


Mostra codi
A més de trobar associacions entre variables i verificar si aquestes associacions passen el filtre de l’atzar, un dels objectius últims de la ciència és comprendre perquè les coses passen. Per què hi ha guerres al món? Quines són les causes de la pobresa? Lamentablement, amb els instruments de l’estadística inferencial que hem après fins ara no podem respondre directament a aquestes preguntes. Podríem observar que existeix una associació entre democràcia i desenvolupament i calcular si aquesta associació és estadísticament significativa. Però això no ens serviria per establir cap mena de causalitat1 entre aquests dos fenòmens: És la democràcia la que causa el desenvolupament o bé el desenvolupament és el que causa la democràcia? O potser hi ha una tercera variable que és la causant de les dues? Les mateixes preguntes se’ns poden plantejar en moltes altres associacions: És la pobresa la que causa els conflictes civils o són les guerres civils les que causen la pobresa? Un major poder adquisitiu fa que la població estigui més educada o bé el fet que la població rebi més educació fa que acabi tenint un major poder adquisitiu?
1 Important no confondre el terme casualitat, que hem vist en el mòdul anterior, amb el de causalitat, que veiem en aquest mòdul.
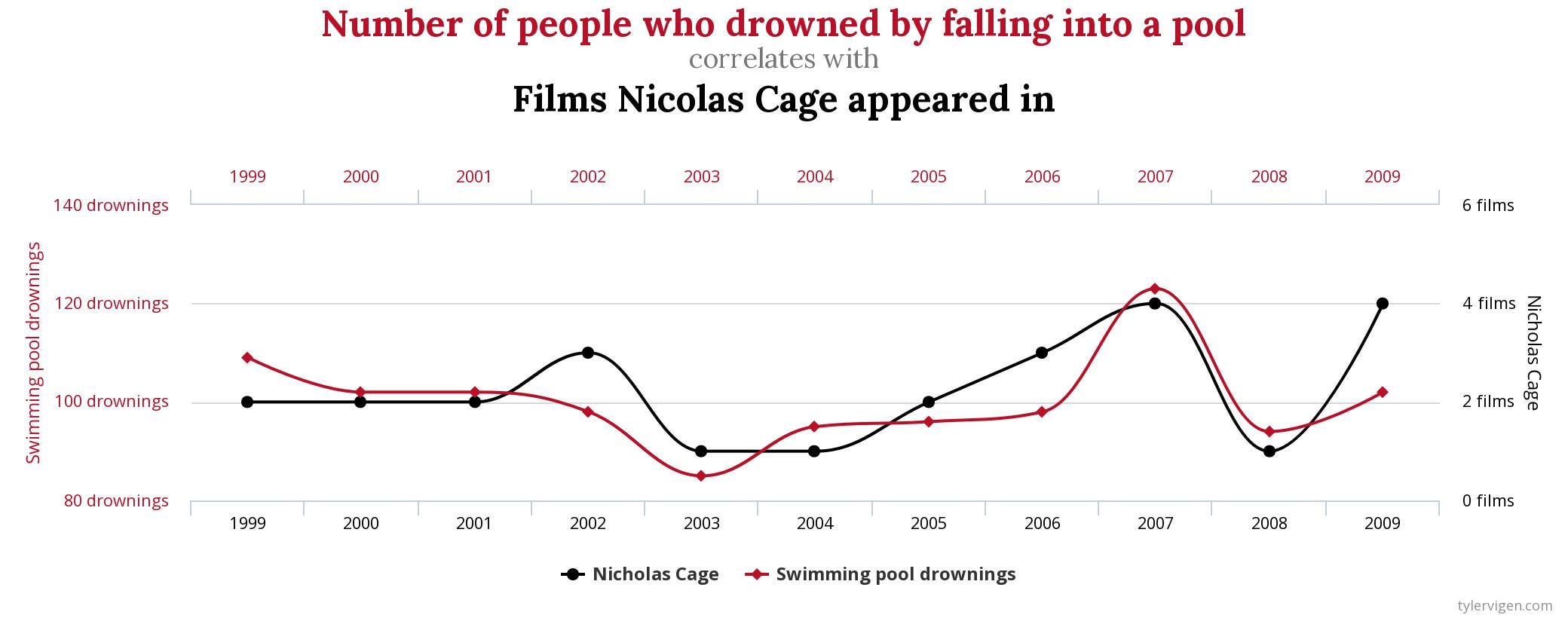
Podem identificar correlacions entre aquests fenòmens amb els instruments que hem conegut en els últims dos capítols. No obstant això, amb aquestes eines no podem establir cap mena de causalitat entre ells. A títol d’exemple, considerem les relacions de la figura 3.1. Veiem variables que estan correlacionades i que, probablement, també passarien el filtre de l’atzar2. Al gràfic de l’esquerra es pot observar una correlació negativa entre el nombre de pirates i l’escalfament global, mentre que al de la dreta es pot veure una correlació positiva entre el nombre de pel·lícules on apareixia Nicholas Cage i el nombre de persones ofegades en una piscina.
2 Es poden veure alguns altres exemples de correlacions espúries (no causals) a la web Spurious Correlations.

Font Figura 1: Wikicommons
Font Figura 2: Miro Medium
La conclusió que es pot extreure d’aquestes dues imatges és una de les màximes de l’estadística: “La correlació no implica necessàriament causalitat” (trobem, amb un toc d’humor, algunes il·lustracions més d’aquesta idea a la figura 3.2). Això significa que dues variables poden estar correlacionades i tenir una relació estadísticament significativa, però això no implica que una sigui la causa de l’altra.
Llavors, com podem saber que un fenomen està causant l’altre? La principal arma que utilitzem en el dia a dia és el sentit comú. La nostra intuïció acostuma a ser un bon aliat a l’hora d’establir o descartar causalitats: “És obvi que l’escalfament global no pot haver causat una reducció en el nombre de pirates ni que una reducció en el nombre de pirates hagi tingut res a veure amb l’escalfament global, és absurd”. Tanmateix, basar-nos únicament en el que sembla obvi pot resultar problemàtic. Històricament, la ciència ha avançat precisament en contra de les obvietats. Per exemple, durant segles es va creure que la Terra era plana fins que Aristòtil va proposar que era rodona, una idea que semblava absurda en aquell moment. De manera similar, també era obvi que el Sol girava al voltant de la Terra, fins que astrònoms com Galileo, Copèrnic i Kepler van defensar l’absurda idea que la Terra no era el centre del món. A les Ciències Socials, moltes idees absurdes ho han deixat de ser al llarg dels anys i moltes idees acceptades s’han convertit en absurdes.
Així doncs, més enllà del sentit comú necessitem que l’estadística ens ofereixi altres instruments per determinar la causalitat entre fenòmens. En cas contrari, si ho fiem tot a allò que considerem lògic pot fer que ens arrepentim d’algunes coses uns anys més tard. I, per això, en els següents apartats, haurem d’allunyar-nos del nostre sentit comú per entendre quin és el problema fonamental de la causalitat.
Què és, en primer lloc, la causalitat? Direm que “una variable causa o té efecte sobre una altra quan, modificant-ne els seus valors, estem variant els valors de l’altra” (Mesquita & Fowler, 2022). Per exemple, pensem en un fenomen molt qüotidià on podem imaginar fàcilment una relació causal: els exàmens. Podem considerar que estudiar més temps i treure bona nota en un examen són dues variables que estan associades i que, a més, la primera causa la segona: estudiar una quantitat més gran d’hores farà treure una millor nota en un examen. En termes de la definició de causalitat que acabem de presentar, direm que si modifiquem la quantitat d’hores d’estudi, també variarem (positivament) la nota de l’examen.
El problema es planteja quan intentem provar la hipòtesi de la causalitat en termes empírics. La manera ideal de testar-la seria de la següent manera: uns dies abans de l’examen, crearíem un multivers amb dues línies temporals. A la primera línia temporal estudiaríem moltes hores per l’examen, mentre que a la segona només en dedicaríem unes quantes. La única diferència entre els dos universos seria la quantitat de temps dedicat a estudiar i, com a conseqüència, el coneixement adquirit abans de l’examen. La resta de factors serien exactament els mateixos: l’examen seria a la mateixa hora, constaria de les mateixes preguntes, etc. Com que l’única diferència entre universos seria el coneixement adquirit a través de l’estudi, cap altre factor hauria influït de manera diferent en la nota de l’examen en un univers i en l’altre. Per tant, es podria afirmar que un millor resultat en el multivers on s’ha estudiat més hores seria a causa de les hores d’estudi dedicades.
Per molt inversemblant que pugui semblar la idea dels multiversos, és la millor manera que tenim de fer ciència i provar hipòtesis causals. Qualsevol altra alternativa a la de crear multiversos és menys bona, però imaginem-ne algunes. Podem posar-nos d’acord amb un company de classe i decidir estudiar un volum d’hores diferent per a l’examen, esperant que qui estudïi més hores tingui una millor nota. No obstant això, a part de les hores d’estudi hi haurà molts altres factors que seran diferents i que podran influir en els resultats, com ara les capacitats individuals de cadascú en aquesta matèria concreta o altres circumstàncies externes. Pee aquests motius, les diferències en la nota podrien venir explicades per les condicions de partida en cada cas, no pel fet d’haver estudiat més o menys hores.
Una altra possibilitat seria que féssim nosaltres mateixos el test en dos examens diferents. En un d’ells estudiem més hores, i en l’altre n’estudiem menys. Tanmateix, també ens trobem amb el mateix problema fonamental: l’examen serà diferent, la matèria serà diferent, les preguntes seran diferents, etc. Acostumem a estudiar més hores per exàmens que, d’entrada, són més difícils. I, en canvi, en exàmens que preveiem fàcils n’estudiem menys. De nou, tampoc podrem estar segurs que haver estudiat més hores causi una millor nota a l’examen3.
3 Se’ns poden acudir altres alternatives com les següents: podríem demanar al professor que ens fes dos examens, però en aquest cas tampoc el realitzaríem en les mateixes condicions. És a dir, les preguntes serien diferents i, com que no podríem fer els exàmens en el mateix moment, a l’hora de realitzar el segon tindríem un coneixement acumulat previ que d’altra manera no tindríem.
Això que acabem d’explicar és el que es coneix com el problema fonamental de la causalitat: si decidim estudiar més hores, no podem saber del cert què hagués passat si n’haguéssim estudiat menys; i si decidim estudiar menys, no sabrem del cert què hagués passat si n’haguéssim estudiat més. Això és així perquè, quan observem els resultats després d’haver modificat els valors d’una variable, perdem la possibilitat d’observar que hagués passat si no els haguéssim modificat, i viceversa. Això ens impedeix assegurar que la modificació que hem fet és la causa de la variació en els valors de l’altra variable. I si decidim modificar els valors d’una variable en objectes diferents, no sabem si les condicions de partida hauran estat les mateixes en cada cas. Així doncs, la millor opció que tenim per determinar la causalitat segueix sent la de crear multiversos.
Com heu pogut deduir mentres llegíeu l’anterior apartat, encara no és possible crear multiversos. I com que no podem crear multiversos, per establir causalitats entre fenòmens, la ciència necessita trobar altres escenaris que simulin la creació de diferents universos amb la major similitud possible. El millor escenari que la ciència ha trobat són els laboratoris, encara que allà tampoc podem crear universos paral·lels que ens permetin tractar la mateixa unitat de dues maneres diferents. El que sí que podem fer és utilitzar un nombre prou gran d’unitats i fer que totes tinguin exactament les mateixes condicions, excepte la del tractament que hi volem aplicar. Però, com ens assegurem que totes les unitats tenen les mateixes condicions de partida? Doncs novament haurem de recórrer a l’atzar, el nostre millor amic.
Suposem que volem investigar la relació causal entre dos fenòmens: el fet de tenir petroli i el conflicte civil, ja que tenim la sospita que els països que tenen petroli tenen més probabilitats d’experimentar un conflicte civil que els altres. Com a investigadors de laboratori, farem el procés d’a continuació. Anirem a la nevera del nostre laboratori i agafarem una mostra de, posem pel cas, 200 països. Aquests països presenten diferents característiques, com ara la seva mida, la ubicació geogràfica, el sistema de govern, les característiques econòmiques, entre d’altres. Tenen tants trets diferencials (com la bandera, l’àrea, la densitat de població, la massa forestal, etc.) que no sabem molt bé quins d’aquests trets poden tenir una certa influència sobre les variables amb què volem experimentar. Com sabeu, a partir de la definició de causalitat, sabrem si la variable petroli té un efecte sobre la variable conflicte civil si, al modificar-ne els valors de la primera, estem variant els valors de la segona. No obstant això, la nostra principal preocupació és que les altres característiques d’aquests països, que no ens interessen, puguin estar afectant el nostre experiment.
Com hem vist anteriorment, l’aleatorietat té unes propietats fascinants. Ara tornarem a utilitzar l’atzar per assegurar-nos que cap característica de les 200 unitats afecti als resultats de l’estudi. Amb aquest propòsit agafarem els països de la nevera i, de manera aleatòria, els assignarem a dos grups. A les 100 unitats del grup 1 (les anomenarem grup de tractament) procedirem a aplicar el tractament que ens interessa, que consisteix a ubicar-hi un jaciment de petroli a sota d’ells, mentre que a les unitats del grup 2 les deixarem sense tractament (les anomenarem grup de control), de manera que un grup de països rebrà la influència del petroli i l’altre no. Ho deixarem reposar uns anys per tal que les unitats tinguin un temps prudencial d’entrar en conflictes civils i, al cap d’un temps, mirarem el nombre de conflictes sorgits en el primer grup en relació amb el segon amb l’expectativa de trobar que, de manera significativa, els països que hem tractat amb petroli tenen un nombre més alt de conflictes que els països que hem deixat sense tractament (figura 3.3).
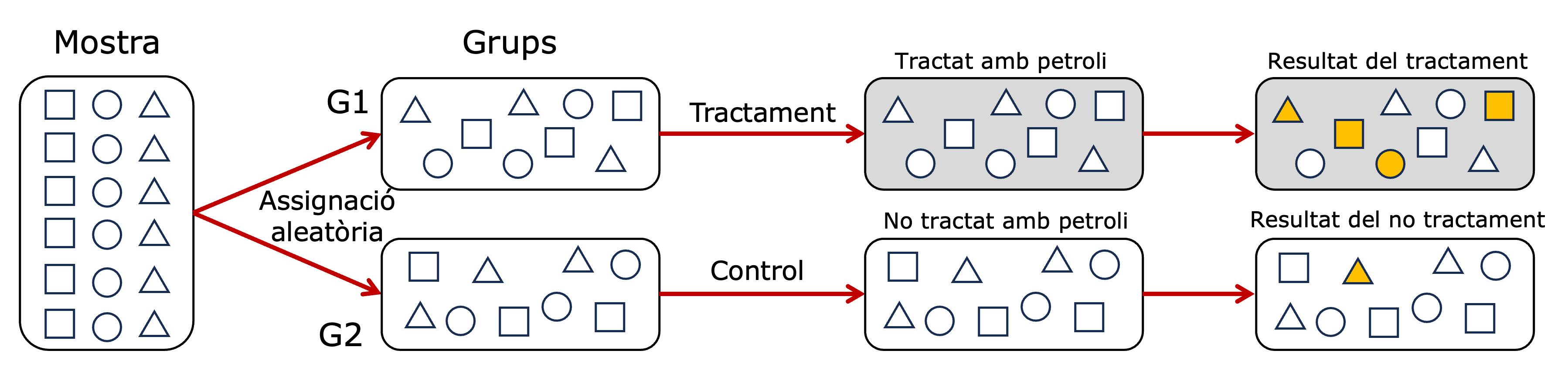
A la figura 3.3 veiem com tenim una mostra d’unitats amb característiques diferents (il·lustrades amb el quadrat, la rodona i el rombe), que randomitzem en dos grups. Al primer grup apliquem el tractament de petroli (fons gris) i a l’altre grup no li apliquem. Com a resultat, observem que hi ha més unitats al grup de tractament que experimenten conflicte civil (color groc) que no pas al grup de control.
El punt clau és que totes les característiques dels 100 països del primer grup seran, de mitjana, exactament iguals que les del segon grup. I això és així perquè les unitats han estat assignades de manera aleatòria. Gràcies l’atzar, cap variable tindrà més incidència en un grup que en un altre, excepte la variable de tractament: el petroli.
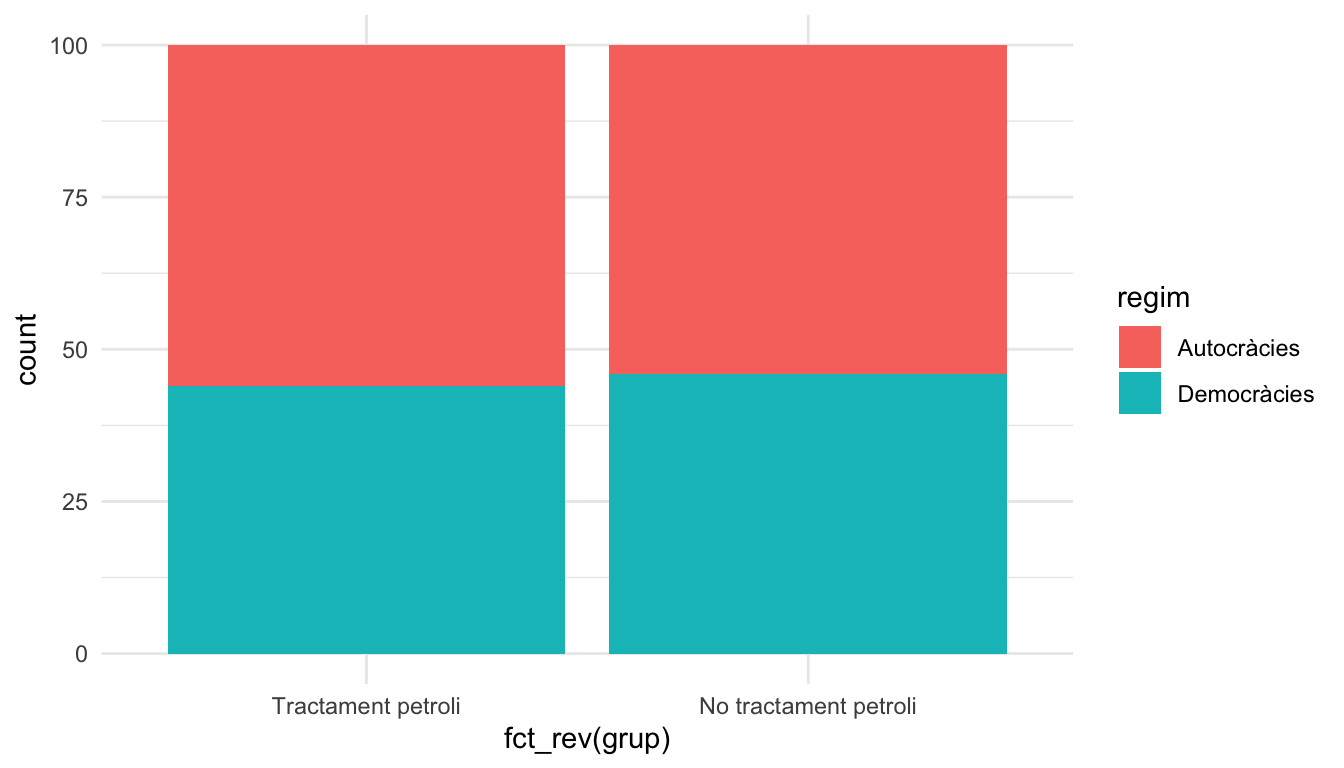
Per comprovar que això que diem és totalment cert, veurem com actua l’atzar. A la figura 3.4 hem creat una mostra de 200 països dels quals només coneixem una característica: sabem que hi ha 110 règims que són autocràtics i 90 que són democràtics. Com que no volem que el règim polític afecti als nostres resultats, haurem d’assegurar-nos que al grup tractat amb petroli hi hagi la mateixa proporció de democràcies i autocràcies que al grup de control. D’aquesta manera, eliminarem l’efecte mig del règim polític sobre les nostres unitats.
Hem demanat a l’atzar que ens distribueixi les democràcies i les autocràcies entre els dos grups. Com observem, el resultat és el següent:
Ara que ja sabem com n’és, de capritxós, l’atzar (veure figura 2.1), ja veiem que és altament probable que totes les diferències quedin repartides a parts iguals entre grups. El més important és que això serà cert tant per les característiques que coneixem (com el tipus de règim), com per les que no coneixem. Amb l’atzar no ens hem de preocupar de possibles biaixos en les dades, perquè totes les característiques quedaran repartides a parts molt semblants entre els dos grups. I això ens permet acostar-nos a la idea dels multiversos.
Farem la mateixa prova amb dades reals. A continuació, hem carregat el paquet d’R de la base de dades gapminder (Bryan, 2017), que conté variables numèriques com el PIB per càpita, l’esperança de vida o la població. Hem assignat les observacions aleatòriament en dos grups, de manera que les observacions del primer grup tindran, de mitjana, unes característiques molt semblants a les del segon grup. A la figura 3.5 podem veure el resultat de la prova amb el PIB per càpita, on efectivament podem observar que les mitjanes coincideixen. Si ara tractem el grup 1 amb petroli, i observem que, després d’un temps, hi ha hagut més conflictes en el grup 1 en comparació amb el grup 2, sabrem que el PIB per càpita no haurà tingut res a veure en el resultat, pel fet que els dos grups tenen de mitjana un nivell de desenvolupament semblant. Podem deduir, per tant, que les mitjanes també coincidirien amb qualsevol altra característica, encara que no disposem de dades per observar-la.
library(gapminder)
gapminder |>
mutate(grup_random = sample(c("1", "2"), n(), replace = T),
grup = rep(c("1", "2"), length.out = n(), each = 2)) |>
ggplot(aes(x = grup_random, y = log10(gdpPercap))) +
geom_jitter(width = 0.2, alpha = 0.1) +
stat_summary(fun.data = mean_se,
fun.args = list(mult = 1.96),
size = 0.2, colour = "red")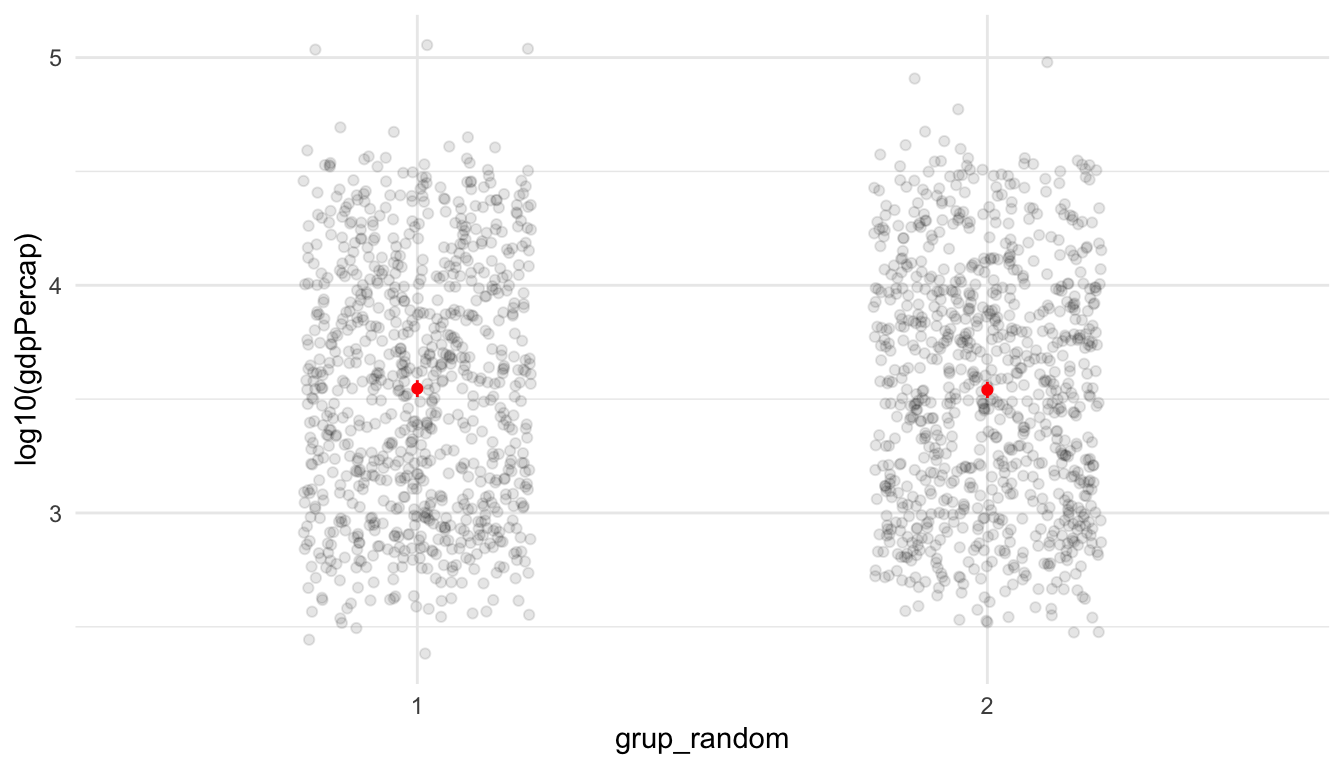
A dins de mutate() hem creat grup_random, on creem una columna en la qual assignem les files del marc de dades als grups 1 i 2 de forma aleatòria, i grup, en el qual assignem les files parelles al grup 1 i les imparelles al 2.
Per tant, en condicions ideals l’experiment amb assignació aleatòria és la manera més propera que tenim d’observar la causalitat entre dues variables. Amb la randomització del tractament podrem estar segurs que no hi haurà diferències significatives entre grups excepte per allò que volem observar. D’aquesta manera, si en el grup 1, on hem fet el tractament de petroli, observem que s’han produït més conflictes civils, podem estar segurs que aquesta variació serà causada per la presència de petroli, i no pas per l’acció d’una tercera variable, ja que totes elles han estat distribuïdes a parts iguals entre els dos grups.
Com ja heu pogut sospitar després de llegir l’anterior apartat, a les Ciències Socials, i en particular a les Relacions Internacionals, el nostre camp de treball no és exactament un laboratori. Seria ideal poder dur a terme un experiment amb 200 països, randomitzar-los en dos grups, i als d’un grup donar-los un jaciment de petroli i als de l’altre deixar-los sense jaciment. Amb aquests mètodes podríem investigar les conseqüències del petroli sense estar constantment preocupats per factors inesperats que puguin afectar la relació. No obstant això, només en situacions molt puntuals podrem fer experiments amb els nostres objectes d’estudi per inferir relacions causals. En la majoria dels casos estudiarem els fenòmens “en condicions naturals”, amb grups que tindran diferències de base més enllà de les variables de tractament, per la qual cosa haurem de pensar en altres opcions per aprendre sobre el món.
La majoria de les vegades, l’única opció que tenim és recollir dades del món real, sent conscients que poden estar subjectes a múltiples biaixos. Les característiques de les unitats que investiguem no estaran mai repartides de manera similar entre els diferents valors de la nostra variable de tractament. És molt probable, per exemple, que hi hagi més països democràtics sense jaciments de petroli, i això podria tenir algun efecte sobre la probabilitat de conflicte civil. Pot passar la mateixa situació amb el nivell de desenvolupament, i el problema més gros és que tampoc sabem al cent per cent quines altres variables poden afectar a la relació.
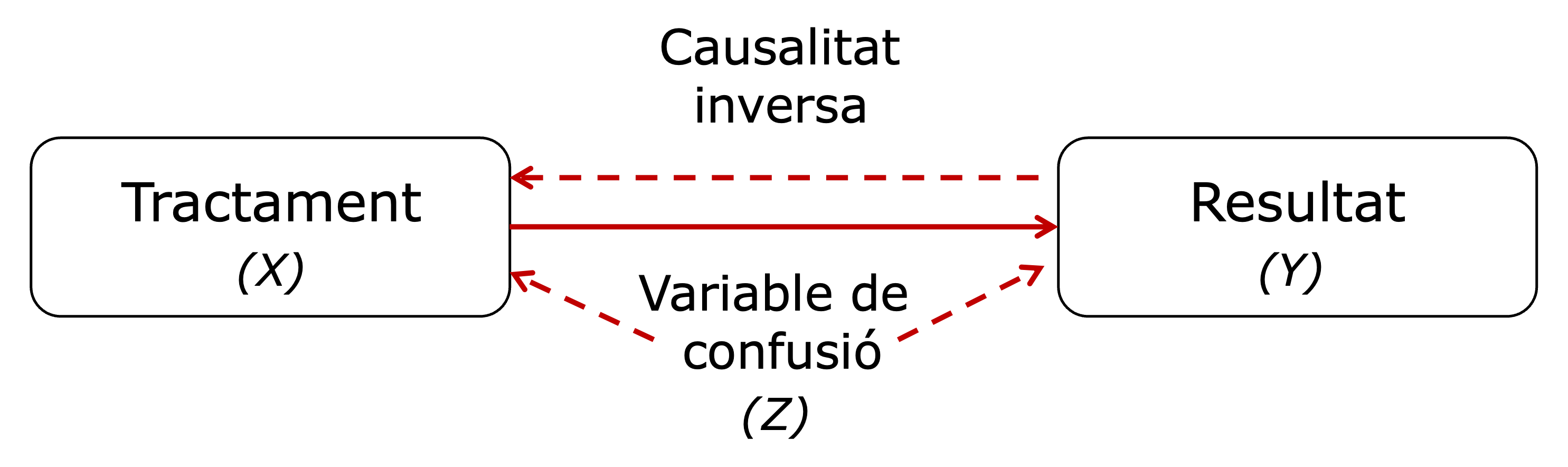
És per aquest motiu que, quan realitzem una anàlisi quantitativa no experimental, haurem de tenir present que principalment hi haurà dos elements que poden invalidar la interpretació causal que vulguem donar a una correlació (figura 3.6). En primer lloc, hem de pensar que hi pot haver diferències de base entre els grups que estem estudiant, la qual cosa pot provocar que una tercera variable estigui afectant simultàniament les dues variables que estem analitzant. En aquesta situació, el que haurem de fer és observar la relació entre les dues variables d’interès “tenint en compte” altres variables que pensem que poden afectar a la relació. A aquestes variables les anomenarem variables de confusió. En segon lloc, hem de tenir present que no sabem si la correlació existeix perquè, o bé la primera variable afecta a la segona, o bé perquè és la segona variable la que afecta a la primera. A aquest cas l’anomenarem causalitat inversa.
Aquest apartat ha estat elaborat agafant principalment com a referència el llibre Thinking Clearly with Data: A Guide to Quantitative Reasoning and Analysis (Mesquita & Fowler, 2022). És altament recomanable la seva lectura, especialment la de la Part III. Is the Relationship Causal?.
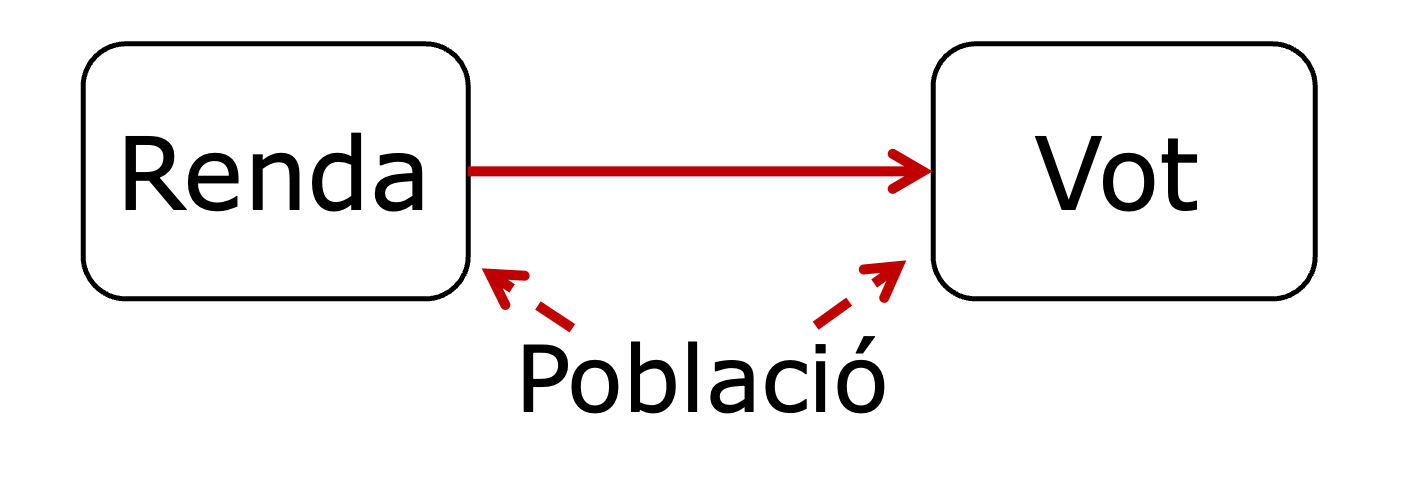
La variable de confusió (que anomenarem sovint com a \(z\)) és una característica del fenomen que estem estudiant, que influeix tant en la variable que actua com a tractament (\(x\)) com en la variable que actua com a resultat (\(y\)) (figura 3.6). Si la variable de confusió afecta a la relació entre les dues variables de l’estudi fins al punt d’eliminar-ne la correlació, direm que la relació entre \(x\) i \(y\) és una relació espúria. Vegem aquesta lògica en detall.
Suposem que volem estudiar la relació entre el desenvolupament econòmic i la guerra civil, i observem que les dues variables estan correlacionades. Sembla lògic que els països amb més dificultats per poder créixer econòmicament hagin experimentat més guerres civils. No obstant això, aquesta relació pot venir explicada, total o parcialment, per l’efecte que el tipus de règim té sobre aquestes dues variables (figura 3.7). Un règim democràtic pot incentivar el Govern a adoptar millors polítiques públiques, la qual cosa té un impacte positiu en l’economia del país. Al mateix temps, els règims democràtics ofereixen a la ciutadania mitjans no-violents per expressar els seus greuges, fet que reduirà directament el risc de guerra civil.
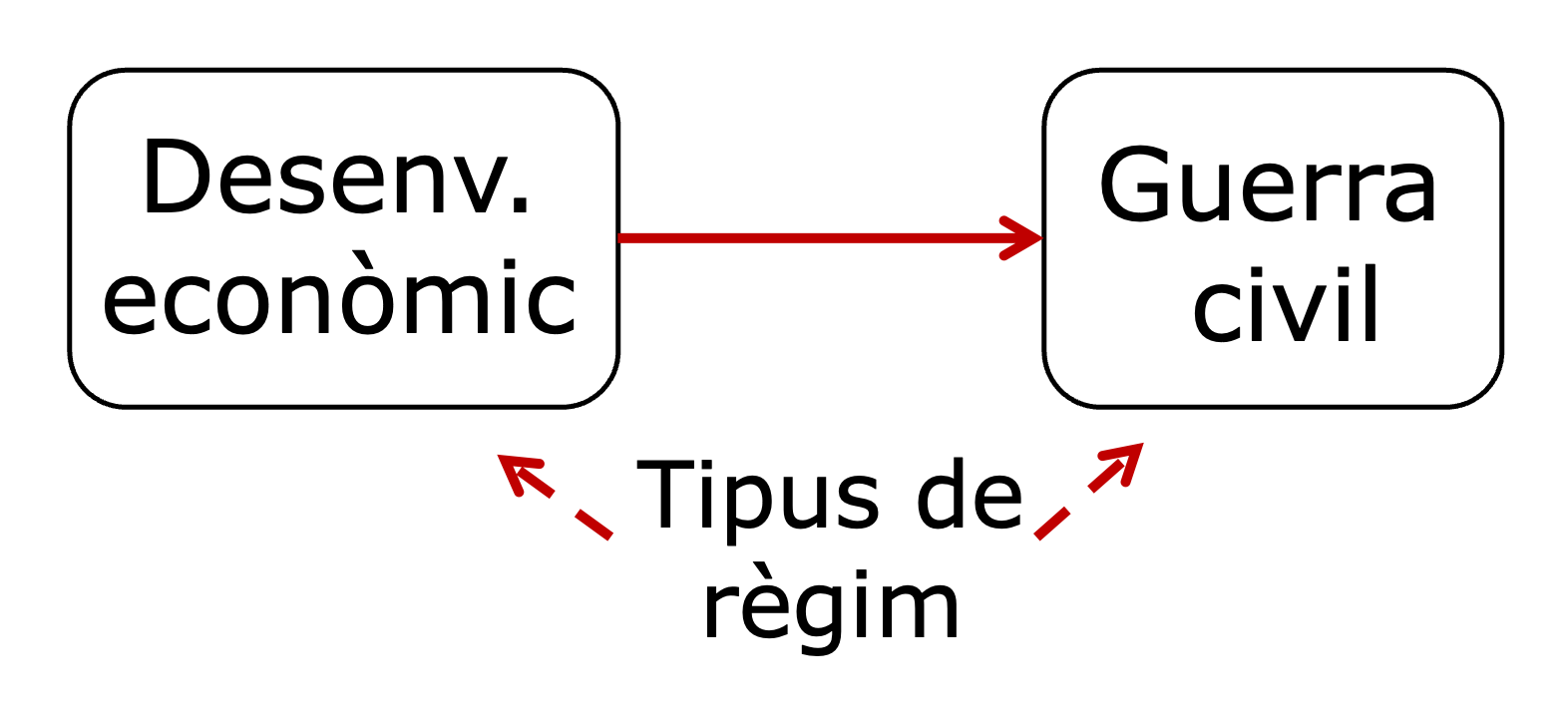
És perfectament possible que la correlació entre desenvolupament econòmic i guerra civil sigui espúria, és a dir, no tingui una relació directa. Aquesta relació pot ser causada pel fet que els règims democràtics augmenten la prosperitat econòmica i, al mateix temps, redueixen les guerres civils. Per tant, per determinar si existeix una relació directa entre guerra civil i prosperitat econòmica, és necessari analitzar aquesta relació mitjançant un control dels efectes del tipus de règim. “Controlar” per una variable significa utilitzar tècniques estadístiques que eliminin les diferències de base que una variable provoca entre els diferents grups de la relació. D’aquesta manera, podem determinar si la correlació entre les dues variables continua existint quan s’eliminen els efectes de la tercera variable.
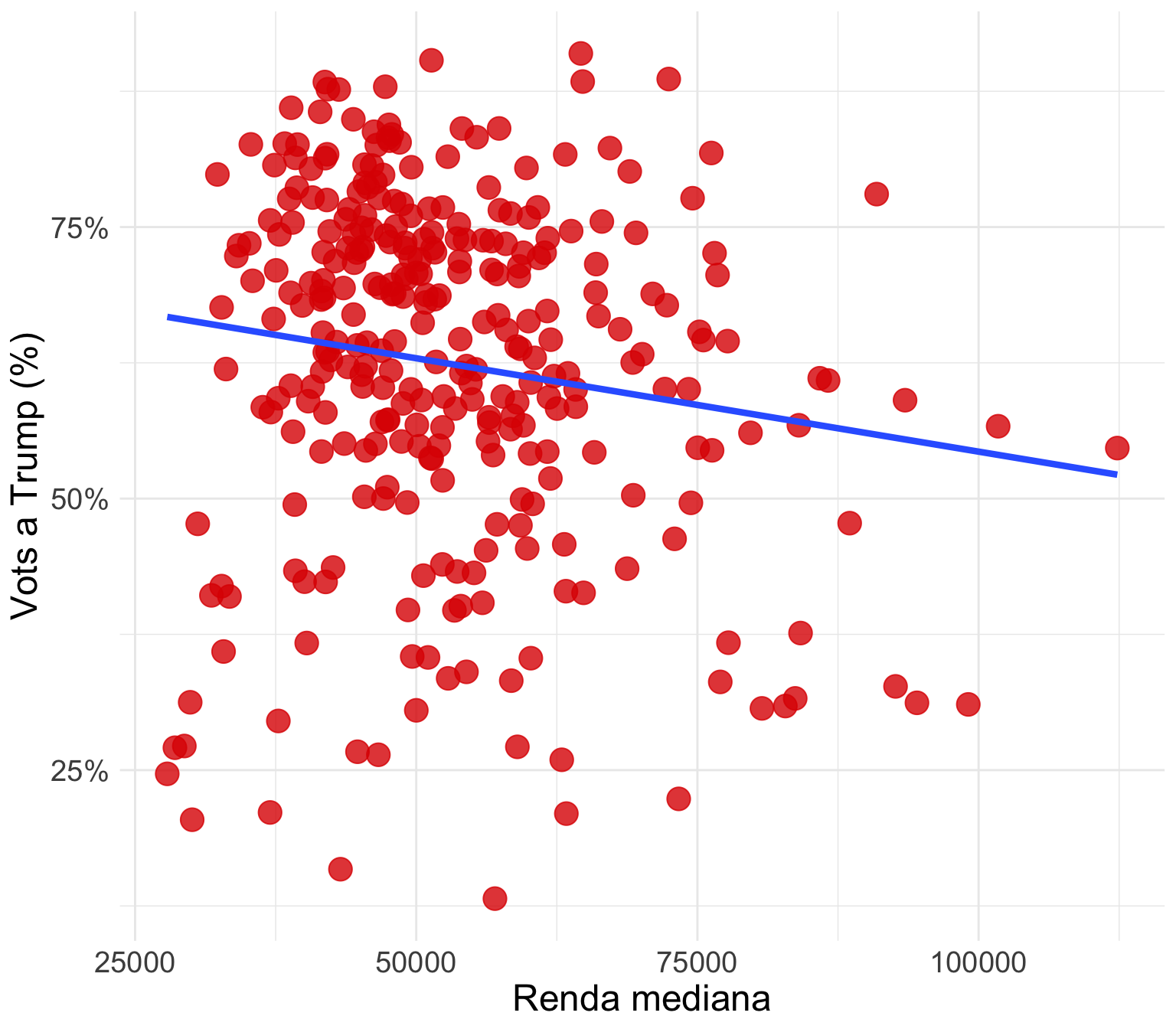
Examinem com funcionen aquests controls amb un exemple amb dades reals, però amb una mostra reduïda4. Considerem que el vot a Donald Trump a les eleccions del 2016 es pot explicar per la renda dels seus votants. És possible que les persones amb rendes més baixes estiguin insatisfetes amb les polítiques de l’administració anterior i, per tant, decideixin votar a Trump, que era el candidat alternatiu en aquelles eleccions. Si observem la correlació entre la renda mediana de cada comtat i el percentatge de vot a Donald Trump, veiem que la relació és negativa i feble (figura 3.8, a la dreta). Quant més alta és la renda mediana, menys tendència hi ha a votar Donald Trump. El coeficient de correlació és de -0.14, i la relació és significativa (p-valor de 0.009777).
4 Per millorar l’exemple, s’ha reduït el poder estadístic de la relació seleccionant un 10% aleatori de la mostra total.
No obstant això, és possible que aquesta relació vingui explicada per una tercera variable. La relació entre la renda i el vot a Trump serà espúria si, quan controlem per aquesta nova variable, la relació entre les dues desapareix.
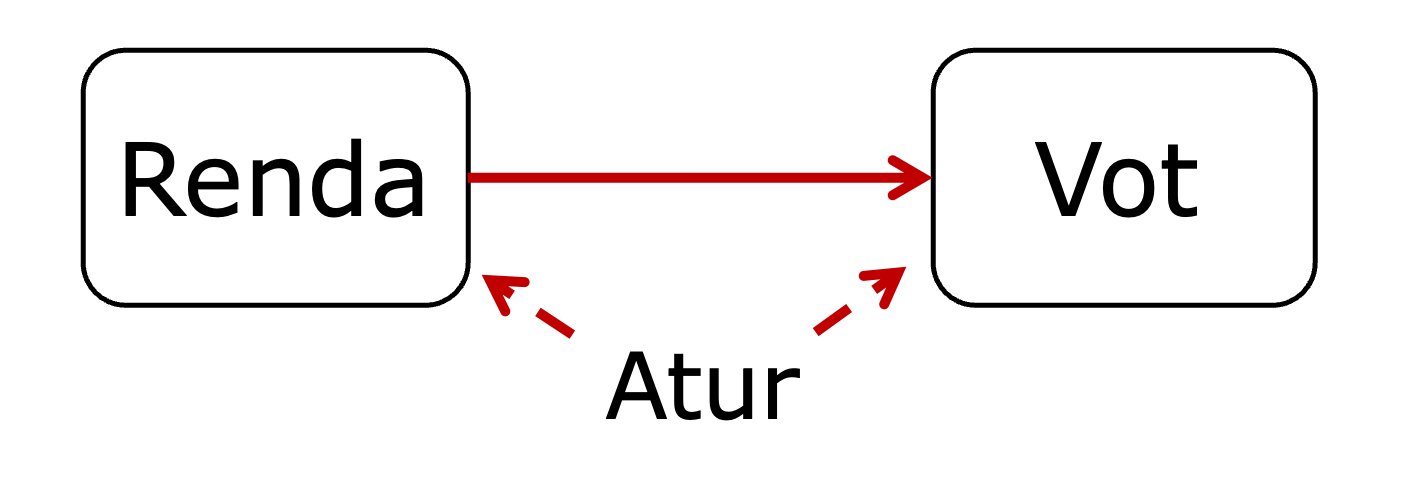
Pensem en l’atur com a variable de control (figura 3.9). És possible que en els comtats amb una taxa de desocupació més alta, la renda sigui més baixa i, a la vegada, els residents siguin més propensos a votar Donald Trump. Quan les persones es troben sense feina, els seus ingressos solen ser inferiors i sovint atribueixen aquesta situació al partit polític que està al poder, per tant, opten per votar el candidat alternatiu a les properes eleccions, que al 2016 era Donald Trump. Així doncs, amb la finalitat de controlar aquest efecte, examinarem la relació entre els ingressos i el vot a Trump tenint en compte els nivells d’atur de cada comtat.
Per simular com realitza el control per una tercera variable, a la figura 3.10 hem creat tres gràfics. A cada gràfic observem la relació entre els ingressos i el vot en comtats amb nivells baixos, mitjans i alts d’atur, respectivament. Si la relació entre les dues variables és espúria, esperarem que la correlació desapareixi al fer una mitjana de les diferències entre els gràfics.
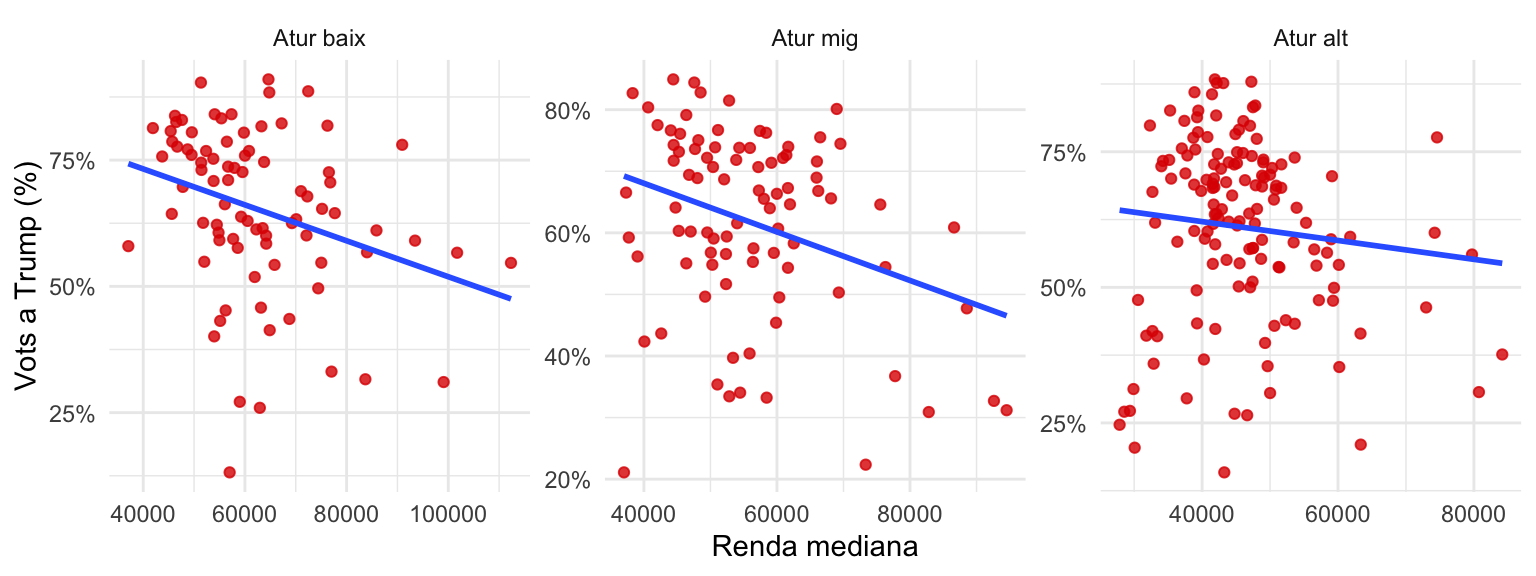
Si controlem pels nivells d’atur, la relació entre la renda i el vot a Donald Trump se segueix mantenint. Tant en el primer, segon i tercer gràfic, la relació continua sent negativa, i mostra una tendència molt similar a la que observàvem a la figura 3.8, on no havíem aplicat cap control.
Provarem amb un altre control: examinarem l’efecte de la mida del comtat en aquesta relació (figura 3.11). És raonable esperar que en zones rurals on hi ha poca població, la renda mitjana sigui més baixa que en zones urbanes i, a la vegada, hi hagi un suport més gran a Donald Trump, ja que aquest candidat tendia a atraure el vot conservador, més present en les zones rurals. A la figura 3.12 hem tornat a realitzar el mateix procediment per observar la relació entre les dues variables per diferents valors de la tercera variable que, en aquest cas, és la mida del comtat. Cada gràfic representa els comtats petits, mitjans i grans, respectivament.
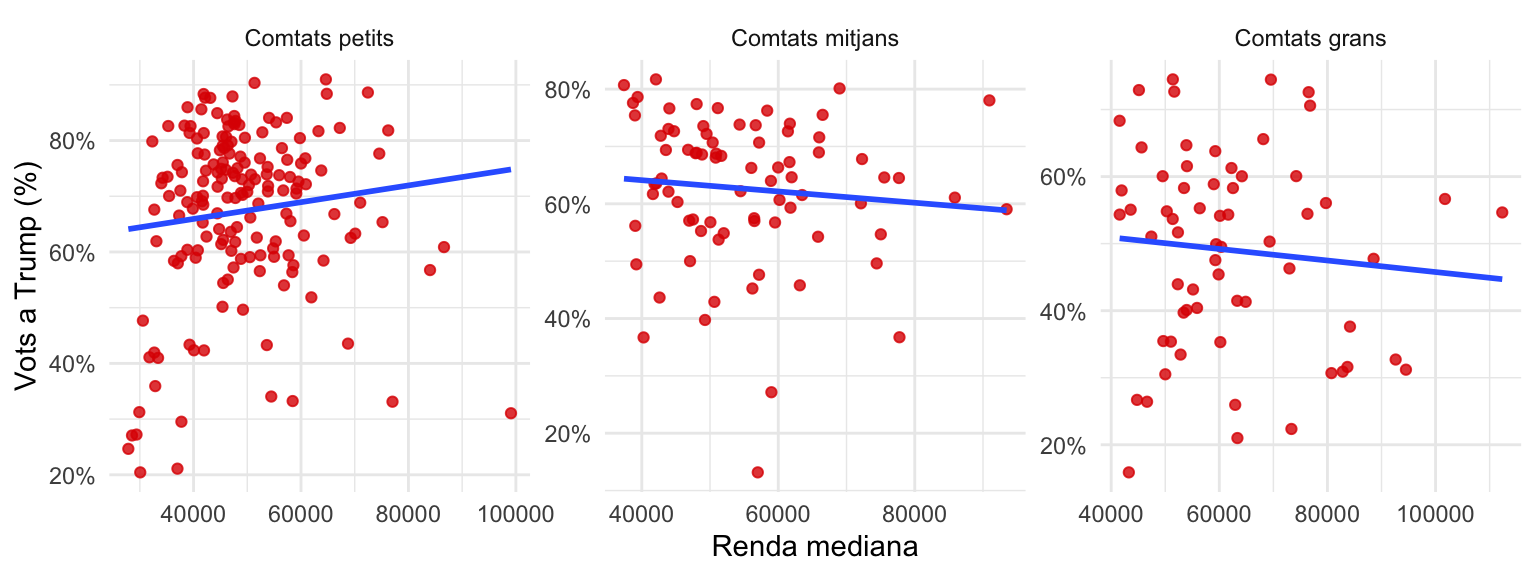
En aquesta ocasió observem que, quan controlem per població, la relació entre la renda i el vot a Donald Trump canvia. En els comtats amb poca població, la relació és lleugerament positiva, mentre que en els comtats més poblats la relació és negativa, tot i que molt feble. Si féssim una mitjana de les diferències de correlació entre els gràfics, és molt probable que aquest valor fos pròxim a 0 i que la relació deixés de ser significativa (efectivament, el p-valor passa a ser de 0.34, superior a 0.05). Això indica que la relació entre la renda i el vot a Donald Trump és espúria, donat que quan controlem per la mida del comtat, aquesta relació desapareix.
Cal tenir en compte que aquest exemple que acabem d’il·lustrar és només una representació per ajudar a entendre com es realitzen els controls. A la pràctica no es divideix la variable de control en tres categories, sinó en múltiples categories. Més endavant aprendrem a utilitzar eines estadístiques que ens permetran analitzar amb molts controls la relació entre dues variables.
Encara que en aquest capítol ens centrem en l’efecte de les variables de confusió sobre una variable, hem de tenir present que existeixen altres tipus de relacions: els mecanismes i les bifurcacions (figura 3.13). Els mecanismes és una variable que està a mig camí entre \(x\) i \(y\). És a dir, és afectada pel tractament i afecta al resultat. La bifurcació és una variable afectada a la vegada per \(x\) i per \(y\). Si la tenim en compte, observarem una relació entre \(x\) i \(y\), mentre que si no la tenim en compte no l’observarem o la observarem més dèbil.
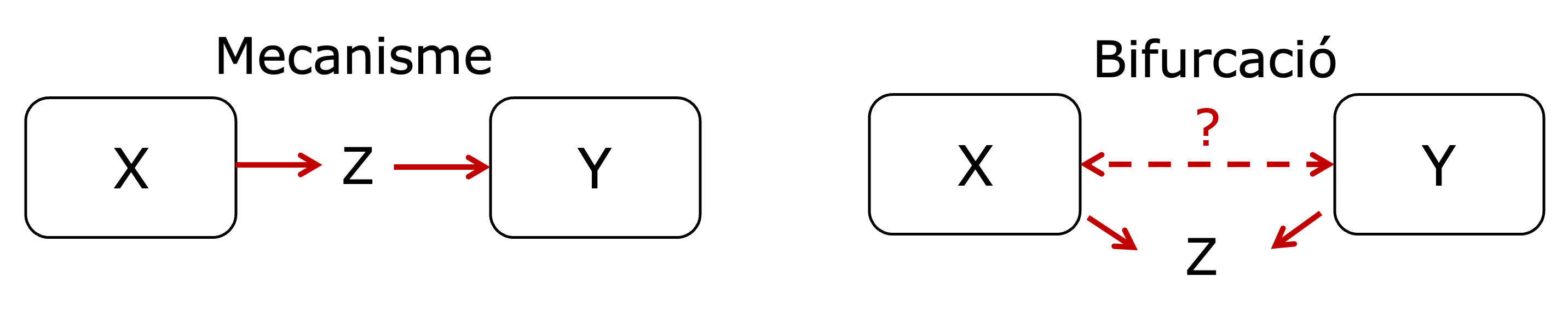
Aquestes relacions, però, no les estudiarem en aquest mòdul.
Per donar una interpretació causal a la relació entre dues variables, també és necessari assegurar-nos que, a més de controlar per altres variables, tampoc hi hagi causalitat inversa. Aquesta situació es pot produir quan la relació causal que pensem que existeix és realment a la inversa, de manera que l’efecte és la causa i la causa és l’efecte. La causalitat inversa no es pot esbrinar mitjançant el control per variables, ja que tots els coeficients que hem estudiat no ens diuen si \(x\) afecta \(y\) o bé si és \(y\) que afecta \(x\). Controlar per altres variables ens pot ajudar a aïllar l’associació, però no ens ajudarà a resoldre definitivament el problema de la causalitat.
Per aquesta raó, és important plantejar-nos si és possible que l’interpretació causal que estem proposant sigui al revés. Els dos criteris que utilitzarem són els de la plausibilitat i la temporalitat. Per una banda, una relació és plausible si, basant-nos en els coneixements existents, té un cert sentit des del punt de vista lògic. Aquesta plausibilitat pot ser recolzada per teories, evidències científiques o coneixements pràctics. D’altra banda, el criteri de la temporalitat ens porta a analitzar la seqüència temporal dels esdeveniments. Hem de determinar si \(x\) precedeix temporalment \(y\) i si aquesta seqüència concorda amb la idea de causalitat que estem considerant.
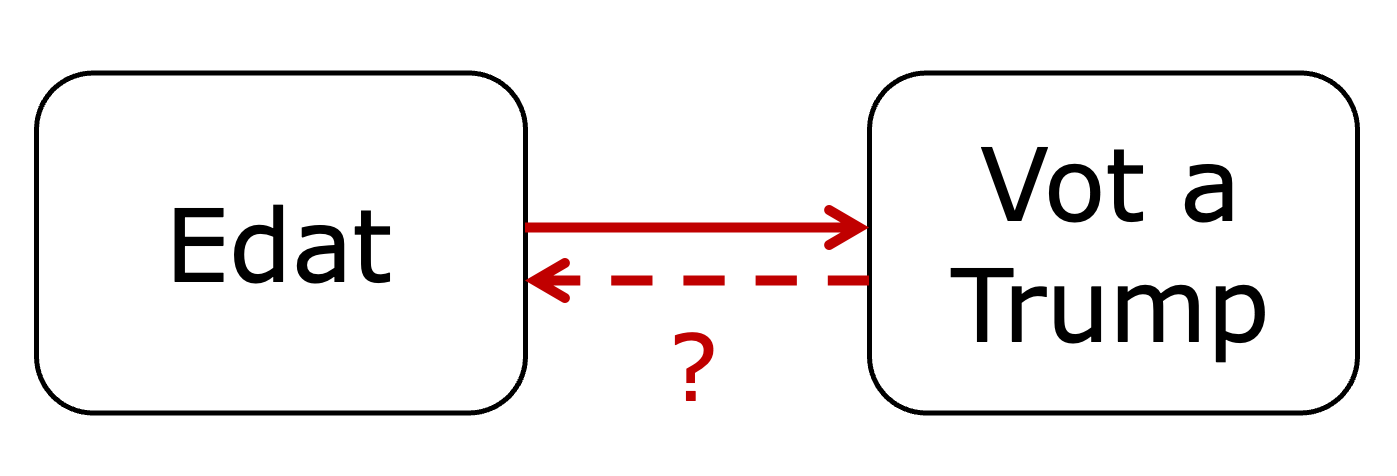
Seguidament, veurem alguns exemples. L’edat pot tenir alguna relació amb votar Donald Trump (figura 3.14) però, si pensem en termes de causalitat inversa, és poc plausible que tingui alguna cosa a veure l’edat al vot a Donald Trump. Sabem que el fet que tinguem més o menys anys és llei de vida i el fet que votem per Donald Trump no provocarà que tinguem més o menys anys. Serà més lògic pensar que la gent gran sol ser més conservadora i tindrà més propensió a votar Trump.
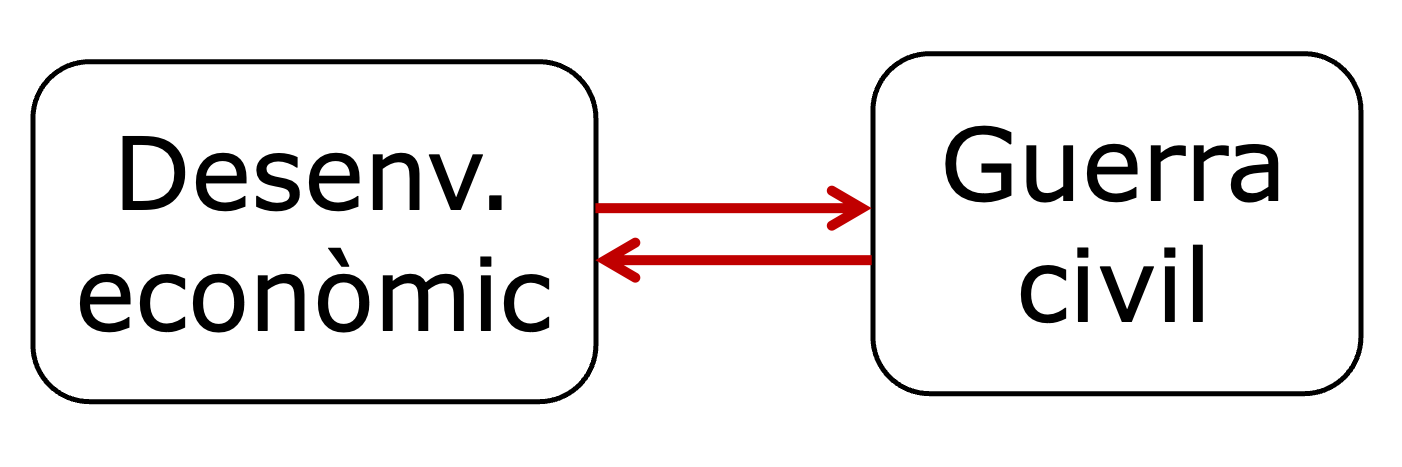
Abans ja hem suggerit la relació causal entre el desenvolupament econòmic i les guerres civils (figura 3.15). Però, si pensem en termes de causalitat inversa, també podem pensar que les guerres civils poden provocar menys prosperitat econòmica. És plausible i temporalment viable pensar que durant una guerra civil, les instrastructures són destruïdes, la producció s’atura i el capital i molts treballadors abandonen el país. Tots aquests efectes d’una guerra civil redueixen de forma directa la prosperitat econòmica. Per la qual cosa és possible que la relació causal sigui inversa.
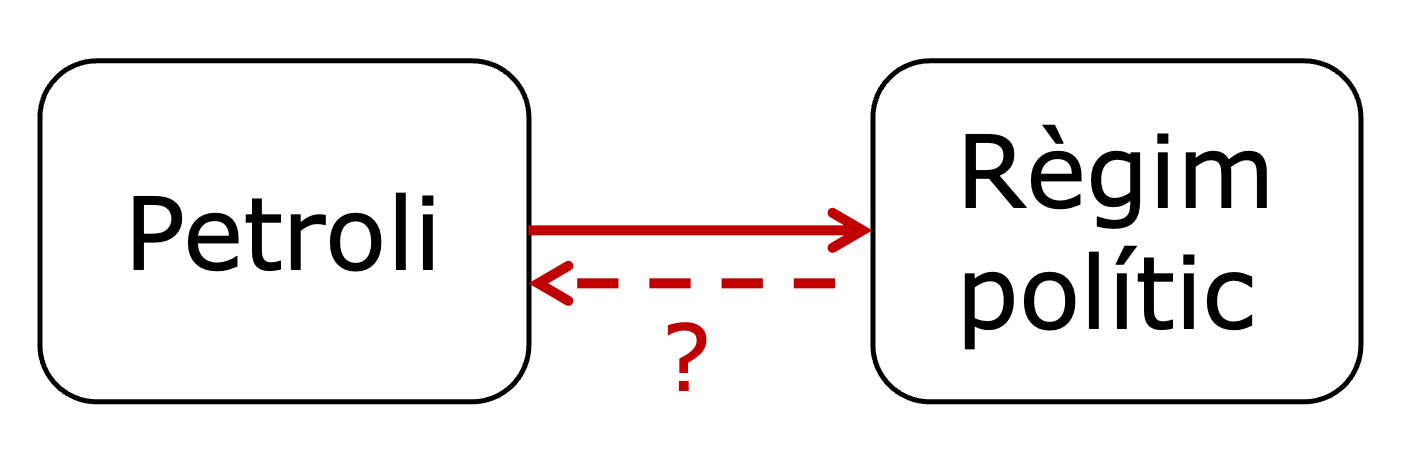
De manera similar, anteriorment hem considerat i assumit implícitament que el petroli té un efecte sobre el tipus de règim polític (figura 3.16). Una interpretació causal plausible és que la presència de petroli actua com un poderós incentiu per evitar la diversificació econòmica del país, mitjançant la creació de rendes que beneficien a determinats grups econòmics que poden influir en les estructures polítiques i institucions, cosa que afavoreix un règim menys democràtic.
Ara pensem a la inversa: pot ser que els règims autocràtics siguin la causa de la presència de petroli? És difícil defensar aquesta posició. Si estirem molt l’explicació, podem pensar que les autocràcies són més eficients a l’hora de descobrir jaciments de petroli a sota dels seus límits territorials, mentre que les democràcies segurament tenen la mateixa quantitat de petroli a sota del seu sòl, però no l’han descobert. Per tant, si pensem en causalitat inversa, podem trobar un argument que expliqui perquè és el tipus de règim el que causa el petroli i no el petroli el que causa el tipus de règim.
L’argument sona una mica absurd, i els geòlegs s’encarregaran de recordar-nos-ho. Però aquest exercici ens avisa de la importància de considerar sempre la possibilitat que hi hagi causalitat inversa. En el cas de les variables geogràfiques, com la presència de recursos naturals en un territori, és més raonable argumentar que la geografia afecta els fenòmens polítics, i no a l’inrevés. La geografia és una condició preexistent a l’existència dels règims polítics i no és influïda directament per ells.
Quan tractem amb variables geogràfiques, com ara la latitud, la longitud o la presència de recursos naturals, és plausible pensar que és la presència d’aquests fenòmens la que pot influir en fenòmens de tipus polític, econòmic o social. Tanmateix, és important ser cautelosos i evitar atribuir una interpretació causal directa a les correlacions entre variables.
Hi ha un exercici addicional que haurem de fer en qualsevol estudi, que és considerar la possibilitat de no haver controlat alguna variable important. Per exemple, en la relació entre la renda i el vot a Donald Trump, seria plausible tenir en compte el nivell educatiu com a variable de control, però ens podem trobar en la situació en què no disposem de dades sobre aquesta característica de la població. Això implica que, tot i que aquesta variable pugui ser rellevant, desconeixem els efectes que tindrà en la relació entre \(x\) i \(y\).
Podem resumir el què hem vist fins ara dient que a l’anàlisi de dades és difícil establir una relació entre dues variables, i encara és més complicat establir-ne una relació causal. És per això que en la majoria dels casos l’únic que podrem fer serà descartar altres possibilitats: