cor <- cor(mia_regions$delegation,
mia_regions$inception, use = "pairwise.complete.obs")
cor
## [1] 0.077148916 Independent numèrica
6.1 Introducció
Per examinar una associació on la variable independent és numèrica, és habitual utilitzar una tècnica que es coneix com la regressió. Anteriorment, ja hem vist que la línia de regressió té dues dues propietats principals. En primer lloc, és la línia que millor explica la relació entre dues variables. I, en segon lloc, ens permet crear un model que facilita l’estimació dels valors d’una variable quan coneixem els valors de l’altra. En aquest capítol, ens centrarem més en les tècniques estadístiques que s’apliquen a l’anàlisi de regressió mitjançant exemples concrets relacionats amb les Relacions Internacionals.
En funció de si la variable dependent és numèrica o categòrica, farem servir una tècnica diferent a la regressió. Si la dependent és numèrica, utilitzarem la regressió lineal, mentre que si la dependent és categòrica, farem servir la regressió logística.
En essència, els estadístics que busquem en els dos mètodes són molt semblants, per la qual ens detindrem més estona a explicar la regressió lineal i avançarem més ràpidament en l’apartat de la regressió logística. També és important recordar que aquests procediments són normalment el primer pas cap a l’anàlisi multivariada.
6.2 Regressió lineal
En una relació bivariada on les variables independent i dependent són numèriques, la tècnica principal utilitzada és la regressió lineal. Aquesta tècnica ha estat recentment utilitzada en un estudi liderat per Liesbet Hooghe et al. (2019), el qual examina els factors que expliquen perquè algunes Organitzacions Internacionals (OI) tenen més autoritat que altres. Com sabem, durant les darreres dècades els Estats han transferit part de la seva autoritat a les OIs, però ho han fet de manera diferent. Algunes OIs, com la Unió Europea, han adquirit capacitats per actuar en àmbits molt diversos, com en el de la moneda comuna, el lliure mercat, etc. I, en canvi, altres organitzacions, com l’APEC1, no han vist augmentar les seves capacitats al mateix nivell.
1 En anglès, les sigles responen a Asia-Pacific Economic Cooperation i, en català, Cooperació Econòmica de l’Àsia-Pacífic
Per estudiar l’autoritat internacional, Hooghe i altres investigadors van dividir el concepte en dues dimensions: la delegació i el pooling d’autoritat (és difícil trobar una traducció adequada de pooling)2. Cada dimensió ha estat operacionalitzada a partir d’un índex numèric que agrupa diversos indicadors en una escala de 0 a 1. En general, direm que un valor a l’índex proper a 1 indica un alt nivell de supranacionalisme, en què l’OI té un elevat grau d’autonomia i autoritat respecte als Estats membres que la conformen. En canvi, un valor proper a 0 indica un alt nivell d’intergovernamentalisme, en què els Estats tenen un control total de les organitzacions.
2 Més informació sobre delegació i pooling al capítol III. Dimensions of International Authority: Delegation and Pooling del llibre Measuring International Authority: A Postfunctionalist Theory of Governance (Hooghe et al., 2017)
| ioname | inception | delegation |
|---|---|---|
| OIF | 1970 | 0.18 |
| CAN | 1969 | 0.40 |
| AMU | 1989 | 0.20 |
| APEC | 1991 | 0.02 |
| ASEAN | 1967 | 0.25 |
| BIS | 1930 | 0.34 |
| Benelux | 1948 | 0.35 |
| CABI | 1987 | 0.10 |
En aquesta secció, analitzarem la relació que hi ha entre la delegació d’autoritat que han fet els Estats cap a una OI concreta i l’antiguïtat d’aquesta, mesurada en anys3. Per això, farem servir una versió modificada de la base de dades Measuring International Authority (MIA), que va ser utilitzada per Hooghe et al. (2017) (veure un fragment a la taula 6.1 del lateral). Podem pensar, d’acord amb les teories funcionalistes, que les OI acumulen autoritat a mesura que els seus Estats membres experimenten la necessitat funcional de cooperar per resoldre problemes comuns. Amb el pas del temps, a mesura que aquestes OIs aconsegueixen resoldre eficaçment aquests problemes, els Estats membres poden atorgar-los més autoritat perquè puguin abordar problemes més complexos. Per tant, l’autoritat d’una OI pot ser parcialment explicada pels seus anys d’antiguitat.
3 Aquesta activitat ha estat elaborada amb la col·laboració de Jofre Rocabert.
La delegació d’autoritat a les OIs.
La delegació d’autoritat és un procés molt comú en l’àmbit polític. En una democràcia, la ciutadania delega a través del vot responsabilitats polítiques als seus representants perquè prenguin decisions en nom seu. En una classe, els estudiants encomanen algunes feines als delegats, com ara parlar en nom dels estudiants, recollir propostes, assistir a reunions amb el professorat, etc.
En l’àmbit internacional, els Estats també deleguen algunes tasques a les OIs. Per exemple, a la Unió Europea ja no són els bancs centrals de cada Estat els encarregats d’imprimir monedes, sinó que aquesta tasca la fa el Banc Central Europeu. De la mateixa manera, la Comissió Europea s’encarrega de negociar els tractats de lliure comerç amb altres Estats i regions del món, en lloc que ho facin de manera individual. Hi ha moltes tasques, com la presa de decisions en determinades matèries, l’establiment de la política pressupostària o la supervisió financera, que els Estats poden acordar que ho faci una autoritat internacional en nom seu.
Després d’una primera exploració de les dades, hem comprovat que les dues variables d’interès són delegation, que ens indica els nivells de delegació de cada OI i actuarà com a variable dependent, i inception, que ens indica l’any de creació de l’OI i actuarà com a independent.
A l’hora de quantificar la força i la direcció de la relació entre delegació i antigüitat, utilitzarem la funció cor(), que ens mostra el coeficient de correlació entre les dues variables. Al primer argument, indicarem la variable dependent, al segon la variable independent i al tercer l’argument use = "pairwise.complete.obs"4. Observem que la relació entre l’antiguïtat de les OIs i el seu nivell de delegació és de 0.07 sobre 1, cosa que significa que és una correlació positiva, però pràcticament nul·la.
4 No és el cas de l’exemple, però amb dades perdudes el resultat de l’operació seria NA, ja que per defecte es calcula r de totes les observacions. Amb use = "pairwise.complete.obs" només conservem les observacions completes a l’hora de fer l’operació, per la qual cosa sempre ens retornarà un resultat.
Si elevem el coeficient de correlació al quadrat obtindrem el coeficient de determinació (R2). Com veiem, la variació en la variable independent ens explica menys d’un 1% de la variabilitat de la variable dependent.
cor^2
## [1] 0.005951954La millor manera que coneixem per visualitzar la relació entre dues variables numèriques ja sabem que és amb un diagrama de dispersió (figura 10.1). Representarem la línia OLS (Ordinary Least Squares o Mínims Quadrats Ordinaris, en català) amb la funció geom_smooth() i a dins de la funció especificarem dos arguments: el mètode de la regressió lineal (method = "lm") i si volem veure l’interval de confiança de la recta ombrejat en gris, que per defecte ens marcarà el 95%.
Mostra codi.
mia_regions |>
ggplot(aes(x = inception, y = delegation)) +
geom_point() +
geom_smooth(method = "lm", se = TRUE)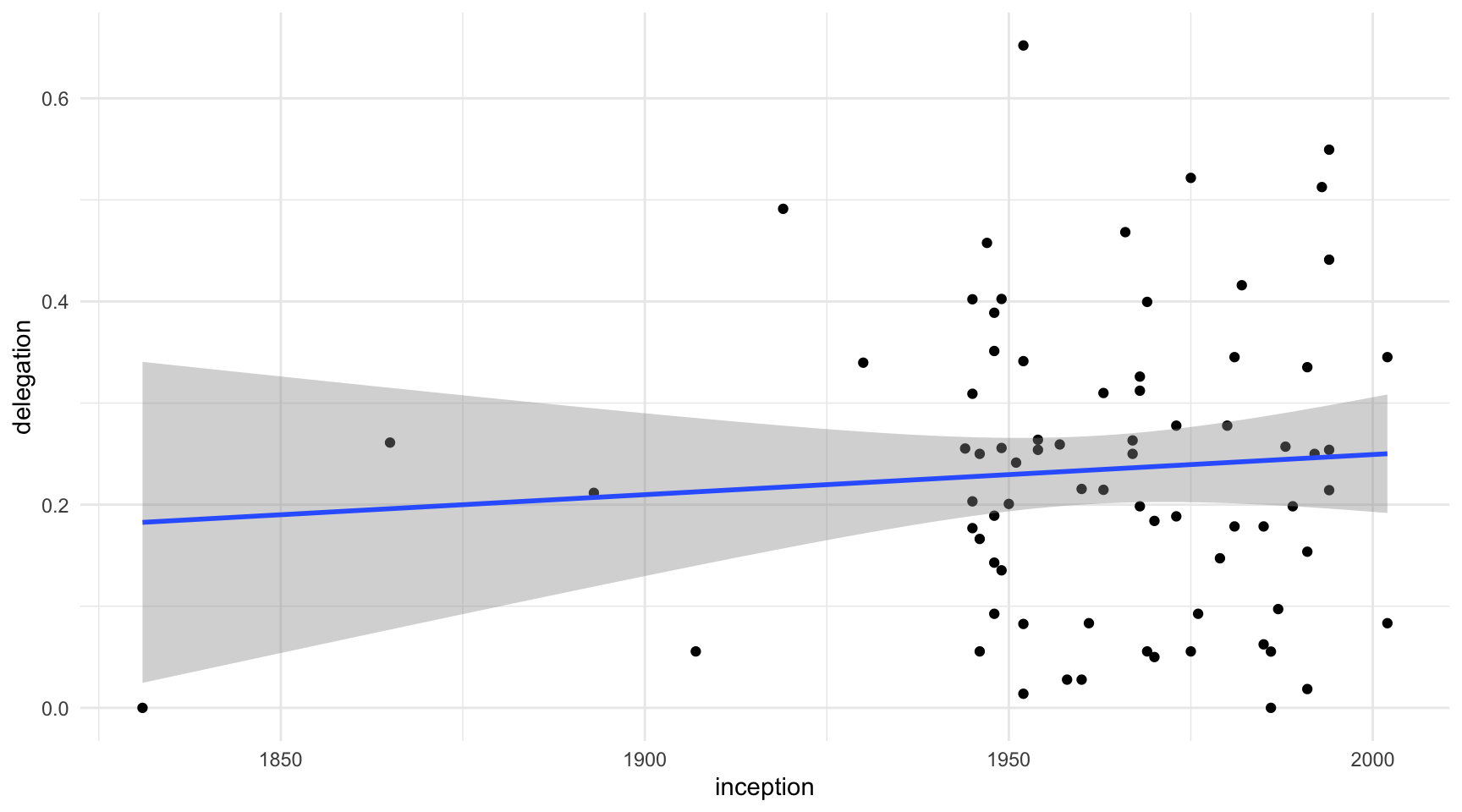
A ull, ja podem observar dues coses: que la recta és pràcticament plana i que la relació no és significativa. Sabem que la relació no és significativa perquè podem traçar una línia completament plana d’extrem a extrem del gràfic dins dels marges grisos dels intervals de confiança. Això vol dir que és possible que la pendent de la recta sigui zero. Per tant, hem d’acceptar la hipòtesi nul·la.
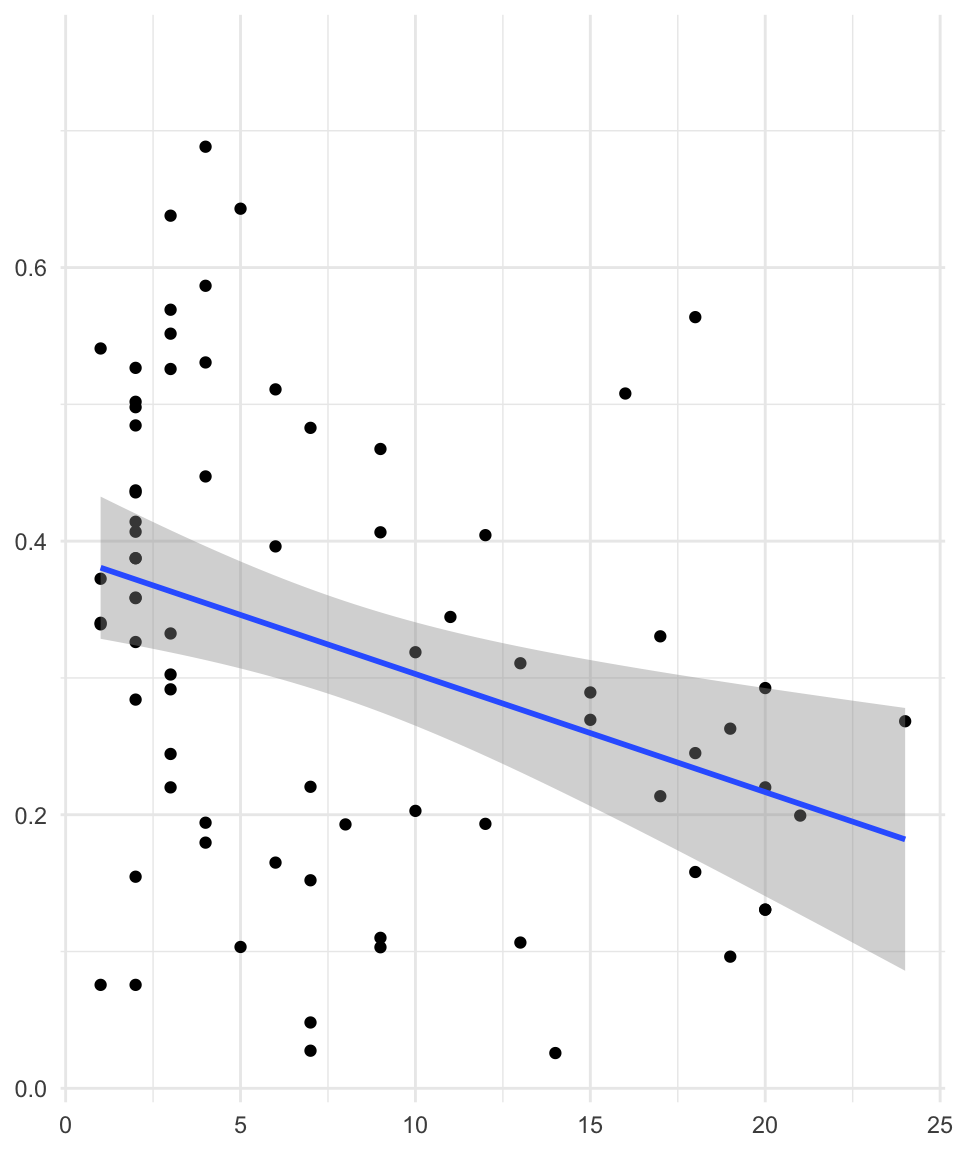
Com a exemple de relació significativa (i negativa), podem observar la figura 6.2, al marge de la dreta. Fixem-nos que, en aquest cas, no podem traçar una línia recta horitzontal d’extrem a extrem del gràfic dins dels marges de confiança marcats pels marges grisos, ja que la part inferior de l’interval de confiança a l’esquerra del gràfic està per sobre en l’eix de les \(y\) de la part superior de l’interval de confiança a la dreta del gràfic. Per tant, com que no és probable que la relació sigui 0, podríem descartar la hipòtesi nul·la.
Si tornem a les dades representades a la figura 10.1, a continuació generarem un model de regressió que expliqui la relació entre antiguitat i delegació. El model es crea amb la funció lm(), on especificarem el marc de dades que utilitzarem a l’argument data i les variables que volem incloure en el model a l’argument formula. Primer posarem la variable dependent, seguit del símbol ~ i finalment la variable independent. La informació l’hem guardat a l’objecte model_lm i hem demanat un sumari d’aquest objecte.
model_lm <- lm(data = mia_regions, formula = delegation ~ inception)
summary(model_lm)
##
## Call:
## lm(formula = delegation ~ inception, data = mia_regions)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.24381 -0.10442 0.00419 0.08940 0.42161
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.5406209 1.1640925 -0.464 0.644
## inception 0.0003950 0.0005934 0.666 0.508
##
## Residual standard error: 0.1464 on 74 degrees of freedom
## Multiple R-squared: 0.005952, Adjusted R-squared: -0.007481
## F-statistic: 0.4431 on 1 and 74 DF, p-value: 0.5077Fixem-nos en els següents paràmetres d’aquests resultats:
- A l’apartat Coefficients veiem els coeficients estimats del model (columna Estimate). A la fila de la constant (intercept), observem que la delegació hipotètica a les OI l’any zero seria de -0.54 (cal recordar que es tracta d’un model). Per cada any d’antiguitat, la variable dependent augmenta aproximadament 0.0004.
- En el mateix apartat, però a l’última columna (Pr(>|t|)), podem veure que la relació entre antiguitat i delegació no és significativa, ja que el p-valor associat és de 0.508. En termes de confiança estadística, aquest valor hauria de ser inferior a 0.05 perquè poguéssim estar segurs amb un 95% de confiança que els resultats no s’han produït per atzar.
- L’R2 del model (Multiple R-squared) és de 0.005952, el que indica que, coneixent els valors de la variable independent, no podem saber gairebé res dels valors de la variable dependent.
Malgrat que el model tingui una capacitat predictiva molt baixa, això no treu que amb els resultats de la regressió podem crear una fórmula per predir els valors de la variable delegació a partir dels valors de la variable antiguitat:
\[ delegacio = -0.5406209 + antiguitat * 0.0004 \]
Amb aquesta fórmula podem predir, per exemple, quin nivell de delegació d’autoritat tindria una OI creada l’any 1975. Com veiem, el valor seria de 0.25.
antiguitat <- 1975
-0.5406209 + antiguitat * 0.0004
## [1] 0.2493791Tanmateix, aquest és un model molt pobre, tal com ens indica l’R2. Més endavant, en l’apartat d’anàlisi multivariant intentarem millorar el model de regressió amb la incorporació de noves variables.
El pooling d’autoritat
El pooling d’autoritat es produeix quan els Estats perden la capacitat de controlar el resultat final d’una decisió. Els nivells de pooling d’una OI tendiran a 0 si totes les decisions requereixen l’aprovació dels Estats per unanimitat. En canvi, els nivells tendiran a 1 si es requereixen sistemes menys consensuals com ara la majoria simple. El pooling també inclou altres elements com, per exemple, si les decisions són d’obligat compliment o si cal ratificació posterior.
Solució de l’exercici
L’OI amb més pooling és EURAMET.
arrange(mia_regions, desc(pooling))Amb la funció cor(), demanem el coeficient de correlació, que és de -0.15. L’R2 és de 0.02.
cor <- cor(mia_regions$pooling,
mia_regions$inception, use = "pairwise.complete.obs")
cor
cor^2Visualment, observem que la relació és negativa, però no sembla que sigui significativa.
mia_regions |>
ggplot(aes(x = inception, y = pooling)) +
geom_point() +
geom_smooth(method = "lm", se = TRUE)Creem el model de regressió. A l’any 0, el pooling hipotètic de l’OI era de 2.17. Per cada any transcorregut, el pooling disminueix -0.0009387
La fórmula per predir els nivells de pooling en funció de l’antiguitat de la OI seria la següent:
\[pooling = 2.1685551 + antiguitat*-0.0009387\]
La línia LOESS
A diferència de l’OLS, que és una línia completament recta, la línia Locally Estimated Scatterplot Smoothing (LOESS) s’intenta ajustar a la distribució dels punts. Aquesta línia és especialment útil en línies temporals, pel fet que ens permet fer previsions de tendència.
Per utilitzar la línia LOESS, hem de substituir a geom_smooth() l’argument method = "lm" per l’argument method = "loess". Amb l’argument span controlem la sensibilitat de la línia. Si és més proper a 0, la sensibilitat serà més alta i la línia tindrà canvis més abruptes i, en canvi, si és més proper a 1, la línia serà més harmònica.
Mostra codi.
mia_regions |>
ggplot(aes(x = inception, y = delegation)) +
geom_point() +
geom_smooth(method = "loess", span = 0.2)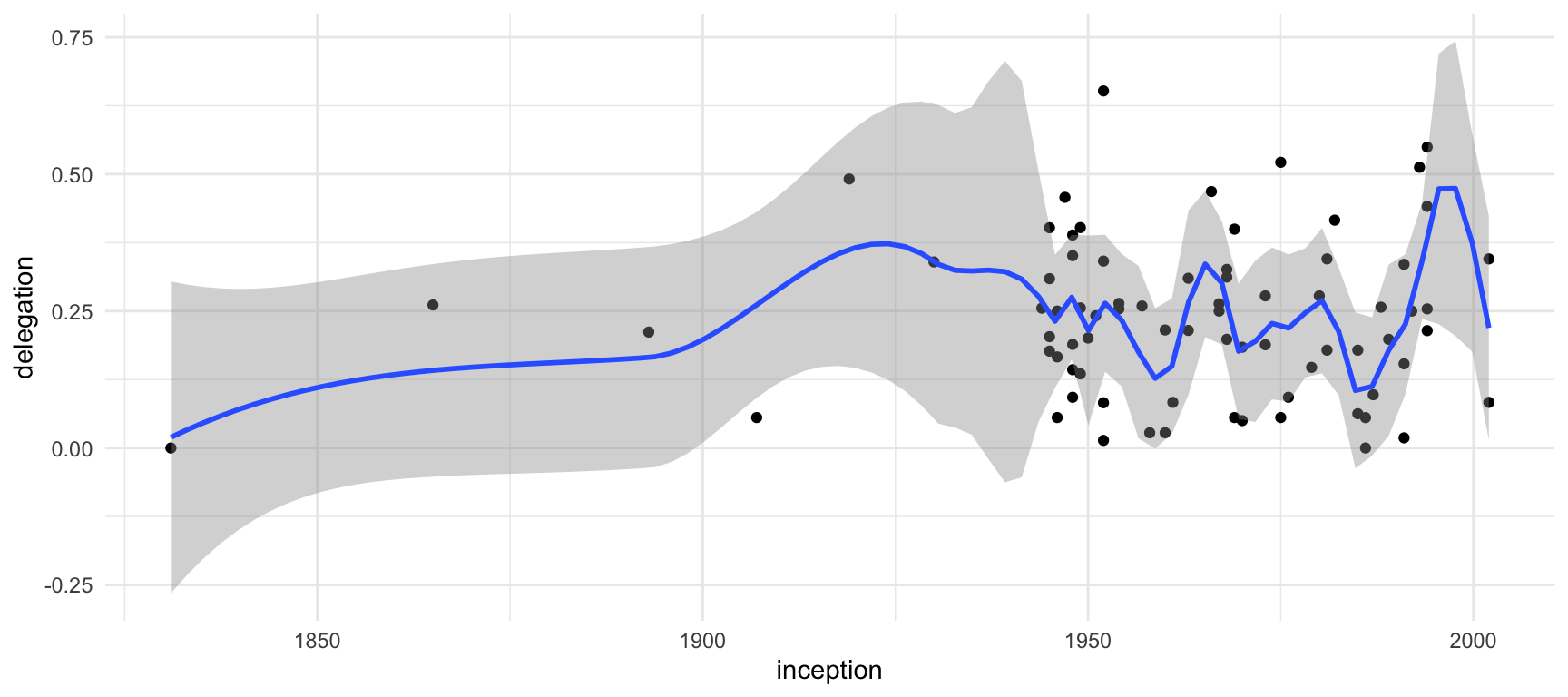
6.3 Regressió logística
A l’hora d’analitzar una relació bivariada on la variable independent és numèrica i la dependent és categòrica (concretament, binària), la tècnica estadística més utilitzada és la regressió logística5. Aquest mètode ens permet estimar les probabilitats que un esdeveniment passi o no passi a partir, en aquest cas, de dades numèriques. Com a exemple, investigarem si la diversitat ètnica d’un país influeix en la probabilitat de tenir una guerra civil. Gràcies al model de regressió logística, podrem predir la probabilitat que es produeixi una guerra civil si coneixem la diversitat ètnica del país en qüestió.
5 Si la variable dependent fos categòrica amb més de dues categories s’hauria de fer servir una regressió multinomial. Aquests models de regressió s’escapen de l’abast d’aquest curs.
Intuïtivament, podem pensar que la diversitat ètnica pot generar tensions a l’hora de compartir el poder econòmic i polític entre els grups ètnics, de manera que totes les parts considerin una repartició justa. Aquestes tensions poden arribar a tornar-se insostenibles i desembocar en una guerra civil. Això serà menys probable si un sol grup ètnic monopolitza l’Estat, però serà més probable si diversos grups ètnics de proporcions similars competeixen pel poder econòmic i polític.
| iso3c | civil_war | ethnic | oil_rents |
|---|---|---|---|
| PHL | 1 | 0.24 | 0.66 |
| CHL | 1 | 0.19 | 1.27 |
| PAK | 1 | 0.71 | 1.31 |
| BGD | 0 | 0.05 | 0.21 |
| BRA | 0 | 0.54 | 2.50 |
| ARG | 1 | 0.26 | 5.96 |
| FRA | 0 | 0.10 | 0.04 |
| GEO | 1 | 0.49 | 0.42 |
Com a variable independent, la diversitat ètnica, utilitzarem l’índex de fraccionalització ètnica (IFE) desenvolupat per Alesina et al. (2003; per altres estudis similars, veure Fearon, 2003; Fearon & Laitin, 2003; Posner, 2004), que mesura la probabilitat que dos individus seleccionats a l’atzar dins l’Estat pertanyin a grups ètnics diferents. Així, l’IFE proper a 0 indica que tota la població pertany a un sol grup ètnic, mentre que un IFE proper a 1 indica que hi ha diversos grups ètnics amb proporcions similars. Pel que fa a la variable dependent, les guerres civils, hem extret la informació de Intra-State War data set (v5.1) (Dixon & Sarkees, 2016), que és una base de dades que descriu les guerres que han tingut lloc a dins del territori reconegut d’un Estat. La variable de guerra civil es codifica a 1 si l’Estat observat ha experimentat una guerra civil des de 1965, i com a 0 si no l’ha experimentat. A la taula 6.2 del lateral es pot veure un fragment de les dades.
Mentre que la regressió lineal busca la línia més recta possible que expliqui la relació entre variables, la línia de la regressió logística no és necessàriament recta. A la figura 6.3 veiem una visualització típica d’una regressió logística amb les dades que hem descarregat. Hem posat la variable dependent ethnic a l’eix de les \(x\) i la variable independent civil_war a l’eix de les \(y\). Fixem-nos que els punts de la part inferior del gràfic mostren l’IFE de tots els països que no han patit cap conflicte civil i els punts de la part superior mostren l’IFE dels països que sí n’han patit un. La recta de regressió prediu les probabilitats de tenir una guerra civil en funció de l’IFE.
Mostra codi
ethnicwar |>
ggplot(aes(x = ethnic, y = civil_war)) +
geom_point() +
geom_smooth(method="glm", method.args = list(family = "binomial"))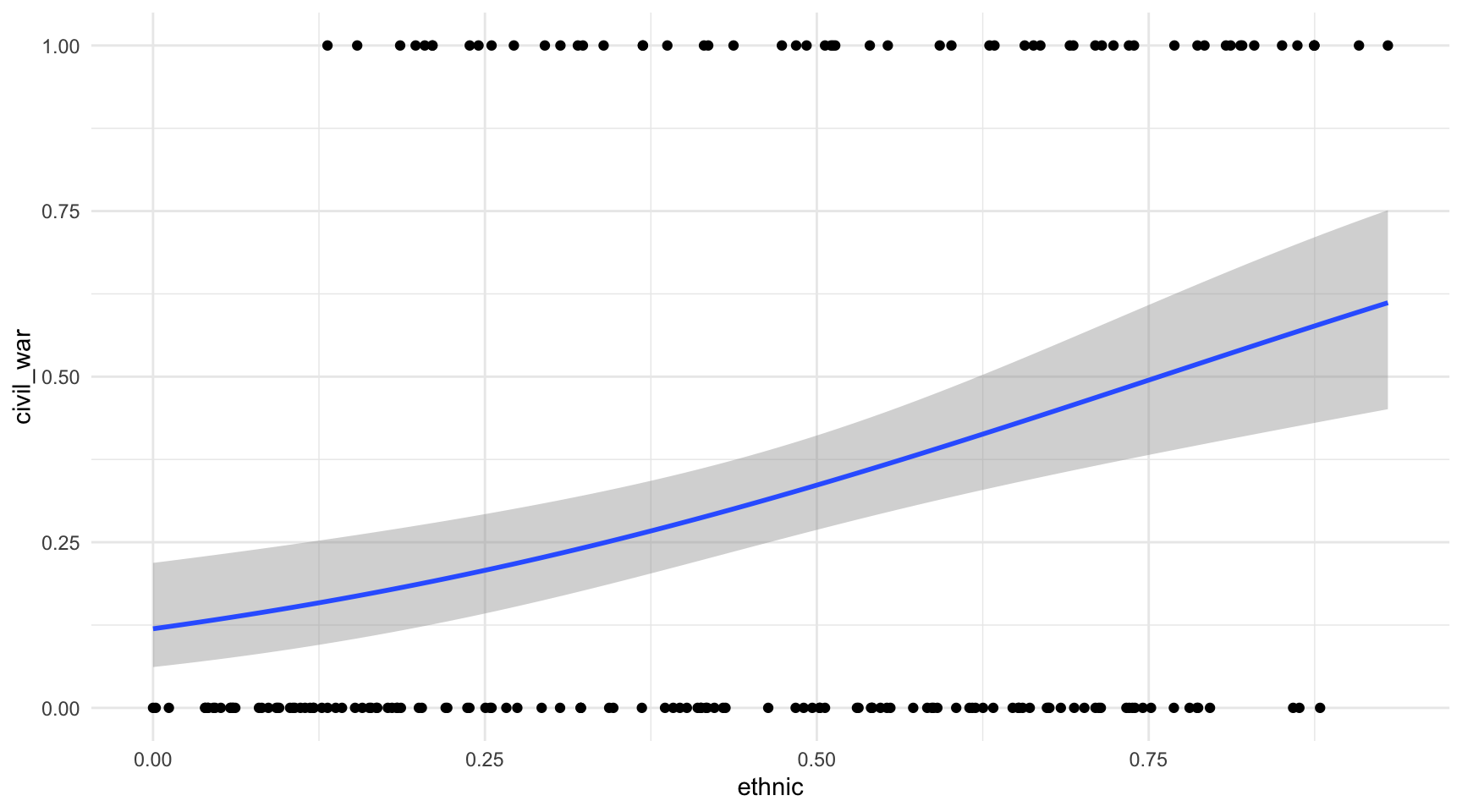
També podem calcular els coeficients de correlació i de determinació amb les funcions que ja coneixem:
cor <- cor(ethnicwar$civil_war, ethnicwar$ethnic, use = "pairwise.complete.obs")
cor
## [1] 0.2972889
cor^2
## [1] 0.08838069Ara ja podem demanar el model de regressió logística. El codi que hem de fer servir és molt semblant al que hem utilitzat a la regressió lineal, amb la diferència que emprarem la funció glm() i a dins especificarem l’argument family = "binomial".
model_glm <- glm(data = ethnicwar, formula = civil_war ~ ethnic,
family = "binomial")
summary(model_glm)
##
## Call:
## glm(formula = civil_war ~ ethnic, family = "binomial", data = ethnicwar)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.3157 -0.9114 -0.6113 1.1395 1.9116
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -1.9982 0.3703 -5.396 6.80e-08 ***
## ethnic 2.6363 0.6678 3.948 7.89e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 236.23 on 188 degrees of freedom
## Residual deviance: 219.00 on 187 degrees of freedom
## (49 observations deleted due to missingness)
## AIC: 223
##
## Number of Fisher Scoring iterations: 4En el sumari del model, ens haurem de fixar en el següent:
- El coeficient significació de la variable independent es troba a la columna Pr(>|t|). Tot i que en el gràfic ja hem vist que la relació era significativa, en els resultats observem que el p-valor és de 0.00000789, per la qual cosa podem considerar que la relació entre fraccionalització ètnica i guerra civil és significativa amb més d’un 99.9% de confiança.
- Interpretar els coeficients estimats és més complicat, perquè els coeficients del model que es troben a la columna Estimate es troben deformats per la funció logit. Per tant, per poder interpretar correctament els coeficients haurem d’invertir abans els valors amb aquesta funció:
Un cop creada la funció, ja podem aplicar-la per calcular les probabilitats predites d’haver passat per una guerra civil per a un país amb un IFE determinat. Per veure alguns exemples, farem diverses proves: el país es troba a la mitjana de la mostra si el país no té fraccionalització ètnica (0), si té molta fraccionalització ètnica (1) i si té el valor IFE.
# IFE 0
logit_inv(-1.9982 + 0 * 2.6363)
## [1] 0.119392
# IFE 1
logit_inv(-1.9982 + 1 * 2.6363)
## [1] 0.6543238
# IFE Median
logit_inv(-1.9982 + median(ethnicwar$ethnic, na.rm = T) * 2.6363)
## [1] 0.2960513Podem observar que la probabilitat predita d’haver tingut una guerra civil varia segons el nivell d’homogeneïtat ètnica d’un país. En un país amb un únic grup ètnic (IFE = 0), la probabilitat predita d’haver tingut una guerra civil és de 11.9%. En canvi, en un país amb alta fraccionalització ètnica (IFE = 1) la probabilitat predita és de 65.4%. Si considerem la fraccionalització d’un país típic, agafant la mediana de la mostra, la probabilitat predita és de 29.6%.
Per calcular un indicador similar a R2 haurem d’utilitzar aquest codi, on emprem la informació que queda guardada a dins de l’objecte model_glm. Com veiem, el coeficient de determinació és de 0.07.
1 - model_glm$deviance / model_glm$null.deviance
## [1] 0.07291034
Solució de l’exercici
El país amb més fraccionalització religiosa és Sud-àfrica.
arrange(ethnicwar, desc(religion))Al model observem que hi ha una relació positiva i significativa entre la fraccionalització religiosa i el fet d’haver experimentat una guerra civil.
Quan visualitzem les dades en un gràfic, observem que la corba és molt més pronunciada que en la relació entre fraccionalització ètnica i el fet d’haver experimentat una guerra civil.
ethnicwar |>
ggplot(aes(x = language, y = civil_war)) +
geom_point() +
geom_smooth(method="glm", method.args = list(family = "binomial"))Adaptem el codi anterior amb els coeficients del model i veiem que les probabilitats predites d’experimentar una guerra civil per a un país que la seva fraccionalització religiosa sigui igual a la mediana de la mostra és de 28%.
logit_inv(-1.7360 + mean(ethnicwar$language, na.rm = T) * 2.0690)