12 Recodificacions
12.1 Introducció
Sovint ens trobarem que volem observar o representar les dades d’una manera diferent de com ens venen codificades. Per exemple, tal com vèiem a la taula 10.8, és possible que no ens interessi saber l’edat exacta de cada líder polític, sinó simplement saber si tenen «65 anys o més» o bé «Menys de 65 anys». De la mateixa manera, ens pot interessar observar les dades d’any per dècades («1990», «2000»…) o veure si els països són «Rics» o «Pobres», en lloc de saber el valor exacte del seu PIB per càpita. A aquestes operacions en direm recodificar els valors d’una variable.
Recodificar una variable significa modificar els seus valors de manera parcial o total, fins al punt a vegades d’arribar a canviar el tipus de vector o de variable. Aquestes transformacions acostumen a anar en sentit invers a l’ordre que hem fet servir per estudiar fins ara les variables. És a dir, recodificarem una variable de ràtio per convertir-la en una variable nominal o ordinal, però difícilment podrem recodificar una variable nominal o ordinal en una de ràtio. Això es deu al fet que les variables categòriques tenen informació menys precisa que les numèriques, de manera que amb aquesta informació se’ns fa impossible transformar aquests valors a una xifra numèrica concreta. Per exemple, si un país és «Ric», no sabem quin valor numèric exacte adoptarà. En canvi, si sabem que té 63.000 dòlars per càpita, fàcilment el podem recodificar com a «Ric».
Un resum del tipus de recodificacions que podem fer el trobem a la taula 12.1. A la primera columna veiem la variable de destí a la que ho volem recodificar i a la segona columna la funció que utilitzarem per fer la recodificació.
| Destí | Funció |
|---|---|
| Binària | if_else() |
| Categòrica |
case_when(), case_match()
|
| Ordinal | factor() |
| Altres |
as.numeric(), as.character(), as.Date(), etc. |
A l’hora de recodificar variables, els vectors lògics tenen una rellevància capital. Anteriorment ja havíem comentat que els vectors lògics eren molt importants, però en el darrer apartat hem pogut comprovar que no estan explícitament associats a cap variable. Així doncs, de què ens serveix un vector lògic? Els vectors lògics són principalment eines operacionals. Això significa que ens serviran per establir les condicions que ens permetin transformar els valors d’una variable a una altra. Dit d’una altra manera, els vectors lògics se situen entremig d’una transformació. I per explotar les potencialitats dels vectors lògics necessitarem conèixer els operadors booleans.
Els operadors booleans o lògics ens permeten fer combinacions de valors de forma lògica. Per comprendre’n el funcionament, es recomana veure primer el vídeo de la dreta. En segon lloc, aplicarem els tres operadors booleans (AND, OR i NOT) al marc de dades ctr_pov, que veiem sencer a la taula 12.2 del marge lateral.
- L’operador AND (
&) retorna TRUE només si es compleixen totes les condicions. - L’operador OR (
|) retorna TRUE si es compleix una de les condicions. - L’operador NOT (
!) retorna el contrari de la condició.
| country | continent | poverty |
|---|---|---|
| Armenia | ASI | 1.9 |
| Austria | EUR | 0.7 |
| Benin | AFR | 49.6 |
| Bolivia | AME | 6.4 |
| Brazil | AME | 3.4 |
| Colombia | AME | 4.5 |
| El Salvador | AME | 1.9 |
| Ethiopia | AFR | 26.7 |
| Honduras | AME | 16.2 |
| Indonesia | ASI | 7.2 |
Combinant els operadors AND, OR i NOT podem aconseguir que R ens retorni com a TRUE i com a FALSE una combinació de diverses variables. A la figura 12.1 del lateral veiem algunes de les possibles combinacions, prenent com a variable x la rodona de l’esquerra i com a variable y la de la dreta. A continuació, posem alguns exemples de combinacions. Fixeu-vos que aquestes operacions booleanes ens retornen un vector lògic indicant quins valors compleixen (TRUE) les condicions que hem establert i quins valors no les compleixen (FALSE). Com veurem, podem aprofitar els TRUE per crear noves variables. És important comentar que es poden encadenar combinacions de tantes variables com es vulgui.
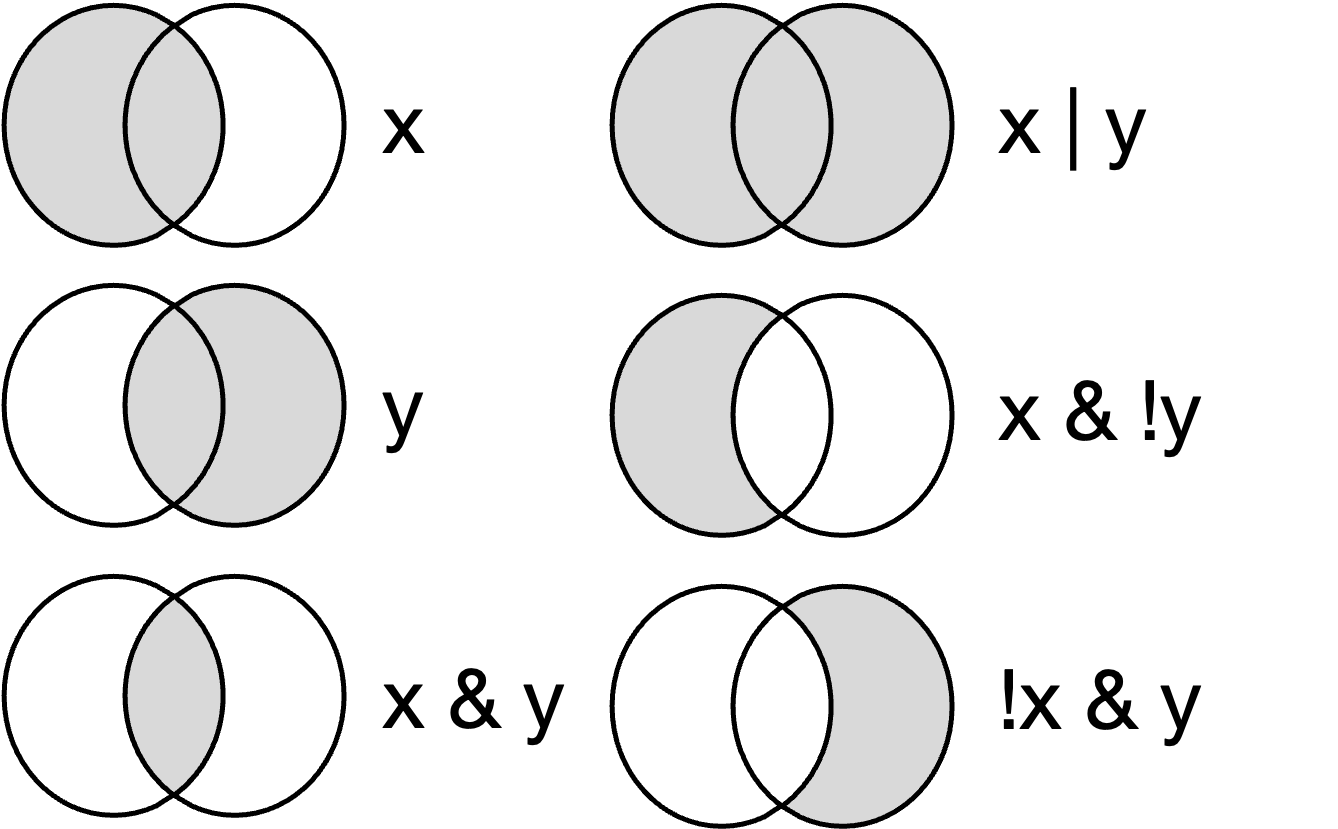
A continuació demanem quines són les observacions que són del continent africà i (AND) que tenen el llindar de pobresa per sobre els deu dòlars.
ctr_pov$continent == "AFR" & ctr_pov$poverty > 10
## [1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSECom veiem, l’operació ens diu que el tercer (Benin) i el vuitè país (Ethiopia) compleixen els requisits.
Podríem quedar-nos amb les observacions que compleixen els requisits si utilitzem els claudàtors:
ctr_pov[ctr_pov$continent == "AFR" & ctr_pov$poverty > 10, ]
## # A tibble: 2 × 3
## country continent poverty
## <chr> <chr> <dbl>
## 1 Benin AFR 49.6
## 2 Ethiopia AFR 26.7Observem, en canvi, què passa quan preguntem quines són les observacions que són del continent africà o (OR) que tenen el llindar de pobresa per sobre els deu dòlars.
ctr_pov$continent == "AFR" | ctr_pov$poverty > 10
## [1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE TRUE FALSEEn aquest cas, també la novena observació (Hondures) compleix els requisits perquè, si bé no és a l’Àfrica, sí que té un llindar de pobresa per sobre els deu dòlars.
Podríem quedar-nos amb les observacions que compleixen els requisits si utilitzem els claudàtors:
ctr_pov[ctr_pov$continent == "AFR" | ctr_pov$poverty > 10, ]
## # A tibble: 3 × 3
## country continent poverty
## <chr> <chr> <dbl>
## 1 Benin AFR 49.6
## 2 Ethiopia AFR 26.7
## 3 Honduras AME 16.2A continuació demanem quines són les observacions que no (NOT) són del continent africà i (AND) que tenen el llindar de pobresa per sobre els deu dòlars. Haurem de posar un signe d’exclamació (!) al davant del vector que nega.
!ctr_pov$continent == "AFR" & ctr_pov$poverty > 10
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSECom veiem, només un país, Hondures, compleix els requisits. També haureu observat que podríem fer la mateixa operació posant la negació (!=) en lloc del doble igual.
Podríem quedar-nos amb les observacions que compleixen els requisits si utilitzem els claudàtors:
ctr_pov[!ctr_pov$continent == "AFR" & ctr_pov$poverty > 10, ]
## # A tibble: 1 × 3
## country continent poverty
## <chr> <chr> <dbl>
## 1 Honduras AME 16.212.2 Recodificar a variable binària
Qualsevol variable es pot recodificar en binària. Una variable numèrica que inclogui, per exemple, l’alçada de diferents persones, es podria recodificar en «Alt» i «Baix» si establim un llindar determinat que separi les dues categories. També es podria fer el mateix amb una variable nominal que descrivís el color del cabell de diversos individus. Podríem crear una nova variable binària que tingués només dues categories: «Vermell» i «Altres».
Per dicotomitzar qualsevol variable, la funció més adequada és if_else() del paquet dplyr. En aquesta funció, situarem com a primer argument el resultat d’una operació lògica, com a segon argument el valor que prendrà la nova variable si el resultat de l’operació és cert, i com a tercer argument el valor que prendrà la nova variable si el resultat de l’operació és fals.
if_else(operació lògica, TRUE, FALSE)Posarem tres exemples per veure la funció if_else() en acció:
El marc de dades strings conté la variable continent, que és categòrica. Per dicotomitzar-la crearem una condició lògica que ens identifiqui les observacions que són del continent americà. Quan és cert, li direm «Americas» i, quan és fals, li direm «Others».
strings$continent <- if_else(strings$continent == "Americas", "Americas", "Others")
strings# A tibble: 8 × 5
iso3c country currency continent region
<chr> <chr> <chr> <chr> <chr>
1 CMR Cameroon CFA Franc BEAC Others Sub-Saharan Africa
2 COL Colombia Colombian Peso Americas Latin America & Ca…
3 CUB Cuba Cuban Peso Americas Latin America & Ca…
4 FRA France Euro Others Europe & Central A…
5 LSO Lesotho Loti Others Sub-Saharan Africa
6 QAT Qatar Qatari Rial Others Middle East & Nort…
7 TWN Taiwan New Taiwan Dollar Others East Asia & Pacific
8 TTO Trinidad & Tobago Trinidad & Tobago Dollar Americas Latin America & Ca…El resultat de la binarització també pot ser numèric. A continuació recodifiquem l’escala ordinal de l’índex de democràcia de The Economist en 1 si és democràcia i 0 si no ho és. En el primer argument d’if_else() hem utilitzat la funció str_detect() del paquet stringr perquè marqui com a TRUE tots aquells valors del vector ords$regime_type que continguin "Democracy" (això inclou tant Full Democracy com Flawed Democracy). Amb això creem la nova variable dem.
ords$dem <- if_else(str_detect(ords$regime_type, "Democracy"), 1, 0)
ords
## # A tibble: 10 × 4
## donor ati regime_type dem
## <chr> <ord> <ord> <dbl>
## 1 US-MCC Very Good Flawed Democracy 1
## 2 Canada-GAC Good Full Democracy 1
## 3 Germany-BMZ-GIZ Good Full Democracy 1
## 4 Korea-KOICA Good Full Democracy 1
## 5 Australia-DFAT Good Full Democracy 1
## 6 Spain-AECID Fair Flawed Democracy 1
## 7 Saudi Arabia-KSRelief Poor Authoritarian 0
## 8 Norway-MFA Poor Full Democracy 1
## 9 China-MOFCOM Very Poor Authoritarian 0
## 10 Turkey-TIKA Very Poor Hybrid Regime 0Amb els operadors booleans podem crear una classificació que ens marqui els països amb més potencial militar del marc de dades ratio a partir d’establir una sèrie de condicions lògiques en diverses variables. Indicarem que un país és "Powerful" si té una despesa militar superior al milió de dòlars, un personal militar superior a 500.000 i una població superior als setenta milions d’habitants. Per introduir correctament les magnituds, cal consultar el llibre de codis de NMC.
ratio$power <- if_else(ratio$milex > 1000000 & ratio$milper > 500 &
ratio$tpop > 70000,
"Powerful", "Powerless")
ratio
## # A tibble: 7 × 6
## country milex milper tpop cinc power
## <chr> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 USA 980000 334 131028 0.182 Powerless
## 2 UKG 7895671 394 47762 0.0997 Powerless
## 3 FRN 1023651 581 41900 0.0396 Powerless
## 4 GMY 12000000 2750 79798 0.178 Powerful
## 5 ITA 669412 581 44020 0.027 Powerless
## 6 RUS 5984123 1789 170317 0.138 Powerful
## 7 JPN 1699970 957 71380 0.0591 Powerful12.3 Recodificar a variable categòrica
Hi ha principalment dos motius pels quals voldrem recodificar una variable a categòrica. Tornant a l’exemple de l’alçada, podríem convertir diferents valors numèrics en tres categories: «Alt», «Mitjà», «Baix». O podríem recodificar una variable categòrica de forma que tingui menys categories. Per exemple, si tenim cinc religions («Cristiana», «Protestant», «Islàmica», «Budista» i «Hindú»), podem voler recodificar les categories de manera que les dues primeres passin a dir-se «Catòlica».
Per a cada cas, utilitzarem dues funcions diferents: case_when() i case_match().
12.3.1 De vector numèric a categòric
La funció adequada per recodificar una variable numèrica a categòrica és case_when(). La funció consta de tants arguments com categories vulguem crear i tots els arguments tenen la mateixa estructura, excepte l’últim. A cada argument situarem primer la condició lògica, seguit del símbol ~ i del nom que prendran tots els valors que compleixin aquesta condició. En l’últim argument indicarem .default = en lloc d’una condició lògica i el nom de la categoria que recollirà la resta d’observacions que quedin per classificar.
case_when(condició lògica ~ "C1"
condició lògica ~ "C2",
condició lògica ~ "C3",
...,
.default = "CN")És important tenir en compte que, a cada argument, case_when() va retirant els valors que ha marcat com a TRUE en els arguments anteriors. És a dir, si en el primer argument una observació ha estat marcada com a TRUE i, per tant, codificada d’una determinada manera, aquesta observació ja no es tindrà en compte en arguments posteriors encara que en compleixi la condició lògica.
Per veure en funcionament case_when(), utilitzarem la MID dataset (Palmer et al., 2020), que emmagatzema disputes militaritzades entre estats des de 1816 fins a l’actualitat. Moltes de les seves variables venen codificades numèricament, per la qual cosa haurem de consultar el llibre de codis per poder-les convertir al seu valor categòric corresponent.
En la versió reduïda de la MID dataset observem una selecció de disputes militaritzades entre díades de països. Per exemple, en la primera observació veiem la disputa entre França i Rússia que va tenir lloc el 1849.
mid_recod# A tibble: 330 × 9
disno namea nameb year outcome settlmnt fatlev hihost duration
<dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 4586 MAL INS 2008 5 3 0 3 1
2 180 RUS KOR 1905 2 1 0 4 32
3 4004 DRV CAM 1996 1 2 0 4 7
4 51 CHN PHI 1952 0 0 0 5 366
5 3448 SYR ISR 1981 5 1 1 4 207
6 1202 NIC HON 1907 1 1 6 5 313
7 4319 AZE ARM 1997 5 3 0 4 135
8 208 UKG RUS 1953 5 3 1 4 20
9 1129 SAU UKG 1934 8 4 0 4 54
10 1580 MOR SPN 1859 0 0 0 5 77
# ℹ 320 more rowsUna recodificació molt habitual és recodificar una variable temporal en dècades o en períodes històrics. Amb el codi següent, hem creat la variable period, que conté cinc categories.
mid_recod$period <- case_when(mid_recod$year < 1914 ~ "Pax Britannica",
mid_recod$year < 1946 ~ "The Thirty Years' Crisis",
mid_recod$year < 1989 ~ "Cold War",
mid_recod$year < 2003 ~ "Post-Cold War",
.default = "Present")
mid_recod# A tibble: 330 × 10
disno namea nameb year outcome settlmnt fatlev hihost duration period
<dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
1 4586 MAL INS 2008 5 3 0 3 1 Present
2 180 RUS KOR 1905 2 1 0 4 32 Pax Britanni…
3 4004 DRV CAM 1996 1 2 0 4 7 Post-Cold War
4 51 CHN PHI 1952 0 0 0 5 366 Cold War
5 3448 SYR ISR 1981 5 1 1 4 207 Cold War
6 1202 NIC HON 1907 1 1 6 5 313 Pax Britanni…
7 4319 AZE ARM 1997 5 3 0 4 135 Post-Cold War
8 208 UKG RUS 1953 5 3 1 4 20 Cold War
9 1129 SAU UKG 1934 8 4 0 4 54 The Thirty Y…
10 1580 MOR SPN 1859 0 0 0 5 77 Pax Britanni…
# ℹ 320 more rowsAlgunes variables ens arriben codificades numèricament, però són en realitat categòriques. Si consultem el llibre de codis de la base de dades (Dyadic MID 4.02), veurem que els valors numèrics de settlmnt tenen un equivalent categòric.
mid_recod$settlmnt <- case_when(mid_recod$settlmnt == 0 ~ "Missing",
mid_recod$settlmnt == 1 ~ "Negotiated",
mid_recod$settlmnt == 2 ~ "Imposed",
mid_recod$settlmnt == 3 ~ "None",
mid_recod$settlmnt == 4 ~ "Unclear",
.default = NA_character_)
mid_recod# A tibble: 330 × 10
disno namea nameb year outcome settlmnt fatlev hihost duration period
<dbl> <chr> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <chr>
1 4586 MAL INS 2008 5 None 0 3 1 Present
2 180 RUS KOR 1905 2 Negotiated 0 4 32 Pax Britan…
3 4004 DRV CAM 1996 1 Imposed 0 4 7 Post-Cold …
4 51 CHN PHI 1952 0 Missing 0 5 366 Cold War
5 3448 SYR ISR 1981 5 Negotiated 1 4 207 Cold War
6 1202 NIC HON 1907 1 Negotiated 6 5 313 Pax Britan…
7 4319 AZE ARM 1997 5 None 0 4 135 Post-Cold …
8 208 UKG RUS 1953 5 None 1 4 20 Cold War
9 1129 SAU UKG 1934 8 Unclear 0 4 54 The Thirty…
10 1580 MOR SPN 1859 0 Missing 0 5 77 Pax Britan…
# ℹ 320 more rows12.3.2 Recodificar valors categòrics
Per recodificar els valors d’una variable categòrica, la funció més adequada acostumarà a ser case_match(), on podem decidir quins valors recodificarem i quins conservaran el seu nom original. El seu funcionament és el següent:
case_match(variable,
"Valor Antic1" ~ "Valor Nou1",
"Valor Antic2" ~ "Valor Nou2",
...,
.default = "Altres")A diferència de case_when(), case_match() no permet utilitzar més d’una variable per fer les recodificacions ni fer operacions lògiques. Només podem indicar quin serà el nou valor que prendrà una categoria concreta.
Veurem en funcionament case_match() amb les dades de la WRD (Maoz & Henderson, 2013), que conté diversos conjunts de dades sobre l’adherència religiosa en el món des de 1945. Cada conjunt de dades descriu la població que practica cada religió en un nivell diferent: global, regional o estatal. A continuació veurem les dades a escala global.
En la versió reduïda de la WRD dataset observem un marc de dades amb algunes de les principals religions del món. Per exemple, en la primera observació veiem que la religió Cristianisme protestant (chrstprot) tenia 160.887.585 fidels el 1945.
relig_recod# A tibble: 32 × 3
year religion value
<dbl> <chr> <dbl>
1 1945 chrstprot 160887585
2 1945 chrstcat 391332035
3 1945 chrstang 36955033
4 1945 jdcons 1426350
5 1945 judref 1929388
6 1945 islmsun 49050320
7 1945 islmshi 19436742
8 1945 islmibd 0
9 1945 islmnat 0
10 1945 islmalw 0
# ℹ 22 more rowsPodem recodificar les religions per crear una nova categoria que englobi les religions majors. Així, les tres religions cristianes que apareixen en la base de dades les podríem codificar com a «Christianism». En primer lloc, mirarem quantes categories tenim.
unique(relig_recod$religion) [1] "chrstprot" "chrstcat" "chrstang" "jdcons" "judref"
[6] "islmsun" "islmshi" "islmibd" "islmnat" "islmalw"
[11] "islmahm" "budmah" "nonrelig" "sumrelig" "pop"
[16] "worldpop" "chrstprotpct" "chrstcatpct" "chrstangpct" "judconspct"
[21] "judrefpct" "islmsunpct" "islmshipct" "islmibdpct" "islmnatpct"
[26] "islmalwpct" "islmahmpct" "budmahpct" "nonreligpct" "sumreligpct"
[31] "ptctotal" "version" La funció case_match() és efectiva quan volem recodificar alguns valors. Per exemple, si volem canviar a Christianism les categories chrstprot, chrstcat i chrstang, aquesta funció ens ho permet fer amb poc codi. Primer indiquem el vector que volem transformar i seguit de cada una de les transformacions. Si a l’argument .default indiquem el nom propi de la variable, ens mantindrà els valors que no hàgim recodificat:
relig_recod$mr <- case_match(relig_recod$religion,
"chrstprot" ~ "Christianism",
"chrstcat" ~ "Christianism",
"chrstang" ~ "Christianism",
.default = relig_recod$religion)
relig_recod# A tibble: 32 × 4
year religion value mr
<dbl> <chr> <dbl> <chr>
1 1945 chrstprot 160887585 Christianism
2 1945 chrstcat 391332035 Christianism
3 1945 chrstang 36955033 Christianism
4 1945 jdcons 1426350 jdcons
5 1945 judref 1929388 judref
6 1945 islmsun 49050320 islmsun
7 1945 islmshi 19436742 islmshi
8 1945 islmibd 0 islmibd
9 1945 islmnat 0 islmnat
10 1945 islmalw 0 islmalw
# ℹ 22 more rowsEl problema de case_match() és que hem de recodificar els valors un per un. Per això, sovint, case_when() ens permet trobar dreceres quan hem de recodificar molts valors, com en el cas que indiquem a continuació. Aquí hem combinat les condicions lògiques amb str_detect(). Com que judaisme serà difícil d’especificar, hem utilitzat l’expressió regular ^j, que indica que ha de localitzar la lletra «j» a principi de paraula.
relig_recod$mr <- case_when(str_detect(relig_recod$religion, "chrst") ~ "Christianism",
str_detect(relig_recod$religion, "islm") ~ "Islamism",
str_detect(relig_recod$religion, "bud") ~ "Buddism",
str_detect(relig_recod$religion, "^j") ~ "Judaism",
.default = "Other/NA")
relig_recod# A tibble: 32 × 4
year religion value mr
<dbl> <chr> <dbl> <chr>
1 1945 chrstprot 160887585 Christianism
2 1945 chrstcat 391332035 Christianism
3 1945 chrstang 36955033 Christianism
4 1945 jdcons 1426350 Judaism
5 1945 judref 1929388 Judaism
6 1945 islmsun 49050320 Islamism
7 1945 islmshi 19436742 Islamism
8 1945 islmibd 0 Islamism
9 1945 islmnat 0 Islamism
10 1945 islmalw 0 Islamism
# ℹ 22 more rows12.4 A variable ordinal
Com s’ha explicat anteriorment, les variables ordinals rarament ens vindran directament codificades com a factor ordinal. El més habitual serà que estiguin codificades com a vector de caràcter o com a vector numèric i que les hàgim de recodificar. En aquest apartat veurem com recodificar-les amb la funció factor() amb un exemple de cada cas.
factor(wb$income_group,
ordered = TRUE,
[levels o labels = ...])Com es pot observar, en el tercer argument s’ha marcat entre claudàtors levels o labels. Això significa que en funció de la recodificació que busquem farem servir levels, labels o tots dos arguments. L’argument levels està pensat per definir l’ordre dels nivells, de menor a major, mentre que l’argument labels està pensat per definir les etiquetes de cada nivell.
12.4.1 De vector de caràcter a ordinal
Una de les variables ordinals més emprades en l’àmbit internacional és la classificació del Banc Mundial segons grup de renda dels països. Aquesta classificació està formada per quatre categories (ingrés baix, mitjà-baix, mitjà-alt, alt), que observem a la variable income_group. Les categories són de gran importància per a moltes economies en desenvolupament, ja que només les d’ingrés més baix podran accedir a determinats préstecs del banc. Altres organitzacions internacionals també fan servir aquestes categories. El Sistema Generalitzat de Preferències de la Unió Europea es basa en la classificació del Banc Mundial per determinar quins països podran vendre els seus productes al mercat europeu sense haver de pagar aranzels.
En la versió reduïda de la base de dades del Banc Mundial, observem que els països estan classificats per regió, grup de renda i tipus de finançament (lending_category). Observem com la variable income_group està codificada com a vector de caràcter.
wb_recod# A tibble: 30 × 5
economy code region income_group lending_category
<chr> <chr> <chr> <chr> <chr>
1 Bahamas, The BHS Latin America & Carib… High income ..
2 Lithuania LTU Europe & Central Asia High income ..
3 Samoa WSM East Asia & Pacific Upper middl… IDA
4 Thailand THA East Asia & Pacific Upper middl… IBRD
5 Pakistan PAK South Asia Lower middl… Blend
6 Nepal NPL South Asia Low income IDA
7 Iran, Islamic Rep. IRN Middle East & North A… Upper middl… IBRD
8 Australia AUS East Asia & Pacific High income ..
9 Bolivia BOL Latin America & Carib… Lower middl… IBRD
10 Albania ALB Europe & Central Asia Upper middl… IBRD
# ℹ 20 more rowsPer recodificar el vector com a factor ordinal, primer haurem de saber quines són les categories de la variable. Observem que, efectivament, income_group és una variable amb quatre categories.
unique(wb_recod$income_group)[1] "High income" "Upper middle income" "Lower middle income"
[4] "Low income" Amb la funció factor() passem la variable a factor. En el primer argument indiquem el nom del vector, en el segon argument ordered = TRUE indiquem que volem ordenar les seves categories i en l’argument levels indiquem, de menor a major, l’ordre de les categories.
Podem comprovar que R ens ha codificat la variable correctament de diverses maneres:
- Amb la funció
class()ens apareixerà «ordered» «factor». - Imprimint el marc de dades ens apareixerà
<ord>a sobre de la columna en qüestió. - Amb la funció
unique()veurem l’ordre dels nivells. - Imprimint el vector també veurem l’ordre dels nivells.
wb_recod$income_group[1:2][1] High income High income
4 Levels: Low income < Lower middle income < ... < High income12.5 De vector numèric a ordinal
La majoria de variables ordinals d’enquesta ens arribaran codificades en vectors numèrics, com és el cas de la majoria de variables de l’enquesta WVS. Com que les categories ordinals estan codificades numèricament, per recodificar la variable amb els seus valors categòrics haurem de consultar necessàriament el llibre de codis de la base de dades.
A la versió reduïda de la setena onada de la WVS, observem que els entrevistats, de diversos països, responen a diverses preguntes que són codificades numèricament. Si ens fixem en el llibre de codis de la base de dades, veurem que la variable Q4 pregunta per la importància que té la política per a la persona enquestada. Aquesta pregunta es mesura amb una escala ordinal de quatre valors: ‘Molt important’ correspon al valor numèric 1, ‘Més aviat important’ al valor 2, ‘No gaire important’ al 3 i ‘Gens important’ al 4.
wvs_recod# A tibble: 1,000 × 12
A_WAVE C_COW_ALPHA C_COW_NUM A_YEAR Q1 Q2 Q3 Q4 Q5 Q6 Q7
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 7 MAL 820 2018 1 2 1 1 4 2 1
2 7 GMY 255 2018 2 1 2 3 1 4 1
3 7 KZK 705 2018 2 2 2 4 2 4 1
4 7 RUS 365 2017 1 1 2 3 1 3 1
5 7 KZK 705 2018 1 2 2 4 1 1 2
6 7 SRB 345 2017 1 1 1 1 1 1 1
7 7 AUL 900 2018 1 1 1 1 1 4 1
8 7 MEX 70 2018 1 2 1 4 1 1 1
9 7 DRV 816 2020 1 2 2 2 1 1 1
10 7 GRC 350 2017 1 1 1 4 1 1 1
# ℹ 990 more rows
# ℹ 1 more variable: Q8 <dbl>Abans de fer la conversió, haurem d’assegurar-nos que aquestes quatre categories estiguin presents a la variable.
unique(wvs_recod$Q4)[1] 1 3 4 2 NAVeiem que els quatre valors són presents, com també el valor NA. El valor NA respon a les sigles en anglès Not Available (no disponible).
Recodificar aquesta variable concreta és un xic contraintuïtiu, ja que el nombre 4 correspon al valor més baix de l’escala ordinal (Gens important), mentre que el valor 1 correspon al valor més alt (Molt important). Això vol dir que haurem d’indicar en algun moment l’ordre correcte dels valors de l’escala. Com que inicialment estem tractant amb un vector numèric, el procediment més senzill serà capgirar l’escala amb una simple resta en el primer argument. En el segon argument indicarem quines són les etiquetes correctes amb labels i finalment indicarem que és un factor ordinal en el tercer argument.
Una segona opció, que dona el mateix resultat que l’anterior, és la següent. En el primer argument indiquem el vector numèric en qüestió. En el segon argument levels indiquem l’ordre correcte dels nivells, de menor a major. Amb labels indiquem en el tercer argument el nom de les etiquetes que correspondrà a cada nivell i finalment en el quart argument indicarem que és un factor ordinal.
L’argument levels està pensat per definir l’ordre dels nivells, de menor a major, mentre que l’argument labels està pensat per definir les etiquetes de cada nivell.
Podem comprovar que R ens ha codificat la variable correctament de diverses maneres:
- Amb la funció
class()ens apareixerà «ordered» «factor». - Imprimint el marc de dades ens apareixerà
<ord>a sobre de la columna en qüestió). - Amb la funció
unique()veurem l’ordre dels nivells. - Imprimint el vector també veurem l’ordre dels nivells.
wvs_recod$Q4[1:3][1] Very important Not very important Not at all important
4 Levels: Not at all important < Not very important < ... < Very importantSi ens fixem en el llibre de codis de la WVS, veurem que moltíssimes variables segueixen la mateixa escala ordinal; sense anar més lluny, les variables de la Q1 a la Q6. Recodificar-les una per una pot ser una feinada. Per sort, més endavant veurem que no cal que fem aquest procediment, sinó que amb diverses funcions del paquet dplyr podem recodificar totes les variables de cop amb el mateix codi. A la taula 12.3 en veiem l’exemple i el resultat:
| A_WAVE | C_COW_ALPHA | C_COW_NUM | A_YEAR | Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 7 | MAL | 820 | 2018 | Very important | Rather important | Very important | Very important | Not at all important | Rather important | 1 | 1 |
| 7 | GMY | 255 | 2018 | Rather important | Very important | Rather important | Not very important | Very important | Not at all important | 1 | 1 |
| 7 | KZK | 705 | 2018 | Rather important | Rather important | Rather important | Not at all important | Rather important | Not at all important | 1 | 1 |
| 7 | RUS | 365 | 2017 | Very important | Very important | Rather important | Not very important | Very important | Not very important | 1 | 2 |
| 7 | KZK | 705 | 2018 | Very important | Rather important | Rather important | Not at all important | Very important | Very important | 2 | 2 |
| 7 | SRB | 345 | 2017 | Very important | Very important | Very important | Very important | Very important | Very important | 1 | 2 |
| 7 | AUL | 900 | 2018 | Very important | Very important | Very important | Very important | Very important | Not at all important | 1 | 1 |
| 7 | MEX | 70 | 2018 | Very important | Rather important | Very important | Not at all important | Very important | Very important | 1 | 2 |
12.6 Funcions genèriques
També tenim funcions de recodificació genèriques que permeten canviar la classe de vector.
Normalment, utilitzarem aquestes funcions quan observem que alguna variable no té la classe de vector que li pertocaria. Per exemple, suposem que quan explorem el marc de dades polity ens adonem que tots els vectors són de caràcter.
# A tibble: 9 × 3
country year polity2
<chr> <chr> <chr>
1 United States 1776 0
2 Bolivia 1825 -3
3 Australia 1901 10
4 Azerbaijan 1991 -3
5 USSR 1922 -7
6 Timor Leste 2002 6
7 Eritrea 1993 -6
8 Qatar 1971 -10
9 Gambia 1965 8 En aquest cas, haurem de recodificar les dues últimes variables perquè tinguin el vector numèric.
polity$year <- as.numeric(polity$year)
polity$polity2 <- as.numeric(polity$polity2)