dempeace_tc2 <- dempeace_tc |>
mutate(war = if_else(war == 1, "War", "NoWar"),
democracy = if_else(democracy == 1, "Dem", "NoDem"))
# Taula de contingència. Valors absoluts.
table(dempeace_tc2$war, dempeace_tc2$democracy)
# Taula de contingència. Valors relatius.
round(prop.table(table(dempeace_tc2$war, dempeace_tc2$democracy), margin = 2) * 100, 1)9 Independent categòrica
9.1 Introducció
Si volem realitzar una anàlisi bivariant on la variable independent és categòrica, utilitzarem les tècniques conegudes, com la taula de contingència o la diferència de mitjanes. Aquests dissenys no tenen en compte la influència potencial de variables de confusió, per la qual cosa només són vàlids en determinades condicions. De fet, són tècniques molt utilitzades en experiments de laboratori, en què la variable independent és el tractament que apliquem a unes unitats seleccionades aleatòriament i la variable dependent és l’efecte que es vol observar.
La principal diferència entre les dues tècniques és que a la taula de contingència la variable dependent és categòrica, mentre que a la diferència de mitjanes és numèrica. Com que les dades que utilitzem a les Relacions Internacionals acostumen a ser observacionals, habitualment usarem aquests dissenys com el primer pas cap a l’anàlisi multivariant.
9.2 Associació entre dues variables categòriques
Quan volem estudiar l’associació entre una variable independent categòrica i una variable dependent també categòrica, solem començar elaborant el que es coneix com a taula de contingència. Aquesta taula mostra els valors de la variable independent a l’eix horitzontal i els valors de la dependent a l’eix vertical, de manera que cada cel·la de la taula representa el recompte total d’observacions que corresponen a cada combinació entre els nivells de les dues variables.
Un cop tenim a cada cel·la el nombre de freqüències, calcularem els percentatges de cada freqüència respecte al total de la columna. Això ens permet avaluar la relació entre les dues variables i detectar si hi ha alguna tendència o patró significatiu a les dades.
A les Relacions Internacionals, una de les primeres taules de contingència va ser proposada el 1976 pels fundadors del projecte Correlates of War, J. David Singer i Melvin Small, en el marc del seu estudi quantitatiu sobre la pau democràtica (Singer & Small, 1976). Per conèixer si les democràcies eren menys propenses a entrar en guerres que les autocràcies, els investigadors van plantejar una taula de contingència en què la variable independent era el règim polític, amb dos valors possibles (democràcia i no democràcia)1 mentre que la variable dependent era la participació en una guerra, també amb dos valors possibles.
1 Els autors distingien la democràcia burgesa o bourgeois democracy d’altres tipus de democràcia mitjançant l’ús del valor 1 per a la primera.
| ccode | stateabb | year | democracy | war |
|---|---|---|---|---|
| 2 | USA | 1800 | 1 | 0 |
| 2 | USA | 1801 | 1 | 0 |
| 2 | USA | 1802 | 1 | 0 |
| 2 | USA | 1803 | 1 | 0 |
| 2 | USA | 1804 | 1 | 0 |
| 2 | USA | 1805 | 1 | 0 |
| 2 | USA | 1806 | 1 | 0 |
| 2 | USA | 1807 | 1 | 0 |
| 2 | USA | 1808 | 1 | 0 |
| 2 | USA | 1809 | 1 | 0 |
Podem recrear la taula de contingència que van suggerir Singer i Small al Jerusalem Journal of International Relations amb dades actuals. El resultat és un marc de dades (taula 9.1) que classifica cada observació Estat-any segons si un Estat determinat és una democràcia (1) o no ho és (0), i segons si està participant en una guerra (1) o no (0). El rang de temps és entre 1816 i 2005, per la qual cosa tenim més de 17.000 observacions.
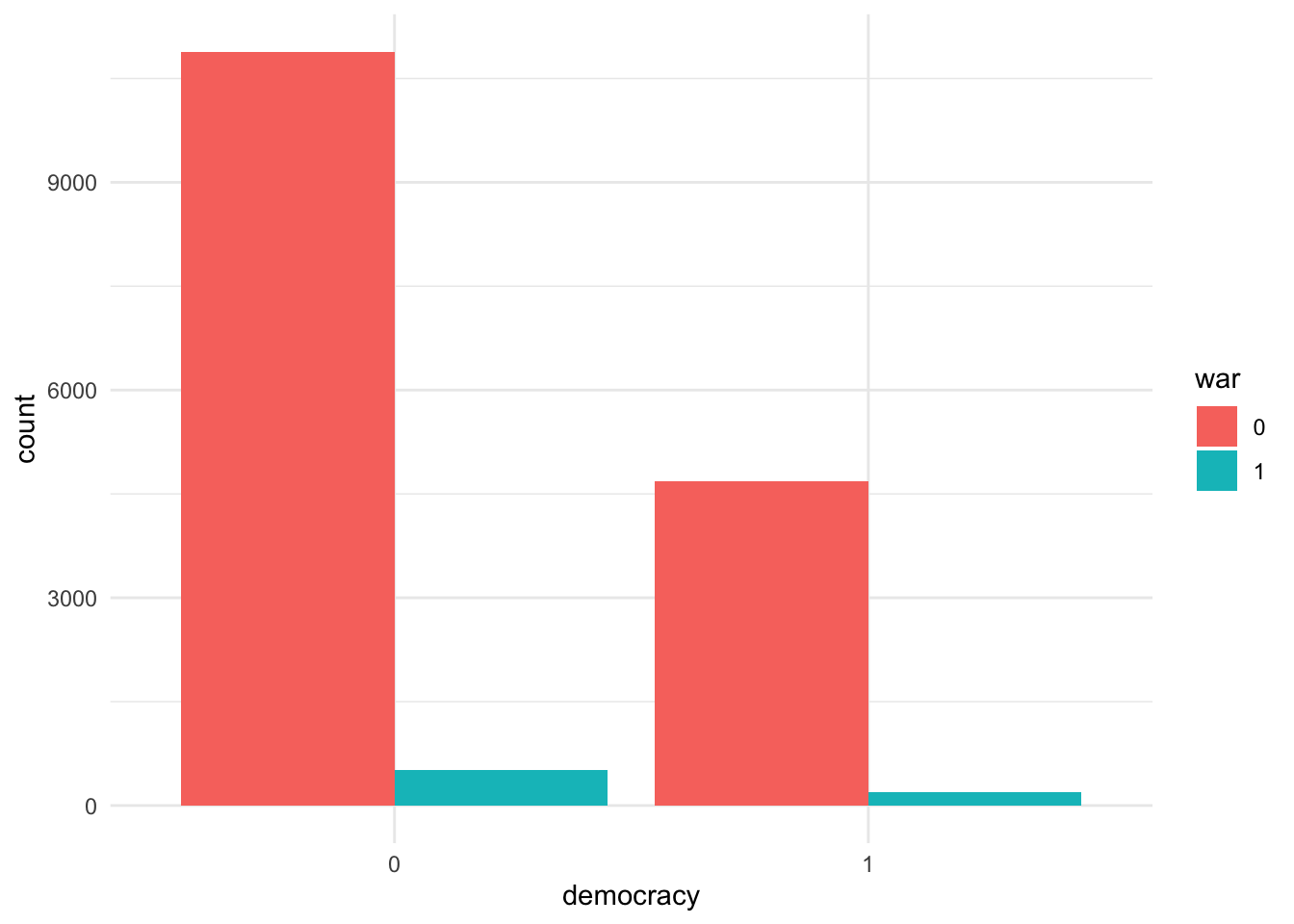
Per crear la taula de contingència, utilitzarem la funció table() i introduirem les dues variables en forma de vector. Com a primer argument, hi posarem la variable independent i com a segon, la variable dependent. Així, la variable democràcia ens quedarà a l’eix horitzontal de la taula i la variable guerra a l’eix vertical. El resultat és el que es mostra a la taula 9.2. En el gràfic de l’esquerra, que representa els valors absoluts, observem que d’entre totes les observacions Estat-any, 10.886 corresponen a règims autocràtics que mai han estat en guerra i 507 a règims autocràtics que sí que ho han estat. Pel que fa a les democràcies, la suma dels anys que no han estat en guerra és de 4.685, mentre que la suma dels anys que sí que ho ha estat és de 190.
Com que hi ha hagut moltes més autocràcies que democràcies al llarg de la història recent, les freqüències absolutes poden dificultar veure la relació entre variables. Per això, també és important mostrar una taula de contingència amb valors relatius, és a dir, en percentatges. A la taula de la dreta, podem observar que els règims democràtics han estat en guerra el 3.9% dels anys, mentre que els règims autocràtics ho han estat el 4.5% dels anys2.
2 Per calcular les proporcions per columnes, a la funció table() hi hem afegit la funció prop.table() amb l’argument margin = 2. També hem multiplicat els resultats per 100, per veure les dades en percentatges, i hem arrodonit els decimals amb round() i l’argument 1, per visualitzar només un decimal.
| Dem | NoDem | |
|---|---|---|
| NoWar | 4685 | 10886 |
| War | 190 | 507 |
| Dem | NoDem | |
|---|---|---|
| NoWar | 96.1 | 95.5 |
| War | 3.9 | 4.5 |
Taula 9.2: Taula de contingència de democràcia i guerra.
Per visualitzar les dades, el gràfic més habitual que utilitzarem serà un diagrama de barres que inclogui l’argument position = fill, que permet veure la magnitud relativa de cada valor de la variable dependent segons els valors de la independent. En el gràfic següent (figura 9.1), hem recodificat les variables a vector de caràcter, hem eliminat les dades perdudes i hem reproduït un diagrama de barres. Sempre posarem la variable independent a l’argument x i la variable dependent a l’argument fill.
Mostra codi
dempeace_tc2 |>
mutate(across(everything(), ~ as.character(.))) |>
filter(!is.na(democracy)) |>
ggplot(aes(x = democracy, fill = war)) +
geom_bar(position = "fill")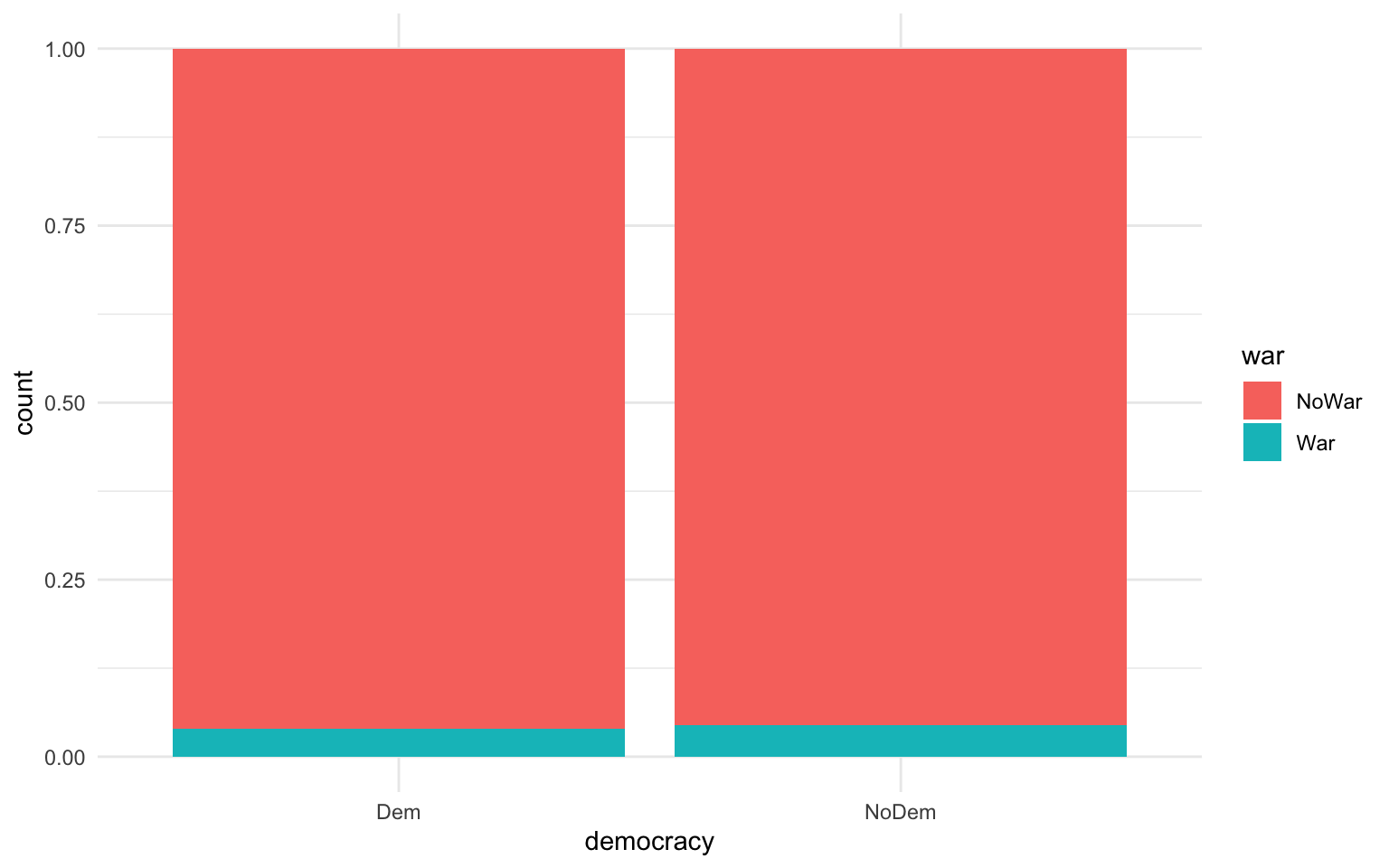
Dodge.
Una altra opció és posar les barres de costat amb l’argument position = dodge, però hem de tenir en compte que no ens permetrà veure la magnitud.
Un cop ja hem visualitzat la relació entre democràcia i guerra, ens queda quantificar l’associació. El primer que ens cal saber és la força de la relació mitjançant el coeficient de correlació. El mètode més habitual és el test de Cramer, que retorna un valor proper a 1 si la relació és molt forta i un valor proper a 0 si no és forta. Per a utilitzar aquestes eines, haurem d’instal·lar i carregar el paquet DescTools i utilitzar la funció CramerV(). A dins de la funció, introduirem un argument per a cada variable.
Altres testos d’associació.
Hi ha diferents maneres de testar l’associació entre dues variables categòriques. Per exemple, si utilitzem el test de Cramer també podem obtenir-lo a través del paquet confintr, que ens dona el mateix resultat:
[1] 0.01250241Un altre test habitual és el de Lambda, que trobem en diversos paquets d’R.
Tenint en compte que el coeficient de Cramer oscil·la entre 0 i 1 i que ens indica la força de l’associació entre dues variables categòriques, ja podem deduir que el valor de 0,0125 indica que hi ha una associació pràcticament nul·la entre les variables guerra i democràcia. Això significa que quan la variable guerra augmenta, la variable democràcia rarament augmenta en la mateixa proporció i viceversa.
Tot i que el coeficient d’associació ens ha donat un valor molt baix, això no ens diu res sobre la incertesa de les dades. És possible que, tot i la baixa associació entre democràcia i guerra, les dades ens indiquin que aquesta relació és estadísticament significativa. Quan treballem amb dues variables categòriques, la manera més habitual de reportar la incertesa de les dades és amb el test de Khi-quadrat de Pearson. La funció chisq.test(), que ja ve instal·lada per defecte amb R, ens proporcionarà aquesta informació.
Altres tests de significació.
També tenim diferents maneres de testar la significació entre dues variables categòriques. De fet, podem fer el test de Khi-Quadrat amb la funció chiSquare() del paquet Hmisc.
Pearson Chi-square Tests Response variable:dempeace_tc$war
chisquare df chisquare-df P n
dempeace_tc$democracy 2.41 1 1.41 0.1206 16268Alternativament, podem fer el test de Fisher amb la funció fisher.test(), que ens ve també de sèrie amb R.
chisq.test(dempeace_tc$war, dempeace_tc$democracy)
##
## Pearson's Chi-squared test with Yates' continuity correction
##
## data: dempeace_tc$war and dempeace_tc$democracy
## X-squared = 2.4099, df = 1, p-value = 0.1206En aquesta anàlisi, ens haurem de fixar en el p-valor (p-value), que ens indica la probabilitat que la hipòtesi nul·la sigui certa. En el nostre cas, el p-valor és del 0.12, la qual cosa significa que hi ha un 12% de possibilitats que la hipòtesi nul·la sigui certa. Com que aquest valor és superior al valor de referència que marquen les convencions estadístiques, de moment no podem afirmar que la relació entre democràcia i guerra sigui estadísticament significativa. No obstant això, més endavant continuarem explorant la qüestió de la pau democràtica amb anàlisis més sofisticades.
El paquet
sjPlot com a eina alternativa.
Hi ha paquets que ens poden fer aquestes anàlisis amb una sola funció. És el cas de sjPlot, que amb la funció tab_xtab() ens retorna un html amb la taula de contingència i els testos d’associació i significació a la part inferior.
Mostra codi
| Probabilitat de guerra |
Tipus de règim polític |
Total | |
|---|---|---|---|
| 0 | 1 | ||
| 0 | 95.5 % | 96.1 % | 95.7 % |
| 1 | 4.5 % | 3.9 % | 4.3 % |
| Total | 100 % | 100 % | 100 % |
| χ2=2.410 · df=1 · &phi=0.013 · p=0.121 | |||
Solució de l’exercici.
Fem les taules de contingència.
table(nig_ct$sex, nig_ct$account)
round(prop.table(table(nig_ct$sex, nig_ct$account), margin = 2) * 100, 1)Visualitzem les dades amb un diagrama de barres.
nig_ct |>
ggplot(aes(x = sex, fill = account)) +
geom_bar(position = "fill")Fem els testos d’associació i significació.
CramerV(nig_ct$sex, nig_ct$account)
chisq.test(nig_ct$sex, nig_ct$account)L’associació entre el sexe i tenir actituds polítiques democràtiques és dèbil (11%), però significativa (p-valor inferior a 0.05).
9.3 Diferència de mitjanes
Quan la variable independent és categòrica i la variable dependent és numèrica, la tècnica que ens permet explorar la relació bivariada és la diferència de mitjanes. En general, aquest mètode consisteix a observar l’efecte que tenen diferents tractaments sobre la variable dependent numèrica. L’efecte específic que produeix cada tractament es mesura amb la mitjana de la distribució de la variable dependent segons cada grup de la variable independent. D’aquesta manera, podrem comparar les diferents mitjanes per a cada tractament i observar si hi ha diferències entre elles.
| name | party | year | vote |
|---|---|---|---|
| Bush | Republican | 1989 | 0.12 |
| Bush | Republican | 1990 | 0.19 |
| Bush | Republican | 1991 | 0.18 |
| Bush | Republican | 1992 | 0.27 |
| Bush | Republican | 2001 | 0.28 |
| Bush | Republican | 2002 | 0.26 |
| Bush | Republican | 2003 | 0.22 |
| Bush | Republican | 2004 | 0.20 |
Per mostrar un exemple concret de com aplicar la diferència de mitjanes, examinarem un tema recurrent en la política exterior dels Estats Units: l’aïllacionisme. Aquesta doctrina, que defensa la no-intervenció en assumptes exteriors que no suposen una amenaça important per al país, ha estat una idea recurrent en la història del país. Tanmateix, podem sospitar que aquesta doctrina estarà més present en l’ideari republicà que en el demòcrata, donat que els republicans solen defensar un paper més limitat dels Estats Units en la política mundial, mentre que els demòcrates tendeixen a estar més a favor d’un paper més cooperatiu en política exterior.
Les votacions a l’Assemblea General de les Nacions Unides (AGNU) s’han utilitzat de manera recurrent per analitzar les preferències en política exterior dels Estats (Drieskens, 2010; Gartzke, 1998). Per tant, podem pensar que una administració nord-americana presidida pel Partit Republicà tendirà a adoptar una postura més aïllacionista i, per aquest motiu, a votar menys favorablement les resolucions de l’AGNU. En canvi, una administració liderada pel Partit Demòcrata tendirà a ser menys aïllacionista i votarà, en comparació, de manera més favorable a les resolucions de l’AGNU. Això vol dir que podem esperar que els Estats Units hagin votat, de mitjana, més en contra de les resolucions de l’AGNU sota presidència republicana que no pas sota presidència demòcrata (Gartzke & Kroenig, 2016; Lerner, 1994).
Per analitzar aquesta hipòtesi, hem construït un marc de dades a partir de l’objecte presidential, que es troba al paquet ggplot2 (Wickham et al., 2024), i els marcs de dades del paquet unvotes (Robinson, 2021). Un petit fragment de les dades el veiem a la taula 9.3, ubicada a la dreta de la pantalla. En la nostra anàlisi, la variable independent és categòrica, ja que pot prendre els valors republicà o demòcrata, mentre que la dependent és numèrica, ja que ens indica el percentatge de vot favorable a les resolucions de l’AGNU en un determinat any i sota el mandat d’un president determinat. La unitat d’observació, doncs, és president-any.
El paquet UN Votes.
El paquet unvotes conté tres marcs de dades amb informació sobre les votacions a l’AGNU. El marc de dades un_votes inclou registres de totes les votacions, i indica si cada Estat va votar a favor, en contra o es va abstenir. El marc de dades un_roll_calls té informació més concreta sobre cada votació, com el número de resolució i una descripció del seu contingut. El marc de dades un_roll_calls_issues separa les votacions segons la temàtica.
Un petit tutorial del paquet el trobareu a la web RforPoliticalScience.
Naturalment, el nostre primer objectiu és obtenir una estimació de la diferència entre les mitjanes dels dos grups. Per fer-ho, calcularem la mitjana de les votacions favorables a l’AGNU dels Estats Units durant els períodes presidencials republicans i demòcrates, respectivament. I després, podrem restar la mitjana obtinguda durant el període presidencial republicà de la mitjana obtinguda durant el període presidencial demòcrata. El resultat obtingut serà la diferència entre les mitjanes.
Amb aquest resultat podem concloure que durant els períodes presidencials republicans, la mitjana de votacions favorables dels Estats Units a les resolucions de l’AGNU és un 3.25% inferior que durant els períodes presidencials demòcrates. Això sembla confirmar la nostra sospita inicial, però és important tenir en compte que amb aquesta diferència encara no podem fer cap afirmació amb seguretat, fins que no haguem reportat la incertesa de les dades.
A continuació, compararem visualment la diferència entre les mitjanes de cada distribució amb un diagrama de dispersió (figura 9.2). A l’eix de les \(x\) posarem la variable independent categòrica i a l’eix de les \(y\) la variable dependent numèrica. Per visualitzar la diferència de mitjanes necessitarem tres geometries: la primera mostra totes les observacions amb punts negres, que sacsejarem amb un jitter per evitar l’overplotting. La segona geometria la demanarem amb un stat_summary(), que indicarà on es troba la mitjana i quin és el seu error típic a cada distribució, representat amb un interval de confiança del 95%3.
3 L’error típic de la mitjana ens ajuda a estimar en quins intervals es pot trobar realment la mitjana en la població segons un nivell de confiança determinat. Com menys casos tinguem i com més dispersos estiguin aquests casos al voltant de la mitjana, més gran serà l’error típic i, per tant, menys precisió tindrem per saber on es troba la mitjana. Amb un 95% de confiança, aquest interval es troba 1,96 errors típics per sobre i per sota de la mitjana.
Mostra codi.
usvotes |>
ggplot(aes(x = party, y = vote)) +
geom_point(position = position_jitter(width = 0.1, height = 0)) +
stat_summary(geom = "pointrange", fun.data = mean_se, col= "red", size = 0.8,
fun.args = list(mult = 1.96))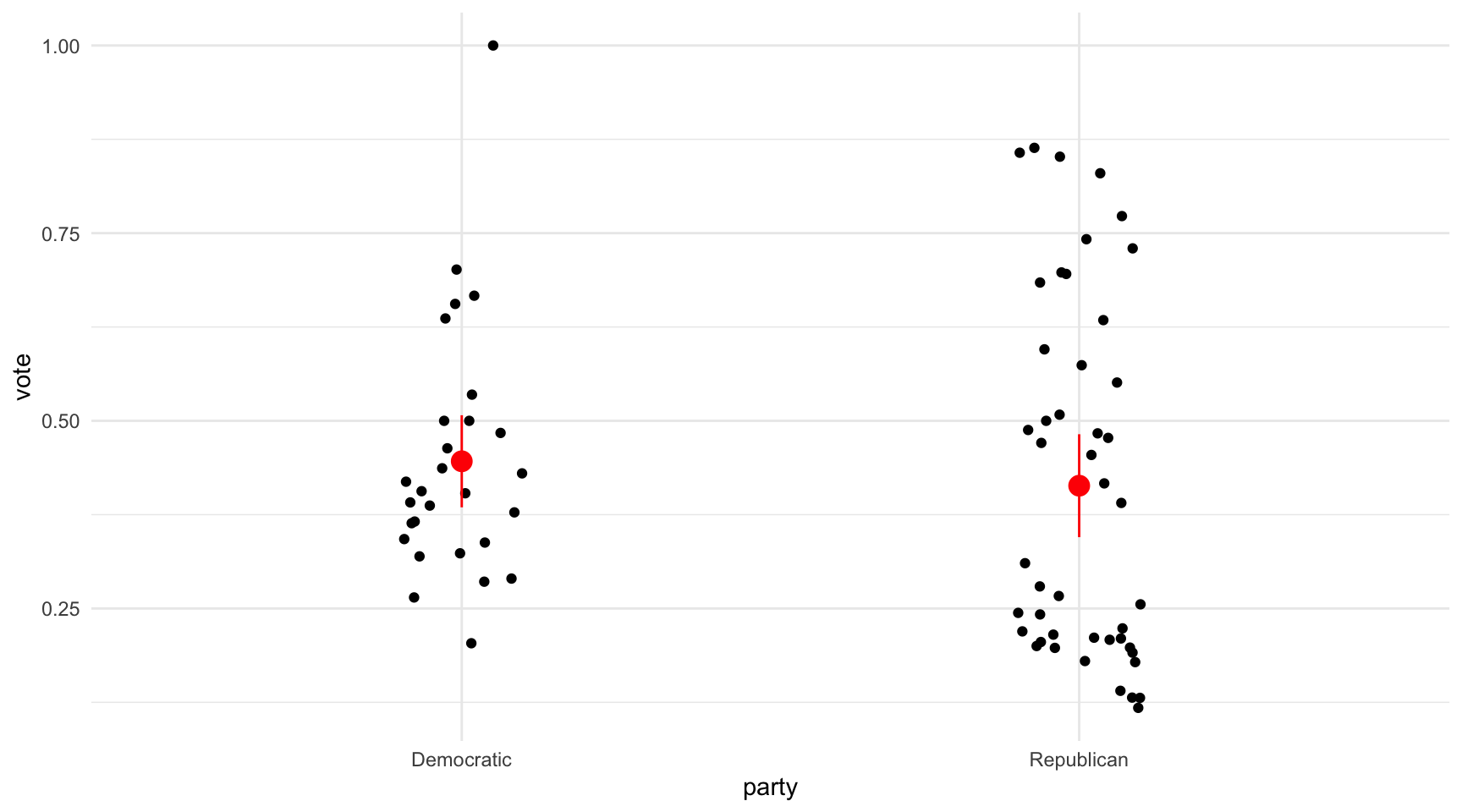
Quan tenim en compte els intervals de confiança, observem que aquesta relació no és significativa. Amb un interval de confiança del 95%, la mitjana de vot favorable entre presidències demòcrates se situaria aproximadament entre 0.38 i 0.50, mentre que la mitjana de vot favorable entre presidències republicanes se situaria aproximadament entre 0.35 i 0.48. Això vol dir que és perfectament possible que la diferència entre les mitjanes sigui 0.
Per obtenir més informació numèrica i determinar la significació estadística, utilitzarem la funció t.test(). En el primer argument posarem la variable numèrica seguit del símbol ~ i la variable categòrica i, en el segon, en canvi, indicarem el marc de dades. A l’argument alternative indicarem quina és la nostra hipòtesi alternativa: si la diferència en les mitjanes és diferent ("two.sided", argument per defecte), si la diferència de la mitjana del primer grup és inferior ("less") a la del segon o si la diferència de la mitjana del primer grup és superior ("greater") a la del segon. Com que els vectors de caràcter estan ordenats per ordre alfabètic, el primer grup fa referència als presidents demòcrates, per la qual cosa esperarem que la mitjana del primer grup sigui superior a la del segon.
t.test(vote ~ party, data = usvotes,
alternative = "greater")
##
## Welch Two Sample t-test
##
## data: vote by party
## t = 0.69315, df = 70.538, p-value = 0.2452
## alternative hypothesis: true difference in means between group Democratic and group Republican is greater than 0
## 95 percent confidence interval:
## -0.04569039 Inf
## sample estimates:
## mean in group Democratic mean in group Republican
## 0.4461102 0.4135806Ara ja tenim la foto completa de la diferència en les mitjanes. En el resultat del codi, fixem-nos en els següents paràmetres:
- La mitjana del primer grup és de 0.446 i la del segon grup és de 0.414, cosa que ja havíem calculat anteriorment.
- El p-valor (p-value) és de 0.24, la qual cosa significa que hi ha un 24% de possibilitats que la hipòtesi nul·la sigui certa. Com que aquesta xifra és superior a 0.05, no podem afirmar que la relació sigui estadísticament significativa.
Solució de l’exercici
Seleccionem Catalunya i Madrid, i guardem les dades a l’objecte m_cat_mad. Si fem un càlcul de les mitjanes, podem veure que la mitjana és de 2.59 a Catalunya i de 5.25 a Madrid.
Comparem visualment les mitjanes, amb els seus intervals de confiança.
m_cat_mad |>
ggplot(aes(x = ccaa, y = satisf)) +
geom_point(position = position_jitter(width = 0.1, height = 0.4),
alpha = 0.2) +
stat_summary(geom = "point", fun.data = mean_se, col= "red", size = 2,
fun.args = list(mult = 1.96)) +
stat_summary(geom = "errorbar", fun.data = mean_se, col = "red", width = 0.05,
fun.args = list(mult = 1.96))Fem el test-t, on partim de la base que la mitjana a la primera categoria (Catalunya) serà més petita que a la segona (Madrid).
t.test(satisf ~ ccaa, data = m_cat_mad,
alternative = "less")El p-valor és inferior a 0.05, per la qual cosa la diferència és significativa.