11 Anàlisi multivariada
11.1 Introducció
A l’hora d’analitzar relacions entre fenòmens polítics i socials és important tenir en compte dues premisses fonamentals. En primer lloc, és poc freqüent poder fer experiments en aquest camp, la qual cosa significa que les dades amb les quals treballarem s’hauran de recollir fora del laboratori i estaran subjectes a tota mena de biaixos. En segon lloc, com que les dades tindran biaixos, per examinar la relació entre dues variables haurem de tenir en compte l’efecte que estan tenint altres variables en aquesta relació. I això ens porta a haver de controlar l’efecte d’aquestes variables, que realitzarem amb l’anàlisi multivariada.
La tècnica d’anàlisi multivariada més freqüent és la regressió múltiple. Amb aquesta tècnica, podem provar la nostra hipòtesi principal enfront d’altres hipòtesis alternatives, afegint noves variables independents de control al model de regressió. Això ens permet fer afirmacions més robustes sobre la relació entre la variable independent i la variable dependent, ja que podem comprovar si les dues variables tenen relació fins i tot quan controlem els efectes d’altres variables independents.
Quan la variable dependent és numèrica, utilitzarem regressió lineal múltiple, mentre que quan la variable dependent és binària, utilitzarem regressió logística múltiple. En aquest capítol ens centrarem a explicar la regressió lineal múltiple, encara que la regressió logística funciona amb la mateixa lògica.
11.2 Regressió lineal multivariada
En l’apartat Regressió lineal del capítol anterior, hem començat a investigar per què hi ha països que tenen governs amb un major nombre de ministres que d’altres. Les dades del projecte de Nyrup & Bramwell (2020) ens han servit per examinar si dues variables numèriques, el PIB per càpita i el nombre de partits representats a l’executiu, estaven relacionades amb el nombre total de ministres. Hem comprovat que, almenys de manera descriptiva, quan es relacionen aquestes variables per separat sí que sembla que hi ha una relació estadísticament significativa entre aquests elements.
Per aprofundir en l’estudi de la mida dels governs, podem contrastar diverses hipòtesis mitjançant l’anàlisi multivariada. Això ens permet introduir diverses variables en un model de regressió i determinar si alguna d’elles té un efecte significatiu sobre la variable dependent, tenint en compte altres variables independents. És important que les variables que seleccionem estiguin justificades teòricament. I per això hem d’examinar la literatura acadèmica i entendre els estudis previs que hagin abordat preguntes similars. A través de la discussió i l’anàlisi de les teories principals de la disciplina, podrem trobar possibles respostes a la nostra pregunta de recerca. Algunes variables que podríem considerar són les següents:
Sabem que els diferents règims polítics influeixen en molts aspectes del funcionament polític dels països, per exemple en el nivell de rendició de comptes i la possibilitat de canviar els governants Hellwig & Samuels (2007). Així doncs, el tipus de règim també pot influir en el nombre de persones a qui s’ha de fer rendir comptes. Fent servir les dades disponibles a WhoGov, hem simplificat els diferents règims entre democràcies, anocràcies i autocràcies (Fearon & Laitin, 2003).
Un segon element que podríem pensar que pot ser rellevant és el nombre de partits. La literatura clàssica de governs de coalició mostra que la presència de diferents partits afecta el repartiment de carteres (Gamson, 1961) i també hi ha literatura que mostra que les coalicions afecten els nivells de despesa pública dels governs (Wehner, 2010). A més a més, com hem vist a l’anterior apartat, sembla que les coalicions polítiques poden afectar el nombre de ministeris, però és important saber si aquesta relació es manté quan tenim en compte altres variables d’interès.
També hi ha estudis importants en l’àrea de l’economia política que mostren que el creixement econòmic és important per entendre la inestabilitat política, per exemple quan l’economia creix és menys freqüent veure canvis en el govern (Alesina et al., 1996). De manera similar, i a diferència del que hem testat a l’apartat anterior, podríem pensar que el que pot ser rellevant per entendre la mida dels governs no és el PIB per càpita, sinó els canvis interanuals en el PIB per càpita. Podríem hipotetitzar que, si hi ha creixement econòmic serà més habitual veure governs amb més ministres. A partir del càlcul en la variació de les dades del PIB obtingudes del Banc Mundial podem fer servir una variable que capturi aquesta variació (
vargdp).Finalment, un altre factor rellevant podria ser l’experiència del cap de govern. Podríem pensar que, a mesura que un mateix líder fa més anys que actua com a cap de l’executiu tindrà més compromisos polítics i tendirà a fer governs compostos per un major nombre de persones. La variable
leaderexperience_totalde la base de dades de WhoGov ens proporcionarà aquesta informació.
11.3 Anàlisi empírica
Abans de crear el model de regressió, sempre és necessari fer una anàlisi univariada de cadascuna de les variables que volem incloure. Per això utilitzarem les eines visuals i quantitatives que coneixem per fer una descripció de les variables. Aquest procediment és important per dos motius:
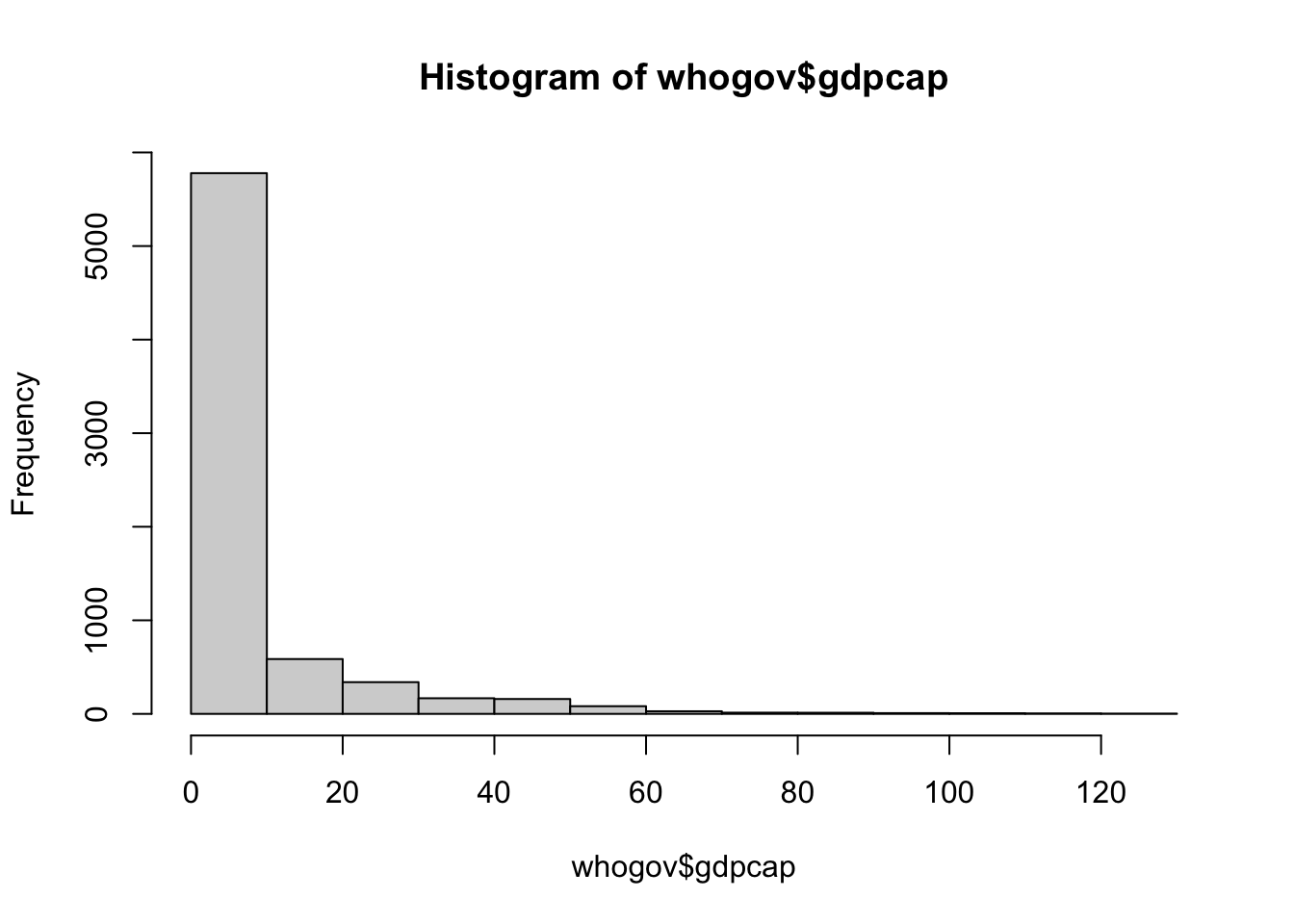
Algunes variables poden no tenir una distribució normal. Per millorar la bondat de l’ajustament del model, una opció és transformar les variables per tal que adquireixin una distribució més propera a la normal. Per exemple, les dades de PIB per càpita o de població acostumen a tenir asimetria negativa, per la qual cosa normalment es transformen mitjançant el logaritme neperià per aconseguir una distribució més simètrica. En el cas de la variable
gdpcapque vam fer servir al capítol anterior, s’hi observa una asimetria positiva (vegeu figura 11.1), la qual cosa podria afectar la bondat de l’ajustament del model. Per això, podríem considerar aplicar una transformació quadràtica o exponencial, o bé eliminar els casos extrems. No obstant, per simplicitat, no vam aplicar cap transformació anteriorment. En el model multivariant, a més, no farem servir la variablegdpcap, sinó la variablevargdpque té una distribució normal.Hem de vigilar la presència d’una colinealitat injustificada entre les variables. Aquesta es produeix quan el coeficient de correlació entre dues variables és molt alt (superior a 0.85, per exemple), la qual cosa pot indicar que aquestes dues variables ens estan informant del mateix des del punt de vista empíric1. Només inclourem variables amb una elevada colinealitat en cas que estigui justificat.
1 Per exemple, no tindria gaire sentit incloure el PIB per càpita i el PNB per càpita, perquè més o menys ens estarien donant informació del mateix fenomen: l’activitat econòmica per habitant d’un país, el nivell de desenvolupament, etc.
Per analitzar la colinealitat entre variables, utilitzarem la taula de correlació, la qual mostra el coeficient de correlació entre totes les variables que considerem incloure en el model de regressió. En el resultat del codi següent veiem com els coeficients de correlació entre les variables són baixos. Això indica que no hi ha cap risc important d’existència de colinealitat entre les variables. És important remarcar, però, que la taula de correlació només ens mostra les correlacions entre variables numèriques. En el cas de la variable regime que indica el tipus de règim polític (democràcia, anocràcia o autocràcia) no es pot incloure a la taula de correlació; la manera de veure si està correlacionada amb les altres variables seria a partir de la comparació de les mitjanes, on veiem que sí que pot haver-hi algunes diferències entre les variables del nombre de partits i de l’experiència dels líders, en què les autocràcies es comporten diferent a les democràcies i anocràcies. Tot i això, aquestes diferències quan les variables són categòriques són menys preocupants.
cor(whogov[,c("n_minister","n_party","vargdp","leaderexperience_total")],
use = "pairwise.complete.obs") |>
round(2)
## n_minister n_party vargdp leaderexperience_total
## n_minister 1.00 0.25 -0.01 0.24
## n_party 0.25 1.00 -0.01 -0.12
## vargdp -0.01 -0.01 1.00 -0.02
## leaderexperience_total 0.24 -0.12 -0.02 1.00
whogov |>
group_by(regime) |> filter(!is.na(regime)) |>
summarise(n_minister = mean(n_minister,na.rm = T),
n_party = mean(n_party,na.rm = T),
vargdp = round(mean(vargdp,na.rm = T),digits = 3),
leaderexp = mean(leaderexperience_total,na.rm = T)) |>
ungroup()
## # A tibble: 3 × 5
## regime n_minister n_party vargdp leaderexp
## <fct> <dbl> <dbl> <dbl> <dbl>
## 1 Democracy 16.8 2.83 0.067 4.41
## 2 Anocracy 16.3 3.02 0.071 4.40
## 3 Autocracy 19.3 1.58 0.071 9.41No existeix una regla clara sobre quantes variables independents hauríem de considerar en un model de regressió, ni tampoc sobre quines variables hauríem de triar. No obstant, hem de tenir en compte que el nombre de variables independents que introduïm al model de regressió depèn del nombre de casos que tinguem disponibles. Si tenim molt pocs casos, és possible que introduint unes poques variables ens quedem sense cap que tingui significació estadística amb la variable dependent.
Quan només podem incloure unes poques variables, una possibilitat és que cada una d’elles representi una gran perspectiva teòrica de la literatura o un nivell d’anàlisi diferent (Berg-Schlosser & De Meur, 2009). Per exemple, una variable pot representar factors econòmics, l’altra factors polítics i l’última factors socials. També podríem triar variables que representin diferents nivells d’anàlisi, com ara el societal, l’estatal i el sistèmic. En el nostre cas, les variables representen el nivell mundial (regime), l’economia del país (vargdp), la política del país (n_party) i el nivell individual (leaderexperience_total).
11.4 El model de regressió
El model de regressió múltiple es construeix de manera molt semblant al model de regressió simple. L’únic canvi és que a l’argument de la fórmula dins de la funció lm() hi afegirem les variables addicionals, separades pel signe +.
summary(lm(data = whogov,
formula = n_minister ~ regime + n_party + vargdp + leaderexperience_total))
##
## Call:
## lm(formula = n_minister ~ regime + n_party + vargdp + leaderexperience_total,
## data = whogov)
##
## Residuals:
## Min 1Q Median 3Q Max
## -20.371 -4.307 -0.660 3.699 34.181
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 12.52501 0.17299 72.404 < 2e-16 ***
## regimeAnocracy -1.02341 0.24498 -4.177 2.98e-05 ***
## regimeAutocracy 3.07168 0.17905 17.155 < 2e-16 ***
## n_party 1.27421 0.03687 34.558 < 2e-16 ***
## vargdp -0.30703 0.43196 -0.711 0.477
## leaderexperience_total 0.19438 0.01119 17.372 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.232 on 6964 degrees of freedom
## (1087 observations deleted due to missingness)
## Multiple R-squared: 0.211, Adjusted R-squared: 0.2104
## F-statistic: 372.4 on 5 and 6964 DF, p-value: < 2.2e-16La informació principal que podem treure del model és la següent:
- Constant: El coeficient de la constant o intercept, que trobem a la columna Estimate, mostra quin valor pren la variable dependent quan el valor de totes les variables independents és 0. És a dir, un hipotètic govern format en una democràcia, on cap partit formés part del govern (un govern tecnocràtic pur), on el PIB per càpita no hagués variat gens, i en què el cap del govern fos novell estaria format per 12.5 ministres. Evidentment, en estar plantejat en termes hipotètics, aquest valor pot resultar irreal.
Quan s’inclou una variable categòrica en un model de regressió, s’obtenen tants coeficients com categories tingui la variable menys un. Els coeficients d’aquestes categories sempre s’hauran d’interpretar respecte a la categoria que no apareix a la taula de regressió, que es coneix com la categoria de referència. En el cas que ens ocupa, la categoria de referència de la variable regime és “Democràcia” i, per exemple, el coeficient d’autocràcia ens informa que a les autocràcies s’estima que hi ha, de mitjana, tres ministres més que a les democràcies.
La constant o intercept quan hi ha variables categòriques s’ha d’interpretar com el valor de la variable dependent quan en el cas que les variables quantitatives sigui igual a 0 i les variables categòriques es trobin a la categoria de referència.
- Coeficients estimats: Els coeficients estimats (columna Estimate) indiquen quina és la variació en la variable dependent per cada unitat que augmentem en la independent en qüestió deixant la resta de variables independents constant. Per exemple, per cada partit addicional que formi part del govern, el nombre de ministres augmenta un 1.27421 mantenint les altres variables constants. Si la variació del PIB ha estat d’un punt, el govern disminueix en 0.30703 membres. I així successivament amb les altres variables.
- Significació: A la columna Pr(>|t|) veiem el valor p de cada variable. Totes les variables són estadísticament significatives excepte la variació del PIB. Per tant, tenim indicis que tant el tipus de règim com el nombre de partits o l’experiència del cap de govern són rellevants a l’hora de definir el nombre de ministres, però no podem assegurar amb certesa que aquesta relació existeixi en relació amb la variació del PIB.
- Determinació del model: En global, l’R2 del model és de 0.2104 (sempre que estimem models de regressió múltiple mirarem l’Adjusted R-squared). Això significa que amb la variació dels valors de les variables independents podem explicar un 21% de la variació de la variable dependent.
Si comparem aquest model de regressió amb el que hem utilitzat en l’apartat anterior, veiem com la inclusió de noves variables ha permès explicar un percentatge més alt de la variabilitat de la variable dependent. A partir d’aquí tenim la possibilitat de dur a terme anàlisis més detallades, com ara provar d’eliminar o incloure altres variables, sempre que estiguin justificades teòricament i hagin estat analitzades empíricament, per tal de determinar com afecten el coeficient de determinació.
Amb la informació obtinguda de l’anàlisi de regressió multivariada, ja podem crear una fórmula que ens serveixi per predir el valor que prendria la variable dependent en funció dels valors de les variables independents. D’acord amb els coeficients estimats del model, la fórmula seria la següent:
\[ Ministres = 12.52501 + Anocràcia * (-1.02341) + Autocràcia * 3.07168 + Partits * 1.27421 + Canvi PIB * (-0.30703) + Exp. líder * 0.19438 \]
Aquesta equació ens permet fer prediccions. Per exemple, podríem preguntar-nos quina mida tindria el govern en un hipotètic país autocràtic, amb tres partits al govern, on el PIB hagués crescut un 7%, i amb un líder que fa 10 anys que és al govern?
anocracia <- 0
autocracia <- 1
partits <- 3
pib <- 0.07 # variable en escala de proporcions, no de percentatge
lider <- 10
12.52501 + anocracia * (-1.02341) + autocracia * (3.07168) + partits * 1.27421 + pib * (-0.30703) + lider * 0.19438
## [1] 21.34163La resposta és que esperaríem trobar un consell executiu format per 21.3 ministres.
La mida seria de 16.05454.
11.5 Presentar i llegir els resultats
A l’hora de presentar els resultats de la nostra anàlisi, sol ser habitual fer-ho d’una manera semblant a la que es mostra a la taula 11.1. R té alguns paquets que ens fan la feina de passar els resultats d’una regressió en net. Un dels més utilitzats és jtools, que amb la funció export_summs() permet crear una taula amb la informació essencial que necessitem per poder llegir i interpretar un model de regressió. Fins i tot permet introduir i contrastar diferents models. Per exemple, hem inclòs un segon model on, en lloc d’incloure la variable categòrica de règim polític, hem inclòs la dummy que indica si en aquell govern hi havia dones o no hi havia dones al consell executiu.
Per crear la taula de regressió, primer desarem cada model amb el nom d’un objecte. A l’exemple següent, els hem desat com a mod1 i mod2. I a continuació ubiquem els objectes com a arguments de la funció export_summs().
library(jtools)
# Model 1
mod1 <- lm(data = whogov,
formula = n_minister ~ regime + n_party + vargdp + leaderexperience_total)
# Variable binària per presència de dona ministra
whogov <- whogov |>
mutate(female_minister = ifelse(n_female_minister>0,1,0))
# Model 2
mod2 <- lm(data = whogov,
formula = n_minister ~ female_minister + n_party + vargdp + leaderexperience_total)
# Visualització de models
export_summs(mod1,mod2, scale=T)| Model 1 | Model 2 | |
|---|---|---|
| (Intercept) | 16.82 *** | 16.71 *** |
| (0.13) | (0.13) | |
| regimeAnocracy | -1.02 *** | |
| (0.24) | ||
| regimeAutocracy | 3.07 *** | |
| (0.18) | ||
| n_party | 2.70 *** | 1.98 *** |
| (0.08) | (0.08) | |
| vargdp | -0.05 | 0.03 |
| (0.07) | (0.08) | |
| leaderexperience_total | 1.41 *** | 1.96 *** |
| (0.08) | (0.08) | |
| female_minister | 2.42 *** | |
| (0.16) | ||
| N | 6970 | 6975 |
| R2 | 0.21 | 0.19 |
| All continuous predictors are mean-centered and scaled by 1 standard deviation. *** p < 0.001; ** p < 0.01; * p < 0.05. | ||
A les taules de regressió, les variables independents se situen a les files de la taula i cada model predictiu se situa a les columnes. Al marge superior o bé al títol de la taula hi apareix quina és la variable dependent. La informació que conté la taula de regressió és la següent:
- Els coeficients estimats per cada variable independent s’indiquen a l’alçada de la variable corresponent, normalment amb dos o tres decimals.
- Al costat de cada coeficient hi trobarem la seva significació estadística, representat per asteriscos.
- L’error estàndard, que trobarem entre parèntesis a sota de cada coeficient. Com sabem, si un coeficient concret és inferior a dues vegades el seu error estàndard, la relació amb la variable independent no serà significativa.
- A la part inferior de la taula també trobarem informació com la mida de la mostra (N) i l’R2.
Aquestes visualitzacions són útils per comparar diversos models i determinar si hi ha diferències en els valors de la variable dependent segons les variables independents que s’incorporen en cada model. En aquest sentit, podem concloure que la inclusió de les variables sobre la presència de dones al govern no aporta gaire informació en relació amb el model anterior, ja que no millora la capacitat d’estimació (mesurada amb R2) quan s’incloïa la variable de règim polític.
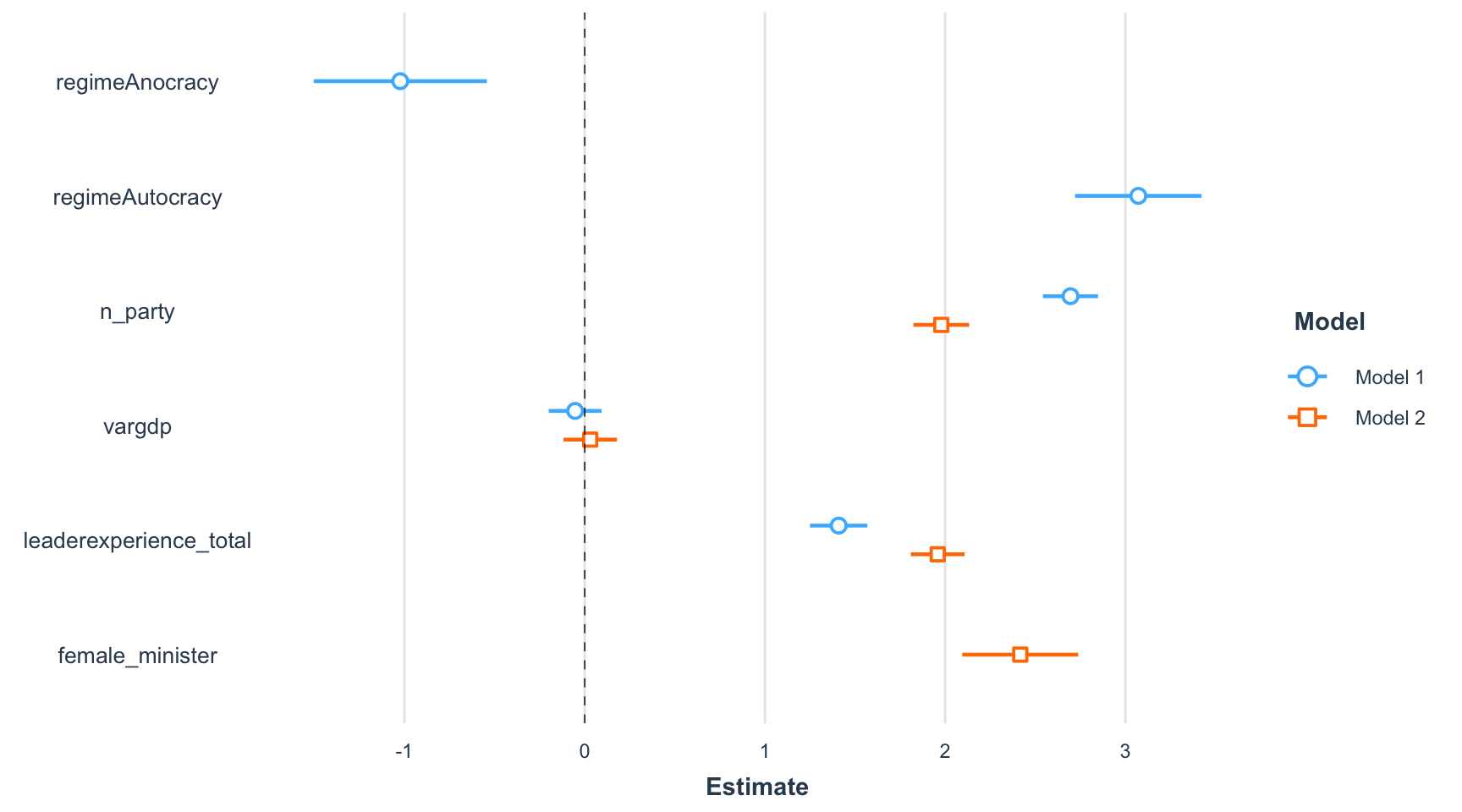
Una altra visualització interessant que podem obtenir a partir d’una anàlisi de regressió múltiple és la que mostra la figura 11.2. Aquest gràfic ens proporciona una informació semblant a la de la taula de regressió:
- Cada color representa un model diferent.
- Els punts indiquen els coeficients estimats de cada variable independent.
- Les línies a dreta i esquerra dels punts indiquen l’interval de confiança del 95%.
- Si les línies no creuen la línia vertical discontínua situada al valor 0, és senyal que la relació entre la variable independent concreta i la variable dependent és significativa. En el gràfic es compleix que l’única variable no significativa és
vargdp, la variable que tenia un valor p superior a 0.05 en tots els models estimats anteriorment.
plot_summs(mod1,mod2, scale=T)