncies, veuríem que només una d’elles és la que minimitza aquesta distància, que és la línia OLS1. Sabríeu endevinar quina és?
1 Amb paciència podríem calcular la distància vertical entre cada un dels punts i la línia blava. No obstant això, amb una aproximació visual ja és suficient per esbrinar quina d’elles és la línia OLS.
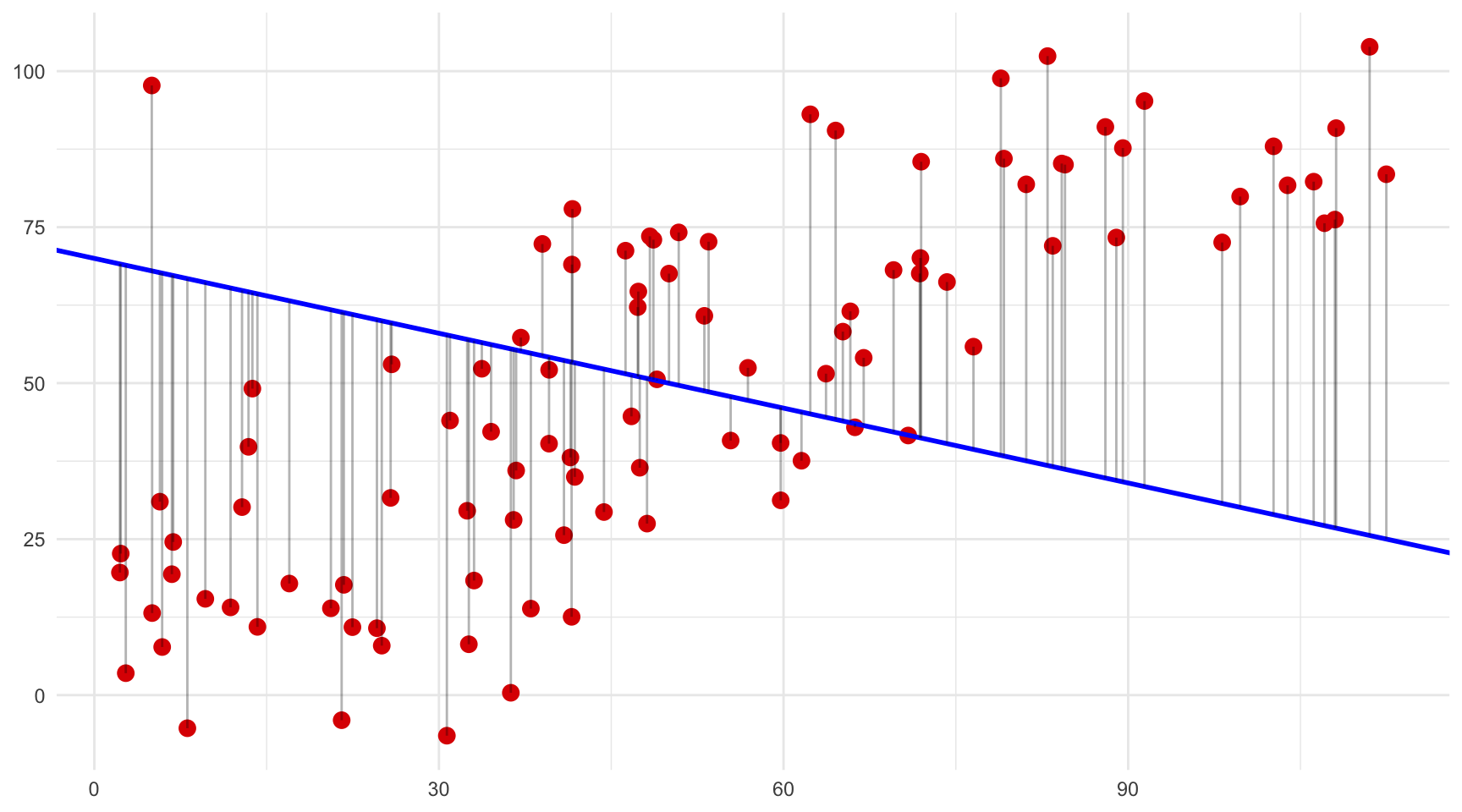
Solució de l’exercici.
Línia B.
Així doncs, la línia OLS és la línia recta que millor s’ajusta als punts de les dades. Ara que ja sabem que podem dibuixar-la en un gràfic, el pròxim pas és transformar aquesta línia en informació quantitativa que resulti útil per fer prediccions. A l’hora de representar una línia recta en un gràfic, sempre són necessaris dos elements:
- La constant (o intercept), que ens indica en quin punt la línia passa per l’eix de les \(y\). És a dir, quin valor pren la variable \(y\) quan \(x\) és zero.
- El pendent (o slope), que ens indica la magnitud en què augmenta la variable \(y\) quan incrementem la variable \(x\) en una unitat.
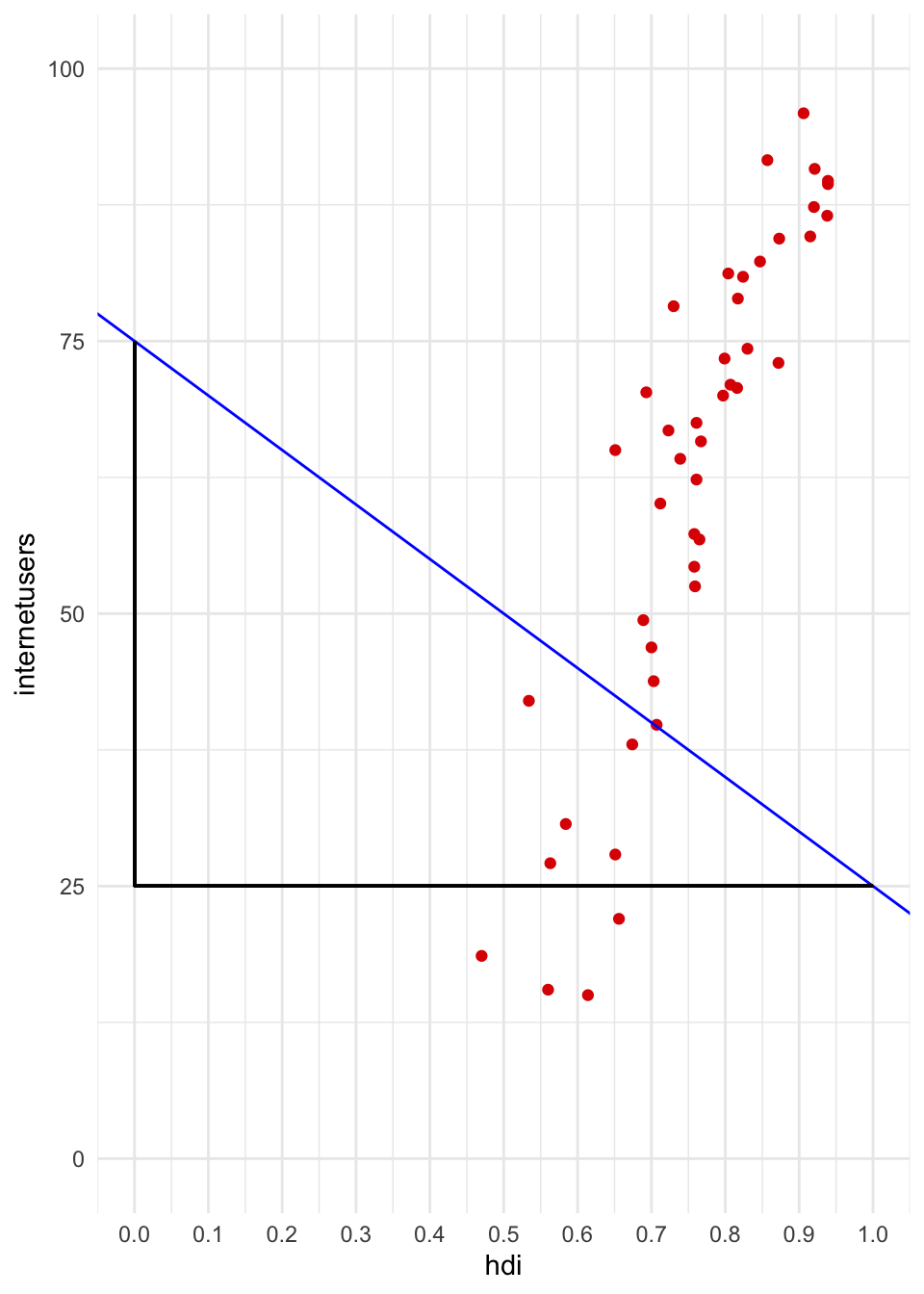
A continuació, dibuixarem una línia que podria resumir la relació entre l’IDH i el percentatge d’usuaris d’Internet a partir de la constant i la inclinació o pendent (figura 4.4). Per crear-la, hem utilitzat la geometria geom_abline(), s’ha indicat com a argument intercept el valor 75 i com a argument slope el valor -50. Això implica que, quan la \(x\) és zero, la línia passa pel valor 75 en l’eix de les \(y\), i quan \(x\) incrementa en una unitat, \(y\) disminueix en 50 unitats. A la figura 4.3, es pot veure exactament la mateixa línia recta més ampliada. Al gràfic es constata que quan l’IDH és zero, la línia se situa en el valor 75 de l’eix de les \(y\). A més, la línia té una direcció descendent, de manera que quan arriba al valor 1 de l’IDH, ha disminuït 50 punts en l’eix de les \(y\), ja que ha passat del valor 75 al valor 25. Evidentment, aquesta no és la línia OLS, per la qual cosa per descobrir quina és haureu de fer l’exercici següent.
Gràfic a escala
Mostra codi
wvs_aggr |>
ggplot(aes(x = hdi, y = internetusers)) +
geom_point(col = "#DE0100") +
scale_x_continuous(n.breaks = 10) +
geom_abline(intercept = 75 , slope = -50, col = "blue")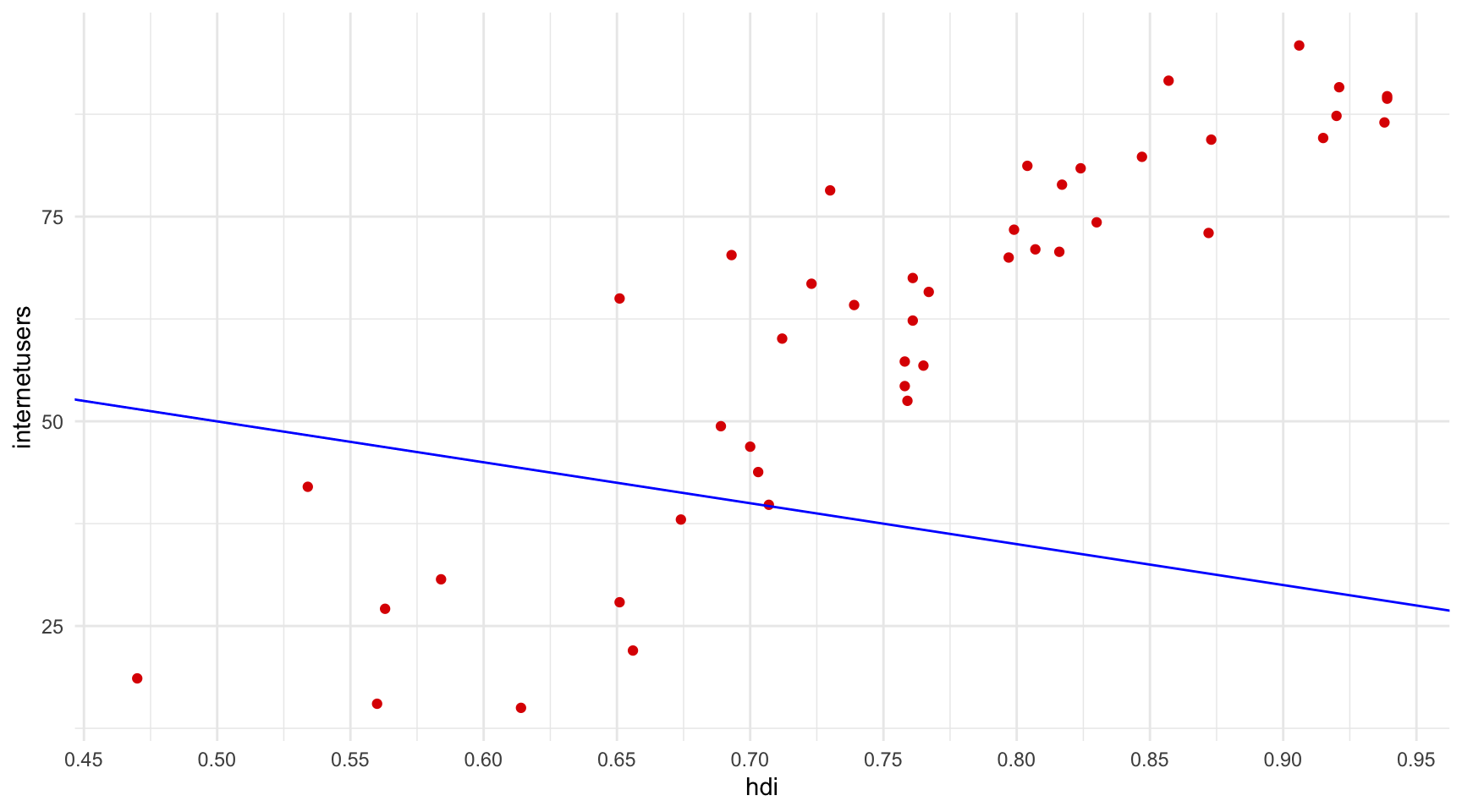
Solució a l’exercici.
La recta que millor s’ajusta als punts té les següents propietats:
- Intercept:
-70.87 - Pendent:
175.43
Més endavant coneixerem les funcions que permeten crear una línia de regressió a partir de diversos punts de dades. El què és important d’aquest apartat és haver comprovat com la regressió OLS ens permet analitzar la relació entre dues variables mitjançant una línia recta que és la que millor s’ajusta als punts observats d’entre totes les línies possibles que podem imaginar. Tanmateix, és important recordar que la forma de la relació pot ser més complexa que una simple línia recta. En aquests casos, altres models més avançats seran més adequats per capturar aquestes relacions no lineals.
4.3 Model de regressió
La informació sobre la constant i la pendent de la recta ens proporciona els elements necessaris per crear un model predictiu que ens permeti estimar el valor d’una variable en base al valor de l’altra. Aquest model es coneix com el model de regressió i normalment ve expressat amb l’equació matemàtica següent:
\[ y = \beta_0 + \beta_1 X_1 + \varepsilon \]
On, \(y\) representa el valor que volem estimar, \(\beta_0\) és la constant, \(\beta_1\) la pendent, \(X_1\) representa el valor de la variable \(x\) i \(\varepsilon\) és l’error, que captura la variabilitat no explicada en \(y\) (vindria a representar les línies verticals grises anomenades “residus”, que observàvem a la figura 4.2). Així doncs, si reprenem la solució de l’exemple anterior, la fórmula matemàtica es podria expressar de la següent manera:
\[ y = -70.87 + 175.43 * X_1 + \varepsilon \]
Per mitjà d’aquest model, ara podem predir el valor que prendrà \(y\) si coneixem els valors de \(x\). Amb altres paraules, si disposem d’informació sobre l’IDH d’un país, podem estimar el percentatge d’usuaris que tindrà accés a Internet. Per exemple, si utilitzem l’equació anterior, podem fer una estimació per a un país amb un IDH de 0.75. Només caldrà substituir \(X_1\) per 0.75.
usuaris_predits <- -70.87 + 175.43 * 0.75
usuaris_predits
## [1] 60.7025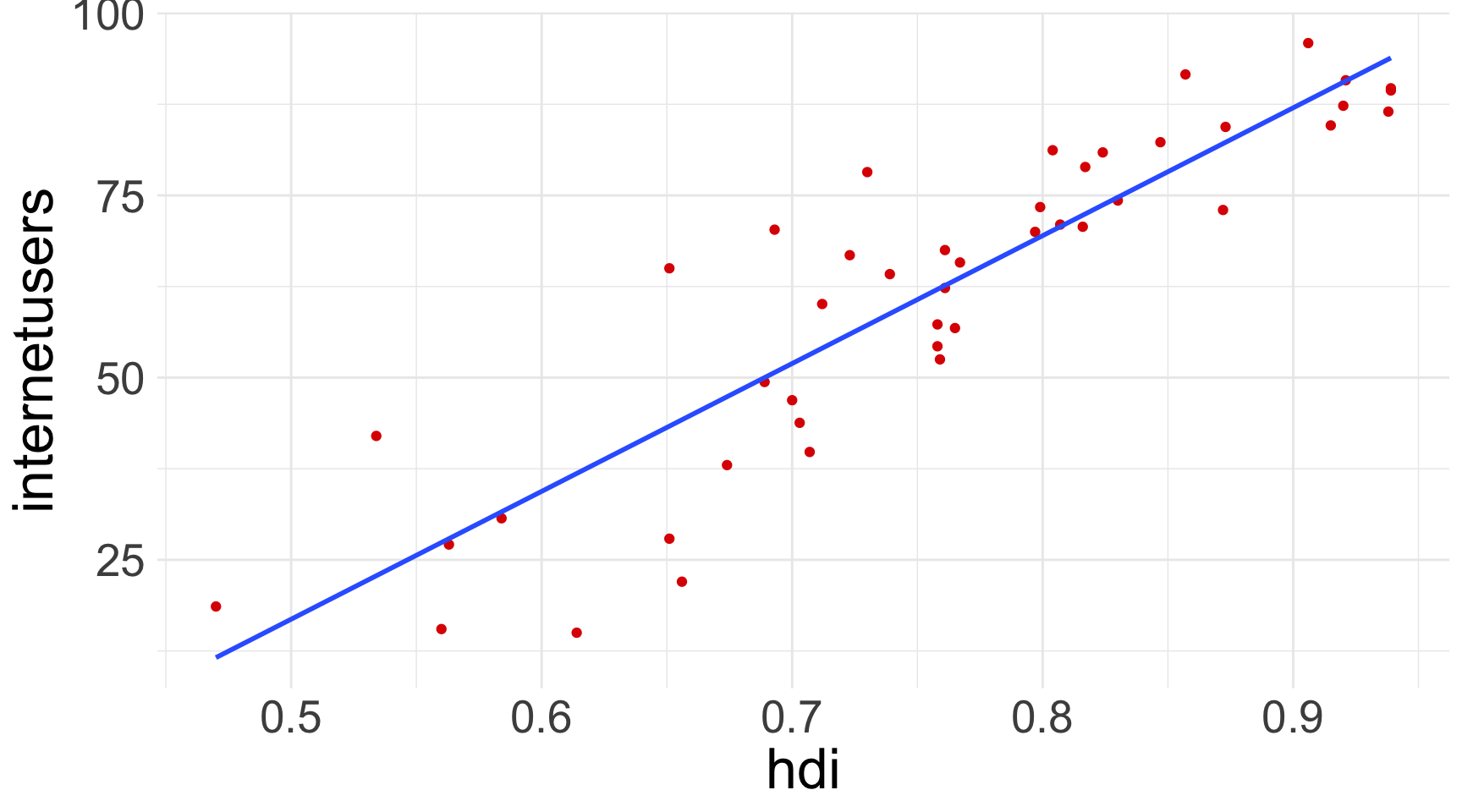
Hem estimat que un 60.8% de la població serà usuària d’Internet en un país amb un IDH de 0.75. L’estimació també es pot fer visualment si observem la recta de regressió OLS (veure figura 4.5). Aquesta observació es pot complementar amb l’R2 del model que, sense haver-lo calculat, ja intuïm que estarà al voltant del 80%. Si tenim en compte aquest coeficient, podem esperar que la capacitat predictiva del model serà força elevada.
4.4 Models no lineals
Com hem anat aprenent al llarg d’aquest mòdul, en algunes ocasions ens trobarem amb situacions on la relació entre dues variables pot ser més complexa que una simple línia recta i, per tant, haurem d’utilitzar mètodes alternatius per a les nostres estimacions. En aquest apartat, explorarem una alternativa senzilla i repassarem alguns conceptes que s’han abordat en el mòdul, per la qual cosa servirà també com a repàs. Com a exemple, investigarem la relació entre desenvolupament econòmic i democràcia, que es mostra a la figura 4.7. Molts estudis han investigat l’associació entre aquests dos fenòmens, encara que ha estat més difícil determinar-ne la direcció causal (Barro, 1999; Boix, 2011; Przeworski et al., 2000).
En aquest apartat no entrarem a explorar la causalitat, però com a suposició inicial assumirem que és la democràcia la que causa el desenvolupament. Per aquest motiu, situarem la democràcia a l’eix de les \(x\) i el desenvolupament a l’eix de les \(y\). Les dades de democràcia s’han extret de V-Dem (Coppedge et al., 2021), mentre que pel desenvolupament hem agafat les dades del Banc Mundial de PIB per càpita. Com observem, la relació no és estrictament lineal, sinó que té una certa forma curvilínea. Això és atribuïble, en part, a que el PIB per càpita acostuma a tenir una asimetria negativa, com observem a l’histograma de la dreta (figura 11.1).
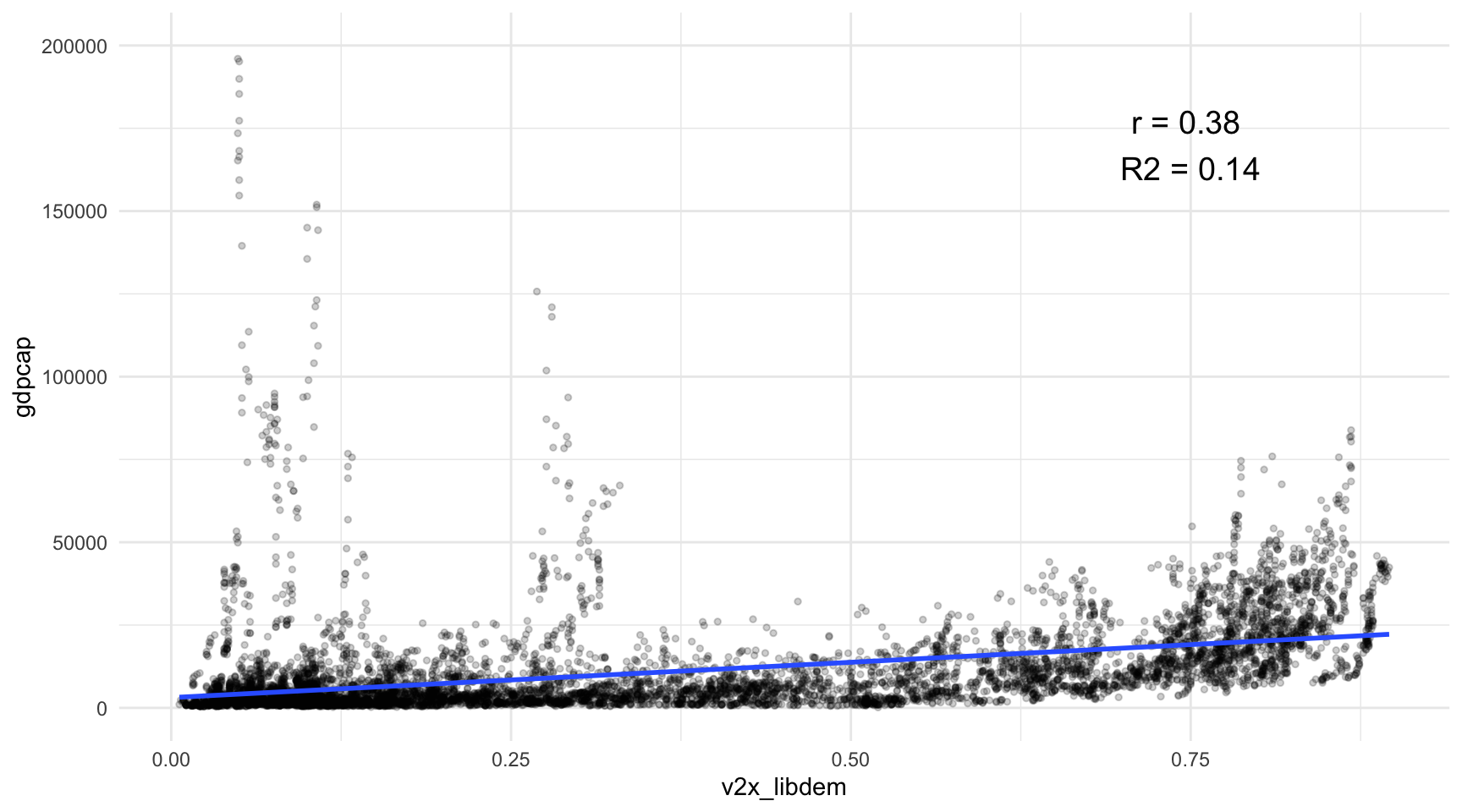
Per tal de transformar aquesta relació en una forma lineal, aplicarem una deformació a la variable que presenta asimetria negativa mitjançant el logaritme neperià2. El resultat es pot observar a la figura 4.8. És evident que aquesta transformació ha millorat significativament la bondat de l’ajustament del model. Prova d’això és que en el gràfic anterior l’R2 era de 0.14, mentre que la nova versió ha augmentat fins a 0.37.
2 A vegades, quan es volen fer servir variables que no tenen una distribució normal, s’opta per treballar amb una transformació d’aquestes variables, generalment aplicant el logaritme. Aquesta transformació no modifica el contingut de la variable original, sinó que únicament en canvia l’escala per evitar que valors extrems puguin esbiaixar els resultats. Per conèixer més detalls de la importància i l’ús adequat dels logaritmes pots consultar aquest capítol del podcast d’El Pati Descobert.
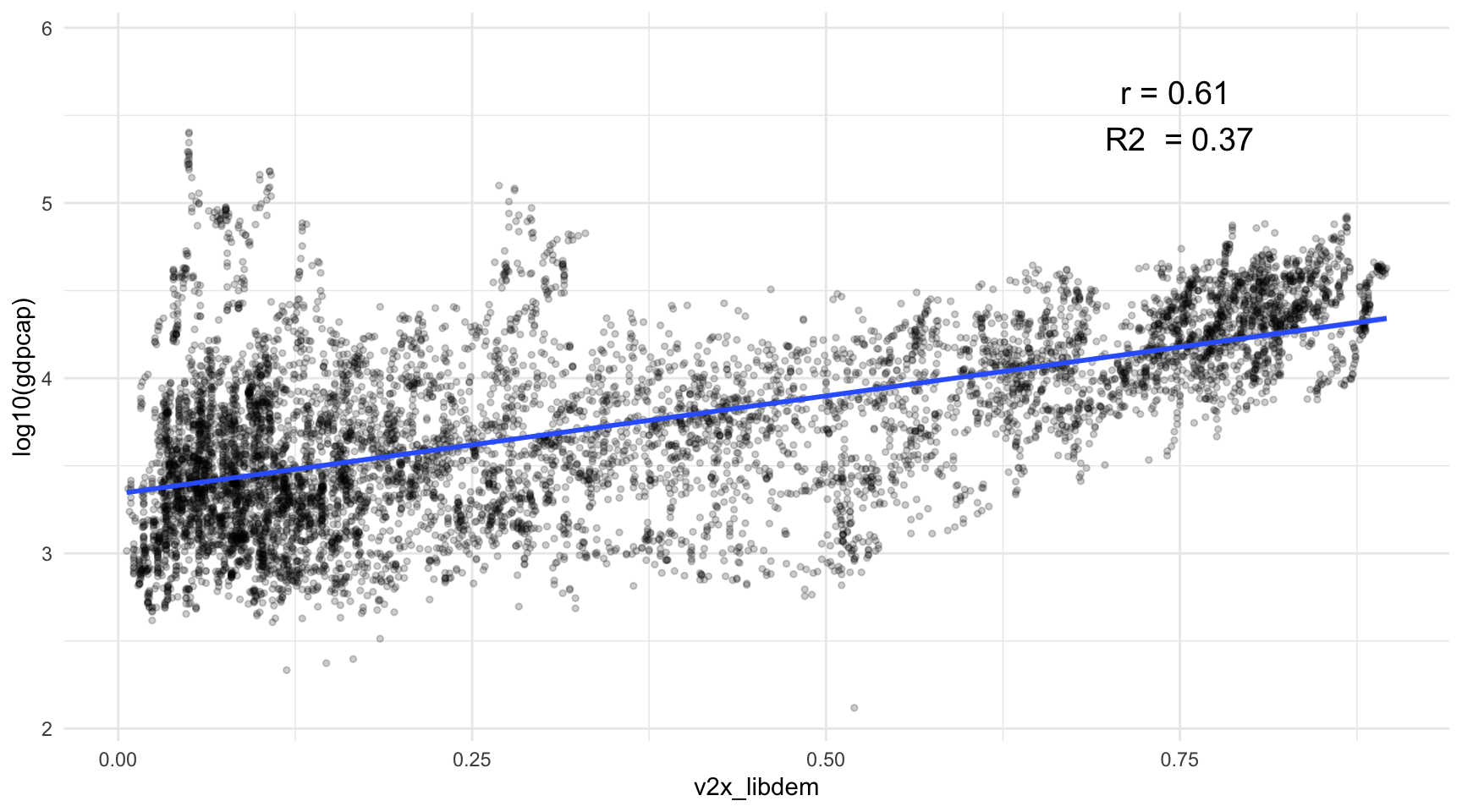
El problema de deformar les variables és que, posteriorment, s’han de restaurar a la seva forma original un cop s’ha creat el model, per així poder interpretar correctament els resultats. Fixem-nos que en el gràfic ja podem identificar que la constant està al voltant de 3.4 i que la pendent és propera a 1, perquè quan augmentem la variable \(x\) en un punt (passem del valor 0 al valor 1 de democràcia), la variable \(y\) passa de 3.4 a 4.4 (per tant, varia un punt aproximadament).
Si utilitzem tècniques estadístiques per calcular numèricament el pendent i la constant, veiem com la nostra intuïció és bona: el pendent és de 3.340607 i la constant de 1.116526. El model de regressió resultant és el següent:
\[ y = 3.340607 + 1.116526 * X_1 + \varepsilon \]
De nou, amb la informació sobre la constant i la pendent de la recta de regressió d’aquest model podrem predir el valor que prendrà \(y\) si coneixem els valors de \(x\). Per tant, podem calcular, per exemple, el nivell de desenvolupament que tindria un país que puntués 0.85 a l’índex V-Dem.
Si fem servir el model de regressió anterior, substituïm \(x\) per 0.85:
desenvolupament_predit <- 3.340607 + 1.116526 * 0.85
desenvolupament_predit
## [1] 4.289654Com podem imaginar, el resultat de 4.2896541 no és gaire intuïtiu, perquè està en escala logarítmica. Per obtenir el seu valor real, haurem de revertir el procés del logaritme, que consisteix a elevar a 10 el resultat obtingut:
10^desenvolupament_predit
## [1] 19482.92Per tant, segons aquest model, podríem predir que un país amb una puntuació de 0.85 en l’índex V-Dem tindria un PIB per càpita aproximat de 19482.92.
Solució de l’exercici
25
10
50